 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Reward Models for Guiding Code Review Comment Generation
Jun 04, 2025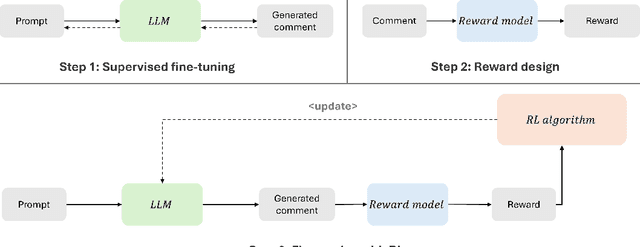
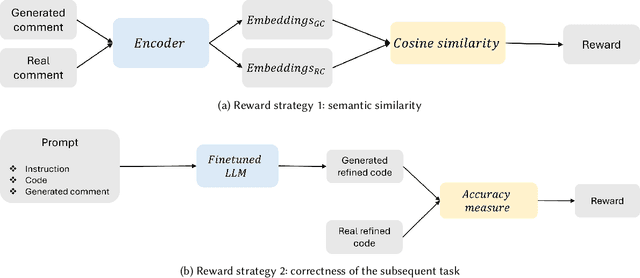
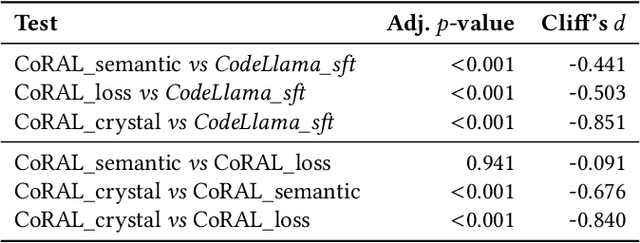
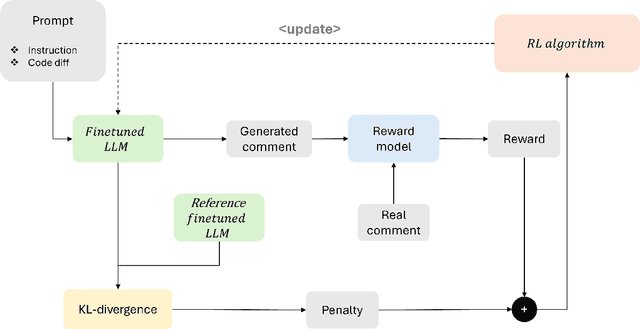
Code review is a crucial component of modern software development, involving the evaluation of code quality, providing feedback on potential issues, and refining the code to address identified problems. Despite these benefits, code review can be rather time consuming, and influenced by subjectivity and human factors. For these reasons, techniques to (partially) automate the code review process have been proposed in the literature. Among those, the ones exploiting deep learning (DL) are able to tackle the generative aspect of code review, by commenting on a given code as a human reviewer would do (i.e., comment generation task) or by automatically implementing code changes required to address a reviewer's comment (i.e., code refinement task). In this paper, we introduce CoRAL, a deep learning framework automating review comment generation by exploiting reinforcement learning with a reward mechanism considering both the semantics of the generated comments as well as their usefulness as input for other models automating the code refinement task. The core idea is that if the DL model generates comments that are semantically similar to the expected ones or can be successfully implemented by a second model specialized in code refinement, these comments are likely to be meaningful and useful, thus deserving a high reward in the reinforcement learning framework. We present both quantitative and qualitative comparisons between the comments generated by CoRAL and those produced by the latest baseline techniques, highlighting the effectiveness and superiority of our approach.
Investigating Execution-Aware Language Models for Code Optimization
Mar 11, 2025



Code optimization is the process of enhancing code efficiency, while preserving its intended functionality. This process often requires a deep understanding of the code execution behavior at run-time to identify and address inefficiencies effectively. Recent studies have shown that language models can play a significant role in automating code optimization. However, these models may have insufficient knowledge of how code execute at run-time. To address this limitation, researchers have developed strategies that integrate code execution information into language models. These strategies have shown promise, enhancing the effectiveness of language models in various software engineering tasks. However, despite the close relationship between code execution behavior and efficiency, the specific impact of these strategies on code optimization remains largely unexplored. This study investigates how incorporating code execution information into language models affects their ability to optimize code. Specifically, we apply three different training strategies to incorporate four code execution aspects -- line executions, line coverage, branch coverage, and variable states -- into CodeT5+, a well-known language model for code. Our results indicate that execution-aware models provide limited benefits compared to the standard CodeT5+ model in optimizing code.
