 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Cooperative Co-evolutionary Search to Generate Metamorphic Test Cases for Autonomous Driving Systems
Dec 05, 2024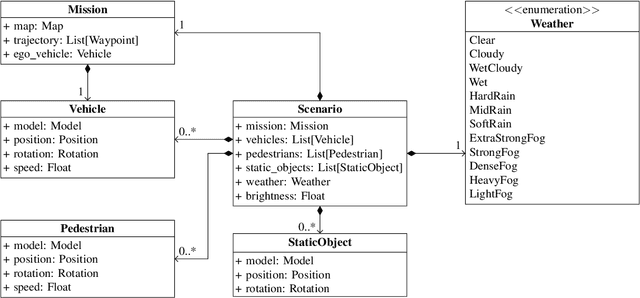
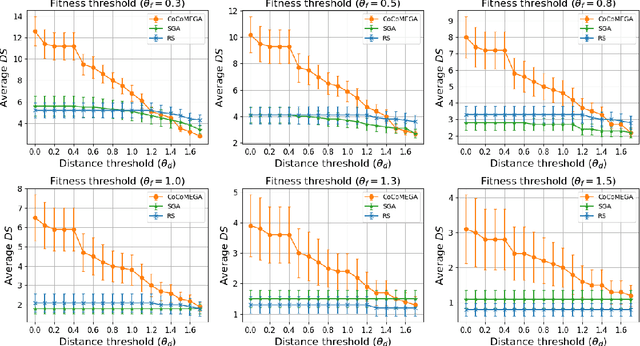
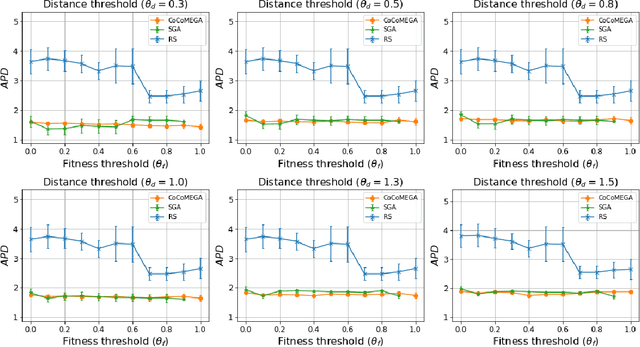
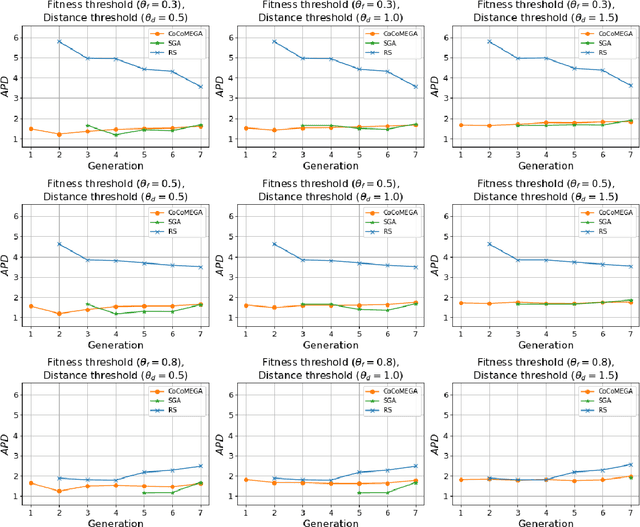
Autonomous Driving Systems (ADSs) rely on Deep Neural Networks, allowing vehicles to navigate complex, open environments. However, the unpredictability of these scenarios highlights the need for rigorous system-level testing to ensure safety, a task usually performed with a simulator in the loop. Though one important goal of such testing is to detect safety violations, there are many undesirable system behaviors, that may not immediately lead to violations, that testing should also be focusing on, thus detecting more subtle problems and enabling a finer-grained analysis. This paper introduces Cooperative Co-evolutionary MEtamorphic test Generator for Autonomous systems (CoCoMEGA), a novel automated testing framework aimed at advancing system-level safety assessments of ADSs. CoCoMEGA combines Metamorphic Testing (MT) with a search-based approach utilizing Cooperative Co-Evolutionary Algorithms (CCEA) to efficiently generate a diverse set of test cases. CoCoMEGA emphasizes the identification of test scenarios that present undesirable system behavior, that may eventually lead to safety violations, captured by Metamorphic Relations (MRs). When evaluated within the CARLA simulation environment on the Interfuser ADS, CoCoMEGA consistently outperforms baseline methods, demonstrating enhanced effectiveness and efficiency in generating severe, diverse MR violations and achieving broader exploration of the test space. These results underscore CoCoMEGA as a promising, more scalable solution to the inherent challenges in ADS testing with a simulator in the loop. Future research directions may include extending the approach to additional simulation platforms, applying it to other complex systems, and exploring methods for further improving testing efficiency such as surrogate modeling.
