 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetromorphic Testing with Hierarchical Verification for Hallucination Detection in RAG
Mar 29, 2026Large language models (LLMs) continue to hallucinate in retrieval-augmented generation (RAG), producing claims that are unsupported by or conflict with the retrieved context. Detecting such errors remains challenging when faithfulness is evaluated solely with respect to the retrieved context. Existing approaches either provide coarse-grained, answer-level scores or focus on open-domain factuality, often lacking fine-grained, evidence-grounded diagnostics. We present RT4CHART, a retromorphic testing framework for context-faithfulness assessment. RT4CHART decomposes model outputs into independently verifiable claims and performs hierarchical, local-to-global verification against the retrieved context. Each claim is assigned one of three labels: entailed, contradicted, or baseless. Furthermore, RT4CHART maps claim-level decisions back to specific answer spans and retrieves explicit supporting or refuting evidence from the context, enabling fine-grained and interpretable auditing. We evaluate RT4CHART on RAGTruth++ (408 samples) and RAGTruth-Enhance (2,675 samples), a newly re-annotated benchmark. RT4CHART achieves the best answer-level hallucination detection F1 among all baselines. On RAGTruth++, it reaches an F1 score of 0.776, outperforming the strongest baseline by 83%. On RAGTruth-Enhance, it achieves a span-level F1 of 47.5%. Ablation studies show that the hierarchical verification design is the primary driver of performance gains. Finally, our re-annotation reveals 1.68x more hallucination cases than the original labels, suggesting that existing benchmarks substantially underestimate the prevalence of hallucinations.
A Highly Efficient Diversity-based Input Selection for DNN Improvement Using VLMs
Jan 12, 2026Maintaining or improving the performance of Deep Neural Networks (DNNs) through fine-tuning requires labeling newly collected inputs, a process that is often costly and time-consuming. To alleviate this problem, input selection approaches have been developed in recent years to identify small, yet highly informative subsets for labeling. Diversity-based selection is one of the most effective approaches for this purpose. However, they are often computationally intensive and lack scalability for large input sets, limiting their practical applicability. To address this challenge, we introduce Concept-Based Diversity (CBD), a highly efficient metric for image inputs that leverages Vision-Language Models (VLM). Our results show that CBD exhibits a strong correlation with Geometric Diversity (GD), an established diversity metric, while requiring only a fraction of its computation time. Building on this finding, we propose a hybrid input selection approach that combines CBD with Margin, a simple uncertainty metric. We conduct a comprehensive evaluation across a diverse set of DNN models, input sets, selection budgets, and five most effective state-of-the-art selection baselines. The results demonstrate that the CBD-based selection consistently outperforms all baselines at guiding input selection to improve the DNN model. Furthermore, the CBD-based selection approach remains highly efficient, requiring selection times close to those of simple uncertainty-based methods such as Margin, even on larger input sets like ImageNet. These results confirm not only the effectiveness and computational advantage of the CBD-based approach, particularly compared to hybrid baselines, but also its scalability in repetitive and extensive input selection scenarios.
Legal Requirements Analysis
Nov 23, 2023Modern software has been an integral part of everyday activities in many disciplines and application contexts. Introducing intelligent automation by leveraging artificial intelligence (AI) led to break-throughs in many fields. The effectiveness of AI can be attributed to several factors, among which is the increasing availability of data. Regulations such as the general data protection regulation (GDPR) in the European Union (EU) are introduced to ensure the protection of personal data. Software systems that collect, process, or share personal data are subject to compliance with such regulations. Developing compliant software depends heavily on addressing legal requirements stipulated in applicable regulations, a central activity in the requirements engineering (RE) phase of the software development process. RE is concerned with specifying and maintaining requirements of a system-to-be, including legal requirements. Legal agreements which describe the policies organizations implement for processing personal data can provide an additional source to regulations for eliciting legal requirements. In this chapter, we explore a variety of methods for analyzing legal requirements and exemplify them on GDPR. Specifically, we describe possible alternatives for creating machine-analyzable representations from regulations, survey the existing automated means for enabling compliance verification against regulations, and further reflect on the current challenges of legal requirements analysis.
An Empirical Study on Log-based Anomaly Detection Using Machine Learning
Jul 31, 2023The growth of systems complexity increases the need of automated techniques dedicated to different log analysis tasks such as Log-based Anomaly Detection (LAD). The latter has been widely addressed in the literature, mostly by means of different deep learning techniques. Nevertheless, the focus on deep learning techniques results in less attention being paid to traditional Machine Learning (ML) techniques, which may perform well in many cases, depending on the context and the used datasets. Further, the evaluation of different ML techniques is mostly based on the assessment of their detection accuracy. However, this is is not enough to decide whether or not a specific ML technique is suitable to address the LAD problem. Other aspects to consider include the training and prediction time as well as the sensitivity to hyperparameter tuning. In this paper, we present a comprehensive empirical study, in which we evaluate different supervised and semi-supervised, traditional and deep ML techniques w.r.t. four evaluation criteria: detection accuracy, time performance, sensitivity of detection accuracy as well as time performance to hyperparameter tuning. The experimental results show that supervised traditional and deep ML techniques perform very closely in terms of their detection accuracy and prediction time. Moreover, the overall evaluation of the sensitivity of the detection accuracy of the different ML techniques to hyperparameter tuning shows that supervised traditional ML techniques are less sensitive to hyperparameter tuning than deep learning techniques. Further, semi-supervised techniques yield significantly worse detection accuracy than supervised techniques.
