 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperNet-Adaptation for Diffusion-Based Test Case Generation
Jan 21, 2026The increasing deployment of deep learning systems requires systematic evaluation of their reliability in real-world scenarios. Traditional gradient-based adversarial attacks introduce small perturbations that rarely correspond to realistic failures and mainly assess robustness rather than functional behavior. Generative test generation methods offer an alternative but are often limited to simple datasets or constrained input domains. Although diffusion models enable high-fidelity image synthesis, their computational cost and limited controllability restrict their applicability to large-scale testing. We present HyNeA, a generative testing method that enables direct and efficient control over diffusion-based generation. HyNeA provides dataset-free controllability through hypernetworks, allowing targeted manipulation of the generative process without relying on architecture-specific conditioning mechanisms or dataset-driven adaptations such as fine-tuning. HyNeA employs a distinct training strategy that supports instance-level tuning to identify failure-inducing test cases without requiring datasets that explicitly contain examples of similar failures. This approach enables the targeted generation of realistic failure cases at substantially lower computational cost than search-based methods. Experimental results show that HyNeA improves controllability and test diversity compared to existing generative test generators and generalizes to domains where failure-labeled training data is unavailable.
Benchmarking Contextual Understanding for In-Car Conversational Systems
Dec 12, 2025
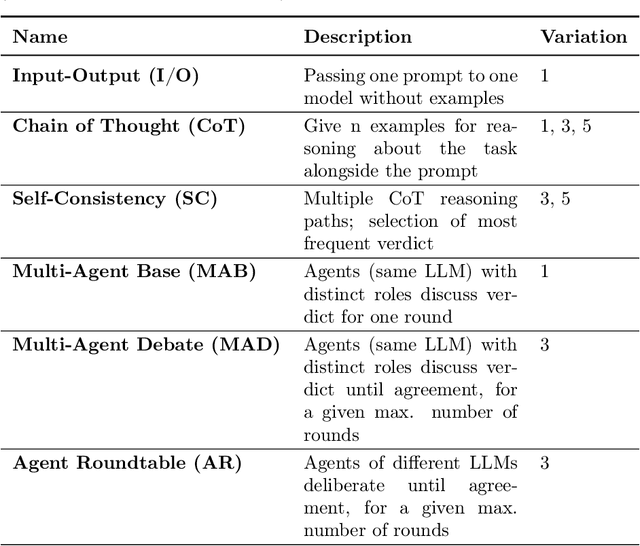
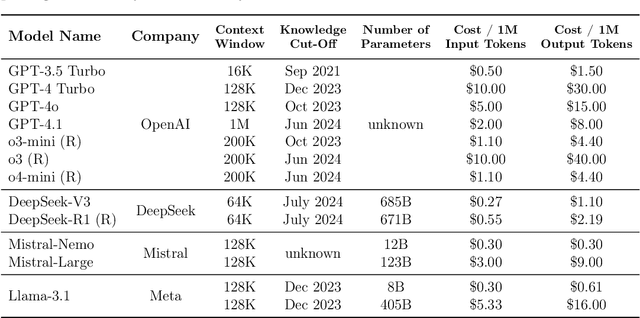

In-Car Conversational Question Answering (ConvQA) systems significantly enhance user experience by enabling seamless voice interactions. However, assessing their accuracy and reliability remains a challenge. This paper explores the use of Large Language Models (LLMs) alongside advanced prompting techniques and agent-based methods to evaluate the extent to which ConvQA system responses adhere to user utterances. The focus lies on contextual understanding and the ability to provide accurate venue recommendations considering user constraints and situational context. To evaluate utterance-response coherence using an LLM, we synthetically generate user utterances accompanied by correct and modified failure-containing system responses. We use input-output, chain-of-thought, self-consistency prompting, and multi-agent prompting techniques with 13 reasoning and non-reasoning LLMs of varying sizes and providers, including OpenAI, DeepSeek, Mistral AI, and Meta. We evaluate our approach on a case study involving restaurant recommendations. The most substantial improvements occur for small non-reasoning models when applying advanced prompting techniques, particularly multi-agent prompting. However, reasoning models consistently outperform non-reasoning models, with the best performance achieved using single-agent prompting with self-consistency. Notably, DeepSeek-R1 reaches an F1-score of 0.99 at a cost of 0.002 USD per request. Overall, the best balance between effectiveness and cost-time efficiency is reached with the non-reasoning model DeepSeek-V3. Our findings show that LLM-based evaluation offers a scalable and accurate alternative to traditional human evaluation for benchmarking contextual understanding in ConvQA systems.