System Safety Monitoring of Learned Components Using Temporal Metric Forecasting
May 21, 2024In learning-enabled autonomous systems, safety monitoring of learned components is crucial to ensure their outputs do not lead to system safety violations, given the operational context of the system. However, developing a safety monitor for practical deployment in real-world applications is challenging. This is due to limited access to internal workings and training data of the learned component. Furthermore, safety monitors should predict safety violations with low latency, while consuming a reasonable amount of computation. To address the challenges, we propose a safety monitoring method based on probabilistic time series forecasting. Given the learned component outputs and an operational context, we empirically investigate different Deep Learning (DL)-based probabilistic forecasting to predict the objective measure capturing the satisfaction or violation of a safety requirement (safety metric). We empirically evaluate safety metric and violation prediction accuracy, and inference latency and resource usage of four state-of-the-art models, with varying horizons, using an autonomous aviation case study. Our results suggest that probabilistic forecasting of safety metrics, given learned component outputs and scenarios, is effective for safety monitoring. Furthermore, for the autonomous aviation case study, Temporal Fusion Transformer (TFT) was the most accurate model for predicting imminent safety violations, with acceptable latency and resource consumption.
SMARLA: A Safety Monitoring Approach for Deep Reinforcement Learning Agents
Aug 03, 2023
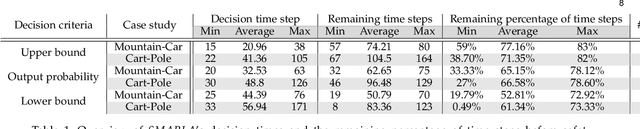


Deep reinforcement learning algorithms (DRL) are increasingly being used in safety-critical systems. Ensuring the safety of DRL agents is a critical concern in such contexts. However, relying solely on testing is not sufficient to ensure safety as it does not offer guarantees. Building safety monitors is one solution to alleviate this challenge. This paper proposes SMARLA, a machine learning-based safety monitoring approach designed for DRL agents. For practical reasons, SMARLA is designed to be black-box (as it does not require access to the internals of the agent) and leverages state abstraction to reduce the state space and thus facilitate the learning of safety violation prediction models from agent's states. We validated SMARLA on two well-known RL case studies. Empirical analysis reveals that SMARLA achieves accurate violation prediction with a low false positive rate, and can predict safety violations at an early stage, approximately halfway through the agent's execution before violations occur.
