 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ML Supply Chain in the Era of Software 2.0: Lessons Learned from Hugging Face
Feb 06, 2025The last decade has seen widespread adoption of Machine Learning (ML) components in software systems. This has occurred in nearly every domain, from natural language processing to computer vision. These ML components range from relatively simple neural networks to complex and resource-intensive large language models. However, despite this widespread adoption, little is known about the supply chain relationships that produce these models, which can have implications for compliance and security. In this work, we conduct an extensive analysis of 760,460 models and 175,000 datasets mined from the popular model-sharing site Hugging Face. First, we evaluate the current state of documentation in the Hugging Face supply chain, report real-world examples of shortcomings, and offer actionable suggestions for improvement. Next, we analyze the underlying structure of the extant supply chain. Finally, we explore the current licensing landscape against what was reported in prior work and discuss the unique challenges posed in this domain. Our results motivate multiple research avenues, including the need for better license management for ML models/datasets, better support for model documentation, and automated inconsistency checking and validation. We make our research infrastructure and dataset available to facilitate future research.
Developer Perspectives on Licensing and Copyright Issues Arising from Generative AI for Coding
Nov 16, 2024



Generative AI (GenAI) tools have already started to transform software development practices. Despite their utility in tasks such as writing code, the use of these tools raises important legal questions and potential risks, particularly those associated with copyright law. In the midst of this uncertainty, this paper presents a study jointly conducted by software engineering and legal researchers that surveyed 574 GitHub developers who use GenAI tools for development activities. The survey and follow-up interviews probed the developers' opinions on emerging legal issues as well as their perception of copyrightability, ownership of generated code, and related considerations. We also investigate potential developer misconceptions, the impact of GenAI on developers' work, and developers' awareness of licensing/copyright risks. Qualitative and quantitative analysis showed that developers' opinions on copyright issues vary broadly and that many developers are aware of the nuances these legal questions involve. We provide: (1) a survey of 574 developers on the licensing and copyright aspects of GenAI for coding, (2) a snapshot of practitioners' views at a time when GenAI and perceptions of it are rapidly evolving, and (3) an analysis of developers' views, yielding insights and recommendations that can inform future regulatory decisions in this evolving field.
Towards Automatically Addressing Self-Admitted Technical Debt: How Far Are We?
Aug 17, 2023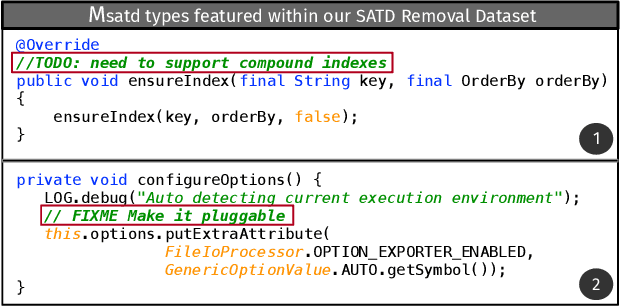