Towards Automatically Addressing Self-Admitted Technical Debt: How Far Are We?
Aug 17, 2023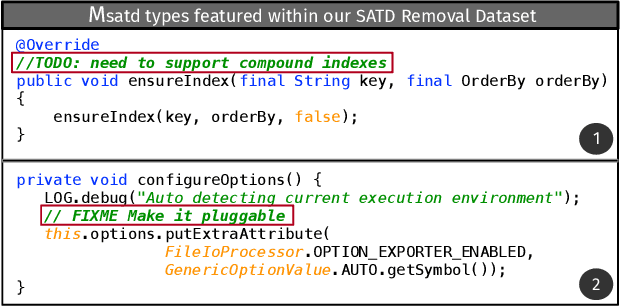

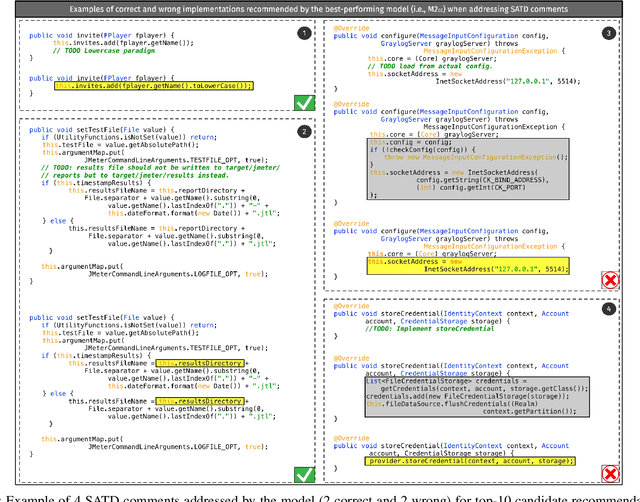
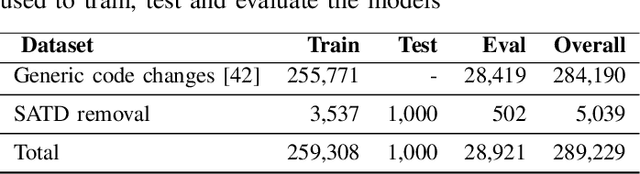
Upon evolving their software, organizations and individual developers have to spend a substantial effort to pay back technical debt, i.e., the fact that software is released in a shape not as good as it should be, e.g., in terms of functionality, reliability, or maintainability. This paper empirically investigates the extent to which technical debt can be automatically paid back by neural-based generative models, and in particular models exploiting different strategies for pre-training and fine-tuning. We start by extracting a dateset of 5,039 Self-Admitted Technical Debt (SATD) removals from 595 open-source projects. SATD refers to technical debt instances documented (e.g., via code comments) by developers. We use this dataset to experiment with seven different generative deep learning (DL) model configurations. Specifically, we compare transformers pre-trained and fine-tuned with different combinations of training objectives, including the fixing of generic code changes, SATD removals, and SATD-comment prompt tuning. Also, we investigate the applicability in this context of a recently-available Large Language Model (LLM)-based chat bot. Results of our study indicate that the automated repayment of SATD is a challenging task, with the best model we experimented with able to automatically fix ~2% to 8% of test instances, depending on the number of attempts it is allowed to make. Given the limited size of the fine-tuning dataset (~5k instances), the model's pre-training plays a fundamental role in boosting performance. Also, the ability to remove SATD steadily drops if the comment documenting the SATD is not provided as input to the model. Finally, we found general-purpose LLMs to not be a competitive approach for addressing SATD.