A Multi-Modality Evaluation of the Reality Gap in Autonomous Driving Systems
Sep 26, 2025Simulation-based testing is a cornerstone of Autonomous Driving System (ADS) development, offering safe and scalable evaluation across diverse driving scenarios. However, discrepancies between simulated and real-world behavior, known as the reality gap, challenge the transferability of test results to deployed systems. In this paper, we present a comprehensive empirical study comparing four representative testing modalities: Software-in-the-Loop (SiL), Vehicle-in-the-Loop (ViL), Mixed-Reality (MR), and full real-world testing. Using a small-scale physical vehicle equipped with real sensors (camera and LiDAR) and its digital twin, we implement each setup and evaluate two ADS architectures (modular and end-to-end) across diverse indoor driving scenarios involving real obstacles, road topologies, and indoor environments. We systematically assess the impact of each testing modality along three dimensions of the reality gap: actuation, perception, and behavioral fidelity. Our results show that while SiL and ViL setups simplify critical aspects of real-world dynamics and sensing, MR testing improves perceptual realism without compromising safety or control. Importantly, we identify the conditions under which failures do not transfer across testing modalities and isolate the underlying dimensions of the gap responsible for these discrepancies. Our findings offer actionable insights into the respective strengths and limitations of each modality and outline a path toward more robust and transferable validation of autonomous driving systems.
Mapping Neural Theories of Consciousness onto the Common Model of Cognition
Jun 13, 2025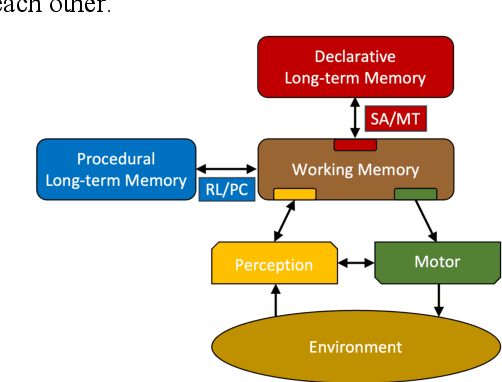
A beginning is made at mapping four neural theories of consciousness onto the Common Model of Cognition. This highlights how the four jointly depend on recurrent local modules plus a cognitive cycle operating on a global working memory with complex states, and reveals how an existing integrative view of consciousness from a neural perspective aligns with the Com-mon Model.