Identifying the Hazard Boundary of ML-enabled Autonomous Systems Using Cooperative Co-Evolutionary Search
Jan 31, 2023



In Machine Learning (ML)-enabled autonomous systems (MLASs), it is essential to identify the hazard boundary of ML Components (MLCs) in the MLAS under analysis. Given that such boundary captures the conditions in terms of MLC behavior and system context that can lead to hazards, it can then be used to, for example, build a safety monitor that can take any predefined fallback mechanisms at runtime when reaching the hazard boundary. However, determining such hazard boundary for an ML component is challenging. This is due to the space combining system contexts (i.e., scenarios) and MLC behaviors (i.e., inputs and outputs) being far too large for exhaustive exploration and even to handle using conventional metaheuristics, such as genetic algorithms. Additionally, the high computational cost of simulations required to determine any MLAS safety violations makes the problem even more challenging. Furthermore, it is unrealistic to consider a region in the problem space deterministically safe or unsafe due to the uncontrollable parameters in simulations and the non-linear behaviors of ML models (e.g., deep neural networks) in the MLAS under analysis. To address the challenges, we propose MLCSHE (ML Component Safety Hazard Envelope), a novel method based on a Cooperative Co-Evolutionary Algorithm (CCEA), which aims to tackle a high-dimensional problem by decomposing it into two lower-dimensional search subproblems. Moreover, we take a probabilistic view of safe and unsafe regions and define a novel fitness function to measure the distance from the probabilistic hazard boundary and thus drive the search effectively. We evaluate the effectiveness and efficiency of MLCSHE on a complex Autonomous Vehicle (AV) case study. Our evaluation results show that MLCSHE is significantly more effective and efficient compared to a standard genetic algorithm and random search.
Learning Failure-Inducing Models for Testing Software-Defined Networks
Oct 27, 2022Software-defined networks (SDN) enable flexible and effective communication systems, e.g., data centers, that are managed by centralized software controllers. However, such a controller can undermine the underlying communication network of an SDN-based system and thus must be carefully tested. When an SDN-based system fails, in order to address such a failure, engineers need to precisely understand the conditions under which it occurs. In this paper, we introduce a machine learning-guided fuzzing method, named FuzzSDN, aiming at both (1) generating effective test data leading to failures in SDN-based systems and (2) learning accurate failure-inducing models that characterize conditions under which such system fails. This is done in a synergistic manner where models guide test generation and the latter also aims at improving the models. To our knowledge, FuzzSDN is the first attempt to simultaneously address these two objectives for SDNs. We evaluate FuzzSDN by applying it to systems controlled by two open-source SDN controllers. Further, we compare FuzzSDN with two state-of-the-art methods for fuzzing SDNs and two baselines (i.e., simple extensions of these two existing methods) for learning failure-inducing models. Our results show that (1) compared to the state-of-the-art methods, FuzzSDN generates at least 12 times more failures, within the same time budget, with a controller that is fairly robust to fuzzing and (2) our failure-inducing models have, on average, a precision of 98% and a recall of 86%, significantly outperforming the baselines.
An AI-based Approach for Tracing Content Requirements in Financial Documents
Oct 28, 2021

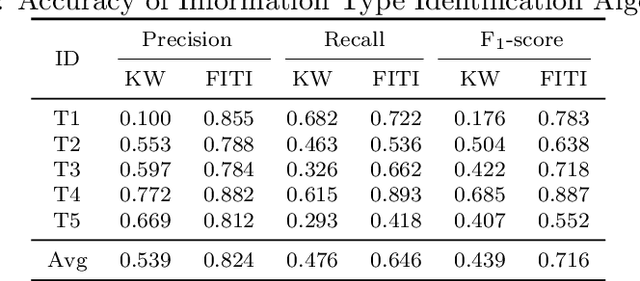
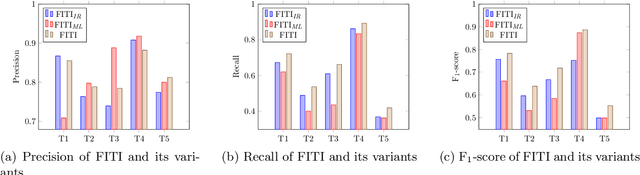
The completeness (in terms of content) of financial documents is a fundamental requirement for investment funds. To ensure completeness, financial regulators spend a huge amount of time for carefully checking every financial document based on the relevant content requirements, which prescribe the information types to be included in financial documents (e.g., the description of shares' issue conditions). Although several techniques have been proposed to automatically detect certain types of information in documents in various application domains, they provide limited support to help regulators automatically identify the text chunks related to financial information types, due to the complexity of financial documents and the diversity of the sentences characterizing an information type. In this paper, we propose FITI, an artificial intelligence (AI)-based method for tracing content requirements in financial documents. Given a new financial document, FITI selects a set of candidate sentences for efficient information type identification. Then, FITI uses a combination of rule-based and data-centric approaches, by leveraging information retrieval (IR) and machine learning (ML) techniques that analyze the words, sentences, and contexts related to an information type, to rank candidate sentences. Finally, using a list of indicator phrases related to each information type, a heuristic-based selector, which considers both the sentence ranking and the domain-specific phrases, determines a list of sentences corresponding to each information type. We evaluated FITI by assessing its effectiveness in tracing financial content requirements in 100 financial documents. Experimental results show that FITI provides accurate identification with average precision and recall values of 0.824 and 0.646, respectively. Furthermore, FITI can detect about 80% of missing information types in financial documents.