Automating Code-Related Tasks Through Transformers: The Impact of Pre-training
Feb 08, 2023



Transformers have gained popularity in the software engineering (SE) literature. These deep learning models are usually pre-trained through a self-supervised objective, meant to provide the model with basic knowledge about a language of interest (e.g., Java). A classic pre-training objective is the masked language model (MLM), in which a percentage of tokens from the input (e.g., a Java method) is masked, with the model in charge of predicting them. Once pre-trained, the model is then fine-tuned to support the specific downstream task of interest (e.g., code summarization). While there is evidence suggesting the boost in performance provided by pre-training, little is known about the impact of the specific pre-training objective(s) used. Indeed, MLM is just one of the possible pre-training objectives and recent work from the natural language processing field suggest that pre-training objectives tailored for the specific downstream task of interest may substantially boost the model's performance. In this study, we focus on the impact of pre-training objectives on the performance of transformers when automating code-related tasks. We start with a systematic literature review aimed at identifying the pre-training objectives used in SE. Then, we pre-train 32 transformers using both (i) generic pre-training objectives usually adopted in SE; and (ii) pre-training objectives tailored to specific code-related tasks subject of our experimentation, namely bug-fixing, code summarization, and code completion. We also compare the pre-trained models with non pre-trained ones. Our results show that: (i) pre-training helps in boosting performance only if the amount of fine-tuning data available is small; (ii) the MLM objective is usually sufficient to maximize the prediction performance of the model, even when comparing it with pre-training objectives specialized for the downstream task at hand.
DeepMutation: A Neural Mutation Tool
Feb 13, 2020

Mutation testing can be used to assess the fault-detection capabilities of a given test suite. To this aim, two characteristics of mutation testing frameworks are of paramount importance: (i) they should generate mutants that are representative of real faults; and (ii) they should provide a complete tool chain able to automatically generate, inject, and test the mutants. To address the first point, we recently proposed an approach using a Recurrent Neural Network Encoder-Decoder architecture to learn mutants from ~787k faults mined from real programs. The empirical evaluation of this approach confirmed its ability to generate mutants representative of real faults. In this paper, we address the second point, presenting DeepMutation, a tool wrapping our deep learning model into a fully automated tool chain able to generate, inject, and test mutants learned from real faults. Video: https://sites.google.com/view/learning-mutation/deepmutation
Taxonomy of Real Faults in Deep Learning Systems
Nov 07, 2019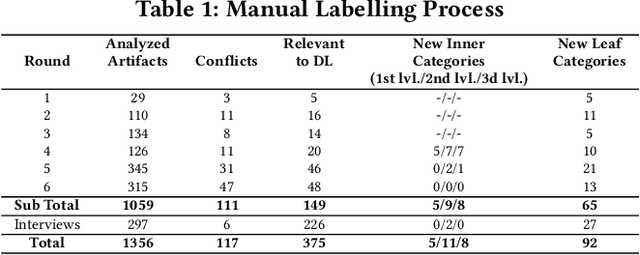
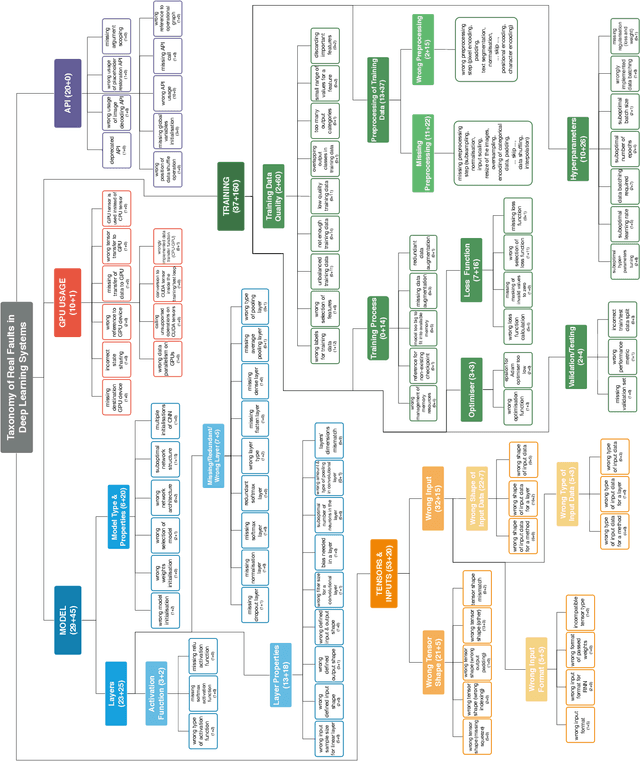
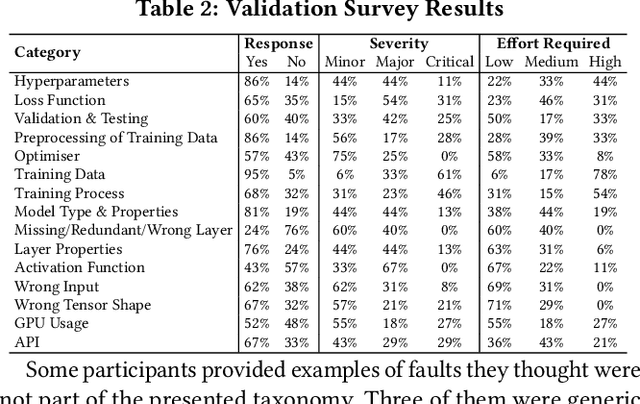

The growing application of deep neural networks in safety-critical domains makes the analysis of faults that occur in such systems of enormous importance. In this paper we introduce a large taxonomy of faults in deep learning (DL) systems. We have manually analysed 1059 artefacts gathered from GitHub commits and issues of projects that use the most popular DL frameworks (TensorFlow, Keras and PyTorch) and from related Stack Overflow posts. Structured interviews with 20 researchers and practitioners describing the problems they have encountered in their experience have enriched our taxonomy with a variety of additional faults that did not emerge from the other two sources. Our final taxonomy was validated with a survey involving an additional set of 21 developers, confirming that almost all fault categories (13/15) were experienced by at least 50% of the survey participants.
