 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepGD: A Multi-Objective Black-Box Test Selection Approach for Deep Neural Networks
Mar 08, 2023Deep neural networks (DNNs) are widely used in various application domains such as image processing, speech recognition, and natural language processing. However, testing DNN models may be challenging due to the complexity and size of their input domain. Particularly, testing DNN models often requires generating or exploring large unlabeled datasets. In practice, DNN test oracles, which identify the correct outputs for inputs, often require expensive manual effort to label test data, possibly involving multiple experts to ensure labeling correctness. In this paper, we propose DeepGD, a black-box multi-objective test selection approach for DNN models. It reduces the cost of labeling by prioritizing the selection of test inputs with high fault revealing power from large unlabeled datasets. DeepGD not only selects test inputs with high uncertainty scores to trigger as many mispredicted inputs as possible but also maximizes the probability of revealing distinct faults in the DNN model by selecting diverse mispredicted inputs. The experimental results conducted on four widely used datasets and five DNN models show that in terms of fault-revealing ability: (1) White-box, coverage-based approaches fare poorly, (2) DeepGD outperforms existing black-box test selection approaches in terms of fault detection, and (3) DeepGD also leads to better guidance for DNN model retraining when using selected inputs to augment the training set.
Black-Box Testing of Deep Neural Networks through Test Case Diversity
Jan 18, 2022

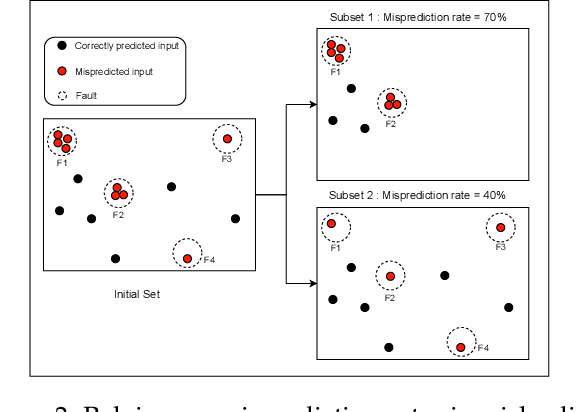

Deep Neural Networks (DNNs) have been extensively used in many areas including image processing, medical diagnostics, and autonomous driving. However, DNNs can exhibit erroneous behaviours that may lead to critical errors, especially when used in safety-critical systems. Inspired by testing techniques for traditional software systems, researchers have proposed neuron coverage criteria, as an analogy to source code coverage, to guide the testing of DNN models. Despite very active research on DNN coverage, several recent studies have questioned the usefulness of such criteria in guiding DNN testing. Further, from a practical standpoint, these criteria are white-box as they require access to the internals or training data of DNN models, which is in many contexts not feasible or convenient. In this paper, we investigate black-box input diversity metrics as an alternative to white-box coverage criteria. To this end, we first select and adapt three diversity metrics and study, in a controlled manner, their capacity to measure actual diversity in input sets. We then analyse their statistical association with fault detection using two datasets and three DNN models. We further compare diversity with state-of-the-art white-box coverage criteria. Our experiments show that relying on the diversity of image features embedded in test input sets is a more reliable indicator than coverage criteria to effectively guide the testing of DNNs. Indeed, we found that one of our selected black-box diversity metrics far outperforms existing coverage criteria in terms of fault-revealing capability and computational time. Results also confirm the suspicions that state-of-the-art coverage metrics are not adequate to guide the construction of test input sets to detect as many faults as possible with natural inputs.