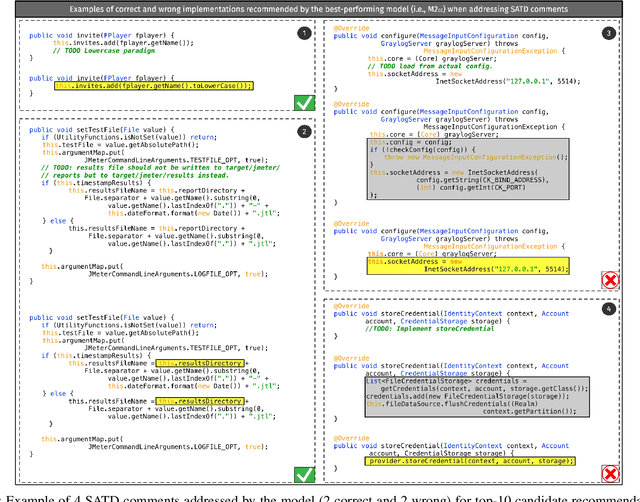
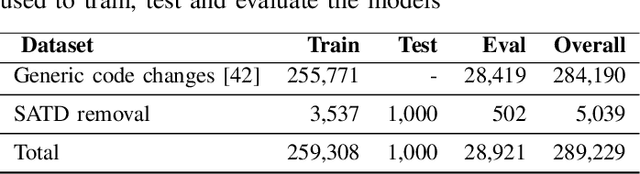
Upon evolving their software, organizations and individual developers have to spend a substantial effort to pay back technical debt, i.e., the fact that software is released in a shape not as good as it should be, e.g., in terms of functionality, reliability, or maintainability. This paper empirically investigates the extent to which technical debt can be automatically paid back by neural-based generative models, and in particular models exploiting different strategies for pre-training and fine-tuning. We start by extracting a dateset of 5,039 Self-Admitted Technical Debt (SATD) removals from 595 open-source projects. SATD refers to technical debt instances documented (e.g., via code comments) by developers. We use this dataset to experiment with seven different generative deep learning (DL) model configurations. Specifically, we compare transformers pre-trained and fine-tuned with different combinations of training objectives, including the fixing of generic code changes, SATD removals, and SATD-comment prompt tuning. Also, we investigate the applicability in this context of a recently-available Large Language Model (LLM)-based chat bot. Results of our study indicate that the automated repayment of SATD is a challenging task, with the best model we experimented with able to automatically fix ~2% to 8% of test instances, depending on the number of attempts it is allowed to make. Given the limited size of the fine-tuning dataset (~5k instances), the model's pre-training plays a fundamental role in boosting performance. Also, the ability to remove SATD steadily drops if the comment documenting the SATD is not provided as input to the model. Finally, we found general-purpose LLMs to not be a competitive approach for addressing SATD.
On the Need of Removing Last Releases of Data When Using or Validating Defect Prediction Models
Mar 31, 2020



To develop and train defect prediction models, researchers rely on datasets in which a defect is attributed to an artifact, e.g., a class of a given release. However, the creation of such datasets is far from being perfect. It can happen that a defect is discovered several releases after its introduction: this phenomenon has been called "dormant defects". This means that, if we observe today the status of a class in its current version, it can be considered as defect-free while this is not the case. We call "snoring" the noise consisting of such classes, affected by dormant defects only. We conjecture that the presence of snoring negatively impacts the classifiers' accuracy and their evaluation. Moreover, earlier releases likely contain more snoring classes than older releases, thus, removing the most recent releases from a dataset could reduce the snoring effect and improve the accuracy of classifiers. In this paper we investigate the impact of the snoring noise on classifiers' accuracy and their evaluation, and the effectiveness of a possible countermeasure consisting in removing the last releases of data. We analyze the accuracy of 15 machine learning defect prediction classifiers on data from more than 4,000 bugs and 600 releases of 19 open source projects from the Apache ecosystem. Our results show that, on average across projects: (i) the presence of snoring decreases the recall of defect prediction classifiers; (ii) evaluations affected by snoring are likely unable to identify the best classifiers, and (iii) removing data from recent releases helps to significantly improve the accuracy of the classifiers. On summary, this paper provides insights on how to create a software defect dataset by mitigating the effect of snoring.
DeepMutation: A Neural Mutation Tool
Feb 13, 2020

Mutation testing can be used to assess the fault-detection capabilities of a given test suite. To this aim, two characteristics of mutation testing frameworks are of paramount importance: (i) they should generate mutants that are representative of real faults; and (ii) they should provide a complete tool chain able to automatically generate, inject, and test the mutants. To address the first point, we recently proposed an approach using a Recurrent Neural Network Encoder-Decoder architecture to learn mutants from ~787k faults mined from real programs. The empirical evaluation of this approach confirmed its ability to generate mutants representative of real faults. In this paper, we address the second point, presenting DeepMutation, a tool wrapping our deep learning model into a fully automated tool chain able to generate, inject, and test mutants learned from real faults. Video: https://sites.google.com/view/learning-mutation/deepmutation