AI-enabled Automation for Completeness Checking of Privacy Policies
Jun 10, 2021
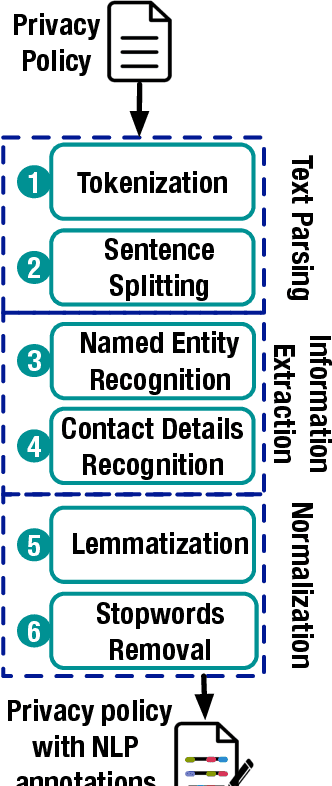
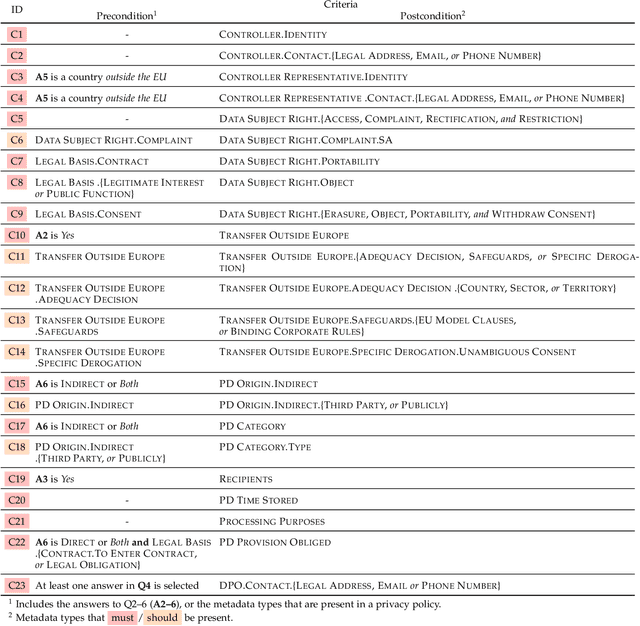

Technological advances in information sharing have raised concerns about data protection. Privacy policies contain privacy-related requirements about how the personal data of individuals will be handled by an organization or a software system (e.g., a web service or an app). In Europe, privacy policies are subject to compliance with the General Data Protection Regulation (GDPR). A prerequisite for GDPR compliance checking is to verify whether the content of a privacy policy is complete according to the provisions of GDPR. Incomplete privacy policies might result in large fines on violating organization as well as incomplete privacy-related software specifications. Manual completeness checking is both time-consuming and error-prone. In this paper, we propose AI-based automation for the completeness checking of privacy policies. Through systematic qualitative methods, we first build two artifacts to characterize the privacy-related provisions of GDPR, namely a conceptual model and a set of completeness criteria. Then, we develop an automated solution on top of these artifacts by leveraging a combination of natural language processing and supervised machine learning. Specifically, we identify the GDPR-relevant information content in privacy policies and subsequently check them against the completeness criteria. To evaluate our approach, we collected 234 real privacy policies from the fund industry. Over a set of 48 unseen privacy policies, our approach detected 300 of the total of 334 violations of some completeness criteria correctly, while producing 23 false positives. The approach thus has a precision of 92.9% and recall of 89.8%. Compared to a baseline that applies keyword search only, our approach results in an improvement of 24.5% in precision and 38% in recall.
