 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatically Addressing Self-Admitted Technical Debt: How Far Are We?
Paper and Code
Aug 17, 2023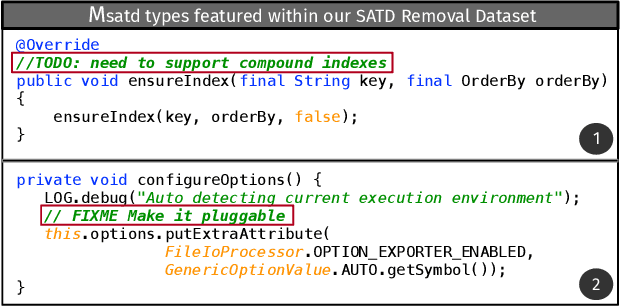

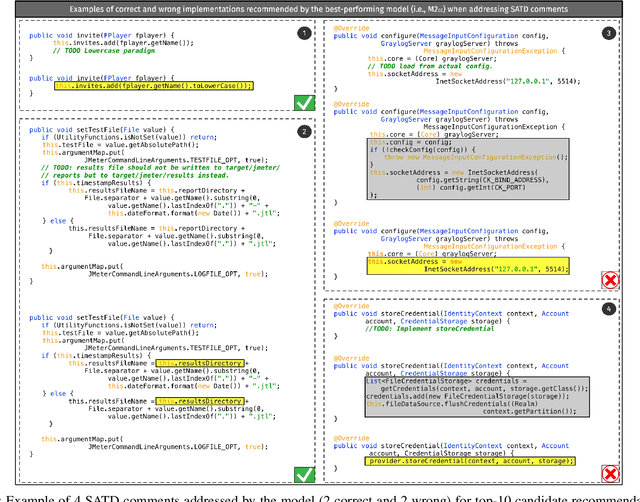
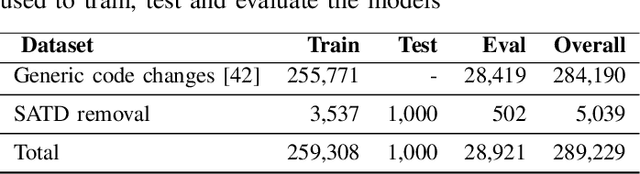
Upon evolving their software, organizations and individual developers have to spend a substantial effort to pay back technical debt, i.e., the fact that software is released in a shape not as good as it should be, e.g., in terms of functionality, reliability, or maintainability. This paper empirically investigates the extent to which technical debt can be automatically paid back by neural-based generative models, and in particular models exploiting different strategies for pre-training and fine-tuning. We start by extracting a dateset of 5,039 Self-Admitted Technical Debt (SATD) removals from 595 open-source projects. SATD refers to technical debt instances documented (e.g., via code comments) by developers. We use this dataset to experiment with seven different generative deep learning (DL) model configurations. Specifically, we compare transformers pre-trained and fine-tuned with different combinations of training objectives, including the fixing of generic code changes, SATD removals, and SATD-comment prompt tuning. Also, we investigate the applicability in this context of a recently-available Large Language Model (LLM)-based chat bot. Results of our study indicate that the automated repayment of SATD is a challenging task, with the best model we experimented with able to automatically fix ~2% to 8% of test instances, depending on the number of attempts it is allowed to make. Given the limited size of the fine-tuning dataset (~5k instances), the model's pre-training plays a fundamental role in boosting performance. Also, the ability to remove SATD steadily drops if the comment documenting the SATD is not provided as input to the model. Finally, we found general-purpose LLMs to not be a competitive approach for addressing SATD.