 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMARLA: A Safety Monitoring Approach for Deep Reinforcement Learning Agents
Aug 03, 2023
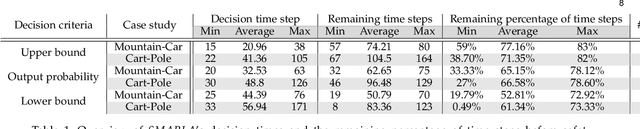


Deep reinforcement learning algorithms (DRL) are increasingly being used in safety-critical systems. Ensuring the safety of DRL agents is a critical concern in such contexts. However, relying solely on testing is not sufficient to ensure safety as it does not offer guarantees. Building safety monitors is one solution to alleviate this challenge. This paper proposes SMARLA, a machine learning-based safety monitoring approach designed for DRL agents. For practical reasons, SMARLA is designed to be black-box (as it does not require access to the internals of the agent) and leverages state abstraction to reduce the state space and thus facilitate the learning of safety violation prediction models from agent's states. We validated SMARLA on two well-known RL case studies. Empirical analysis reveals that SMARLA achieves accurate violation prediction with a low false positive rate, and can predict safety violations at an early stage, approximately halfway through the agent's execution before violations occur.
DeepGD: A Multi-Objective Black-Box Test Selection Approach for Deep Neural Networks
Mar 08, 2023Deep neural networks (DNNs) are widely used in various application domains such as image processing, speech recognition, and natural language processing. However, testing DNN models may be challenging due to the complexity and size of their input domain. Particularly, testing DNN models often requires generating or exploring large unlabeled datasets. In practice, DNN test oracles, which identify the correct outputs for inputs, often require expensive manual effort to label test data, possibly involving multiple experts to ensure labeling correctness. In this paper, we propose DeepGD, a black-box multi-objective test selection approach for DNN models. It reduces the cost of labeling by prioritizing the selection of test inputs with high fault revealing power from large unlabeled datasets. DeepGD not only selects test inputs with high uncertainty scores to trigger as many mispredicted inputs as possible but also maximizes the probability of revealing distinct faults in the DNN model by selecting diverse mispredicted inputs. The experimental results conducted on four widely used datasets and five DNN models show that in terms of fault-revealing ability: (1) White-box, coverage-based approaches fare poorly, (2) DeepGD outperforms existing black-box test selection approaches in terms of fault detection, and (3) DeepGD also leads to better guidance for DNN model retraining when using selected inputs to augment the training set.
Search-Based Testing Approach for Deep Reinforcement Learning Agents
Jun 15, 2022


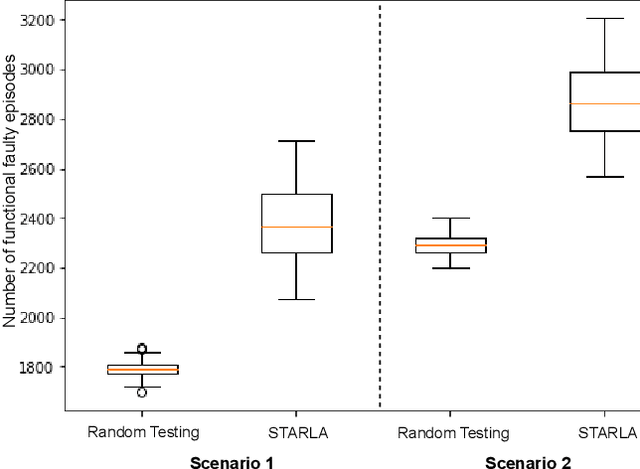
Deep Reinforcement Learning (DRL) algorithms have been increasingly employed during the last decade to solve various decision-making problems such as autonomous driving and robotics. However, these algorithms have faced great challenges when deployed in safety-critical environments since they often exhibit erroneous behaviors that can lead to potentially critical errors. One way to assess the safety of DRL agents is to test them to detect possible faults leading to critical failures during their execution. This raises the question of how we can efficiently test DRL policies to ensure their correctness and adherence to safety requirements. Most existing works on testing DRL agents use adversarial attacks that perturb states or actions of the agent. However, such attacks often lead to unrealistic states of the environment. Their main goal is to test the robustness of DRL agents rather than testing the compliance of agents' policies with respect to requirements. Due to the huge state space of DRL environments, the high cost of test execution, and the black-box nature of DRL algorithms, the exhaustive testing of DRL agents is impossible. In this paper, we propose a Search-based Testing Approach of Reinforcement Learning Agents (STARLA) to test the policy of a DRL agent by effectively searching for failing executions of the agent within a limited testing budget. We use machine learning models and a dedicated genetic algorithm to narrow the search towards faulty episodes. We apply STARLA on a Deep-Q-Learning agent which is widely used as a benchmark and show that it significantly outperforms Random Testing by detecting more faults related to the agent's policy. We also investigate how to extract rules that characterize faulty episodes of the DRL agent using our search results. Such rules can be used to understand the conditions under which the agent fails and thus assess its deployment risks.
Black-Box Testing of Deep Neural Networks through Test Case Diversity
Jan 18, 2022

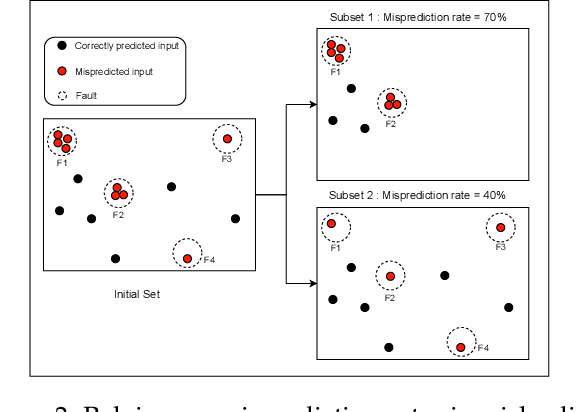

Deep Neural Networks (DNNs) have been extensively used in many areas including image processing, medical diagnostics, and autonomous driving. However, DNNs can exhibit erroneous behaviours that may lead to critical errors, especially when used in safety-critical systems. Inspired by testing techniques for traditional software systems, researchers have proposed neuron coverage criteria, as an analogy to source code coverage, to guide the testing of DNN models. Despite very active research on DNN coverage, several recent studies have questioned the usefulness of such criteria in guiding DNN testing. Further, from a practical standpoint, these criteria are white-box as they require access to the internals or training data of DNN models, which is in many contexts not feasible or convenient. In this paper, we investigate black-box input diversity metrics as an alternative to white-box coverage criteria. To this end, we first select and adapt three diversity metrics and study, in a controlled manner, their capacity to measure actual diversity in input sets. We then analyse their statistical association with fault detection using two datasets and three DNN models. We further compare diversity with state-of-the-art white-box coverage criteria. Our experiments show that relying on the diversity of image features embedded in test input sets is a more reliable indicator than coverage criteria to effectively guide the testing of DNNs. Indeed, we found that one of our selected black-box diversity metrics far outperforms existing coverage criteria in terms of fault-revealing capability and computational time. Results also confirm the suspicions that state-of-the-art coverage metrics are not adequate to guide the construction of test input sets to detect as many faults as possible with natural inputs.