On Learning Meaningful Code Changes via Neural Machine Translation
Jan 25, 2019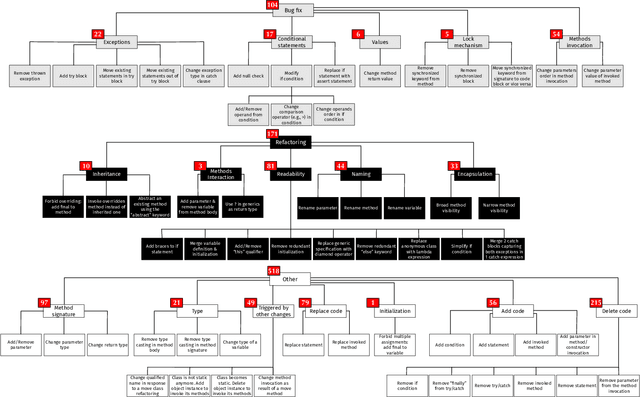
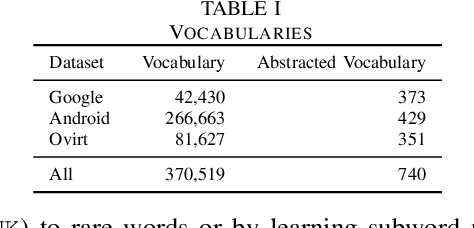
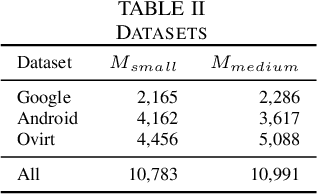
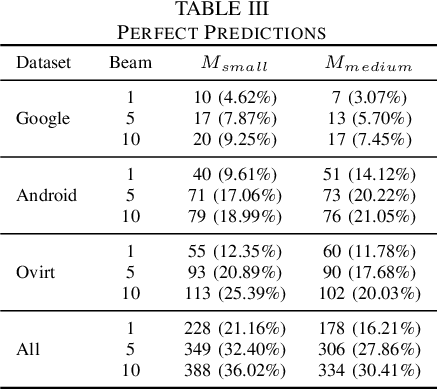
Recent years have seen the rise of Deep Learning (DL) techniques applied to source code. Researchers have exploited DL to automate several development and maintenance tasks, such as writing commit messages, generating comments and detecting vulnerabilities among others. One of the long lasting dreams of applying DL to source code is the possibility to automate non-trivial coding activities. While some steps in this direction have been taken (e.g., learning how to fix bugs), there is still a glaring lack of empirical evidence on the types of code changes that can be learned and automatically applied by DL. Our goal is to make this first important step by quantitatively and qualitatively investigating the ability of a Neural Machine Translation (NMT) model to learn how to automatically apply code changes implemented by developers during pull requests. We train and experiment with the NMT model on a set of 236k pairs of code components before and after the implementation of the changes provided in the pull requests. We show that, when applied in a narrow enough context (i.e., small/medium-sized pairs of methods before/after the pull request changes), NMT can automatically replicate the changes implemented by developers during pull requests in up to 36% of the cases. Moreover, our qualitative analysis shows that the model is capable of learning and replicating a wide variety of meaningful code changes, especially refactorings and bug-fixing activities. Our results pave the way for novel research in the area of DL on code, such as the automatic learning and applications of refactoring.