Foundation Models in Autonomous Driving: A Survey on Scenario Generation and Scenario Analysis
Jun 13, 2025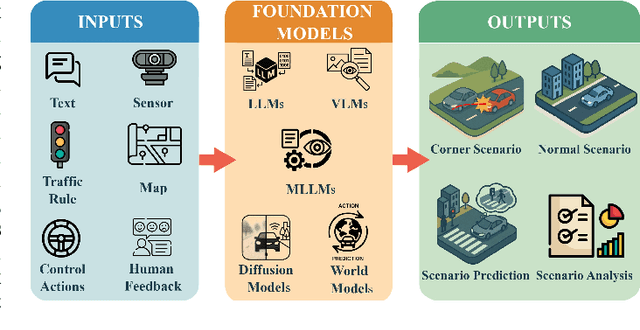
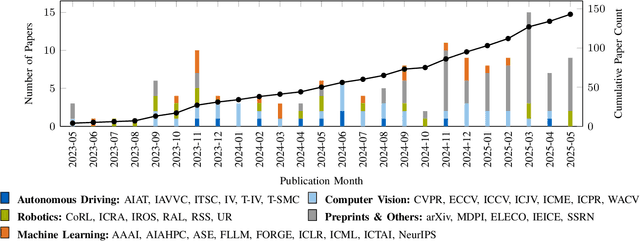
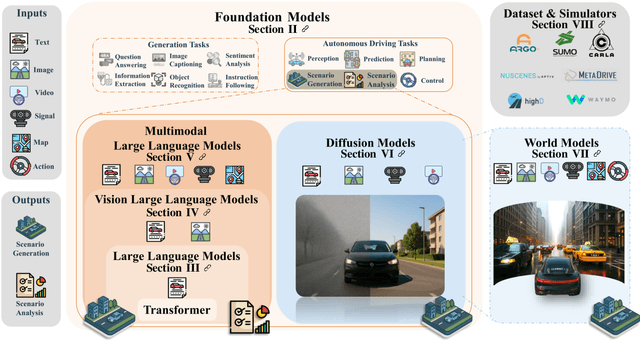

For autonomous vehicles, safe navigation in complex environments depends on handling a broad range of diverse and rare driving scenarios. Simulation- and scenario-based testing have emerged as key approaches to development and validation of autonomous driving systems. Traditional scenario generation relies on rule-based systems, knowledge-driven models, and data-driven synthesis, often producing limited diversity and unrealistic safety-critical cases. With the emergence of foundation models, which represent a new generation of pre-trained, general-purpose AI models, developers can process heterogeneous inputs (e.g., natural language, sensor data, HD maps, and control actions), enabling the synthesis and interpretation of complex driving scenarios. In this paper, we conduct a survey about the application of foundation models for scenario generation and scenario analysis in autonomous driving (as of May 2025). Our survey presents a unified taxonomy that includes large language models, vision-language models, multimodal large language models, diffusion models, and world models for the generation and analysis of autonomous driving scenarios. In addition, we review the methodologies, open-source datasets, simulation platforms, and benchmark challenges, and we examine the evaluation metrics tailored explicitly to scenario generation and analysis. Finally, the survey concludes by highlighting the open challenges and research questions, and outlining promising future research directions. All reviewed papers are listed in a continuously maintained repository, which contains supplementary materials and is available at https://github.com/TUM-AVS/FM-for-Scenario-Generation-Analysis.
A Proposal to Extend the Common Model of Cognition with Metacognition
Jun 09, 2025The Common Model of Cognition (CMC) provides an abstract characterization of the structure and processing required by a cognitive architecture for human-like minds. We propose a unified approach to integrating metacognition within the CMC. We propose that metacognition involves reasoning over explicit representations of an agent's cognitive capabilities and processes in working memory. Our proposal exploits the existing cognitive capabilities of the CMC, making minimal extensions in the structure and information available within working memory. We provide examples of metacognition within our proposal.
Automated Factual Benchmarking for In-Car Conversational Systems using Large Language Models
Apr 01, 2025In-car conversational systems bring the promise to improve the in-vehicle user experience. Modern conversational systems are based on Large Language Models (LLMs), which makes them prone to errors such as hallucinations, i.e., inaccurate, fictitious, and therefore factually incorrect information. In this paper, we present an LLM-based methodology for the automatic factual benchmarking of in-car conversational systems. We instantiate our methodology with five LLM-based methods, leveraging ensembling techniques and diverse personae to enhance agreement and minimize hallucinations. We use our methodology to evaluate CarExpert, an in-car retrieval-augmented conversational question answering system, with respect to the factual correctness to a vehicle's manual. We produced a novel dataset specifically created for the in-car domain, and tested our methodology against an expert evaluation. Our results show that the combination of GPT-4 with the Input Output Prompting achieves over 90 per cent factual correctness agreement rate with expert evaluations, other than being the most efficient approach yielding an average response time of 4.5s. Our findings suggest that LLM-based testing constitutes a viable approach for the validation of conversational systems regarding their factual correctness.