Automatic Test Suite Generation for Key-points Detection DNNs Using Many-Objective Search
Dec 11, 2020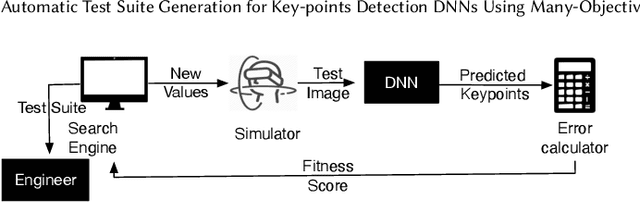
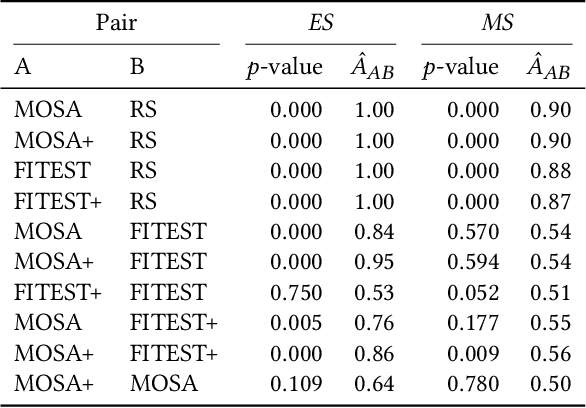
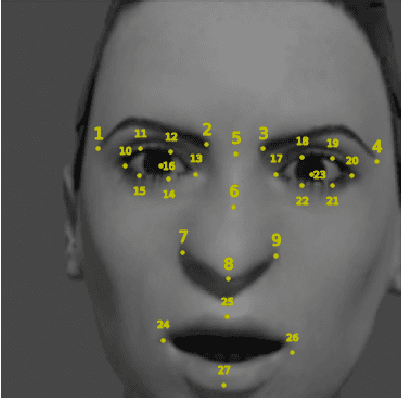

Automatically detecting the positions of key-points (e.g., facial key-points or finger key-points) in an image is an essential problem in many applications, such as driver's gaze detection and drowsiness detection in automated driving systems. With the recent advances of Deep Neural Networks (DNNs), Key-Points detection DNNs (KP-DNNs) have been increasingly employed for that purpose. Nevertheless, KP-DNN testing and validation have remained a challenging problem because KP-DNNs predict many independent key-points at the same time -- where each individual key-point may be critical in the targeted application -- and images can vary a great deal according to many factors. In this paper, we present an approach to automatically generate test data for KP-DNNs using many-objective search. In our experiments, focused on facial key-points detection DNNs developed for an industrial automotive application, we show that our approach can generate test suites to severely mispredict, on average, more than 93% of all key-points. In comparison, random search-based test data generation can only severely mispredict 41% of them. Many of these mispredictions, however, are not avoidable and should not therefore be considered failures. We also empirically compare state-of-the-art, many-objective search algorithms and their variants, tailored for test suite generation. Furthermore, we investigate and demonstrate how to learn specific conditions, based on image characteristics (e.g., head posture and skin color), that lead to severe mispredictions. Such conditions serve as a basis for risk analysis or DNN retraining.