Simulator Ensembles for Trustworthy Autonomous Driving Testing
Mar 11, 2025Scenario-based testing with driving simulators is extensively used to identify failing conditions of automated driving assistance systems (ADAS) and reduce the amount of in-field road testing. However, existing studies have shown that repeated test execution in the same as well as in distinct simulators can yield different outcomes, which can be attributed to sources of flakiness or different implementations of the physics, among other factors. In this paper, we present MultiSim, a novel approach to multi-simulation ADAS testing based on a search-based testing approach that leverages an ensemble of simulators to identify failure-inducing, simulator-agnostic test scenarios. During the search, each scenario is evaluated jointly on multiple simulators. Scenarios that produce consistent results across simulators are prioritized for further exploration, while those that fail on only a subset of simulators are given less priority, as they may reflect simulator-specific issues rather than generalizable failures. Our case study, which involves testing a deep neural network-based ADAS on different pairs of three widely used simulators, demonstrates that MultiSim outperforms single-simulator testing by achieving on average a higher rate of simulator-agnostic failures by 51%. Compared to a state-of-the-art multi-simulator approach that combines the outcome of independent test generation campaigns obtained in different simulators, MultiSim identifies 54% more simulator-agnostic failing tests while showing a comparable validity rate. An enhancement of MultiSim that leverages surrogate models to predict simulator disagreements and bypass executions does not only increase the average number of valid failures but also improves efficiency in finding the first valid failure.
Benchmarking Image Perturbations for Testing Automated Driving Assistance Systems
Jan 21, 2025



Advanced Driver Assistance Systems (ADAS) based on deep neural networks (DNNs) are widely used in autonomous vehicles for critical perception tasks such as object detection, semantic segmentation, and lane recognition. However, these systems are highly sensitive to input variations, such as noise and changes in lighting, which can compromise their effectiveness and potentially lead to safety-critical failures. This study offers a comprehensive empirical evaluation of image perturbations, techniques commonly used to assess the robustness of DNNs, to validate and improve the robustness and generalization of ADAS perception systems. We first conducted a systematic review of the literature, identifying 38 categories of perturbations. Next, we evaluated their effectiveness in revealing failures in two different ADAS, both at the component and at the system level. Finally, we explored the use of perturbation-based data augmentation and continuous learning strategies to improve ADAS adaptation to new operational design domains. Our results demonstrate that all categories of image perturbations successfully expose robustness issues in ADAS and that the use of dataset augmentation and continuous learning significantly improves ADAS performance in novel, unseen environments.
Benchmarking Generative AI Models for Deep Learning Test Input Generation
Dec 23, 2024



Test Input Generators (TIGs) are crucial to assess the ability of Deep Learning (DL) image classifiers to provide correct predictions for inputs beyond their training and test sets. Recent advancements in Generative AI (GenAI) models have made them a powerful tool for creating and manipulating synthetic images, although these advancements also imply increased complexity and resource demands for training. In this work, we benchmark and combine different GenAI models with TIGs, assessing their effectiveness, efficiency, and quality of the generated test images, in terms of domain validity and label preservation. We conduct an empirical study involving three different GenAI architectures (VAEs, GANs, Diffusion Models), five classification tasks of increasing complexity, and 364 human evaluations. Our results show that simpler architectures, such as VAEs, are sufficient for less complex datasets like MNIST. However, when dealing with feature-rich datasets, such as ImageNet, more sophisticated architectures like Diffusion Models achieve superior performance by generating a higher number of valid, misclassification-inducing inputs.