Black-Box Prediction of Flaky Test Fix Categories Using Language Models
Jun 21, 2023



Flaky tests are problematic because they non-deterministically pass or fail for the same software version under test, causing confusion and wasting developer time. While machine learning models have been used to predict flakiness and its root causes, there is less work on providing support to fix the problem. To address this gap, we propose a framework that automatically generates labeled datasets for 13 fix categories and train models to predict the fix category of a flaky test by analyzing the test code only. Though it is unrealistic at this stage to accurately predict the fix itself, the categories provide precise guidance about what part of the test code to look at. Our approach is based on language models, namely CodeBERT and UniXcoder, whose output is fine-tuned with a Feed Forward Neural Network (FNN) or a Siamese Network-based Few Shot Learning (FSL). Our experimental results show that UniXcoder outperforms CodeBERT, in correctly predicting most of the categories of fixes a developer should apply. Furthermore, FSL does not appear to have any significant effect. Given the high accuracy obtained for most fix categories, our proposed framework has the potential to help developers to fix flaky tests quickly and accurately.To aid future research, we make our automated labeling tool, dataset, prediction models, and experimental infrastructure publicly available.
DeepGD: A Multi-Objective Black-Box Test Selection Approach for Deep Neural Networks
Mar 08, 2023Deep neural networks (DNNs) are widely used in various application domains such as image processing, speech recognition, and natural language processing. However, testing DNN models may be challenging due to the complexity and size of their input domain. Particularly, testing DNN models often requires generating or exploring large unlabeled datasets. In practice, DNN test oracles, which identify the correct outputs for inputs, often require expensive manual effort to label test data, possibly involving multiple experts to ensure labeling correctness. In this paper, we propose DeepGD, a black-box multi-objective test selection approach for DNN models. It reduces the cost of labeling by prioritizing the selection of test inputs with high fault revealing power from large unlabeled datasets. DeepGD not only selects test inputs with high uncertainty scores to trigger as many mispredicted inputs as possible but also maximizes the probability of revealing distinct faults in the DNN model by selecting diverse mispredicted inputs. The experimental results conducted on four widely used datasets and five DNN models show that in terms of fault-revealing ability: (1) White-box, coverage-based approaches fare poorly, (2) DeepGD outperforms existing black-box test selection approaches in terms of fault detection, and (3) DeepGD also leads to better guidance for DNN model retraining when using selected inputs to augment the training set.
DNN Explanation for Safety Analysis: an Empirical Evaluation of Clustering-based Approaches
Jan 31, 2023The adoption of deep neural networks (DNNs) in safety-critical contexts is often prevented by the lack of effective means to explain their results, especially when they are erroneous. In our previous work, we proposed a white-box approach (HUDD) and a black-box approach (SAFE) to automatically characterize DNN failures. They both identify clusters of similar images from a potentially large set of images leading to DNN failures. However, the analysis pipelines for HUDD and SAFE were instantiated in specific ways according to common practices, deferring the analysis of other pipelines to future work. In this paper, we report on an empirical evaluation of 99 different pipelines for root cause analysis of DNN failures. They combine transfer learning, autoencoders, heatmaps of neuron relevance, dimensionality reduction techniques, and different clustering algorithms. Our results show that the best pipeline combines transfer learning, DBSCAN, and UMAP. It leads to clusters almost exclusively capturing images of the same failure scenario, thus facilitating root cause analysis. Further, it generates distinct clusters for each root cause of failure, thus enabling engineers to detect all the unsafe scenarios. Interestingly, these results hold even for failure scenarios that are only observed in a small percentage of the failing images.
Many-Objective Reinforcement Learning for Online Testing of DNN-Enabled Systems
Oct 27, 2022



Deep Neural Networks (DNNs) have been widely used to perform real-world tasks in cyber-physical systems such as Autonomous Diving Systems (ADS). Ensuring the correct behavior of such DNN-Enabled Systems (DES) is a crucial topic. Online testing is one of the promising modes for testing such systems with their application environments (simulated or real) in a closed loop taking into account the continuous interaction between the systems and their environments. However, the environmental variables (e.g., lighting conditions) that might change during the systems' operation in the real world, causing the DES to violate requirements (safety, functional), are often kept constant during the execution of an online test scenario due to the two major challenges: (1) the space of all possible scenarios to explore would become even larger if they changed and (2) there are typically many requirements to test simultaneously. In this paper, we present MORLOT (Many-Objective Reinforcement Learning for Online Testing), a novel online testing approach to address these challenges by combining Reinforcement Learning (RL) and many-objective search. MORLOT leverages RL to incrementally generate sequences of environmental changes while relying on many-objective search to determine the changes so that they are more likely to achieve any of the uncovered objectives. We empirically evaluate MORLOT using CARLA, a high-fidelity simulator widely used for autonomous driving research, integrated with Transfuser, a DNN-enabled ADS for end-to-end driving. The evaluation results show that MORLOT is significantly more effective and efficient than alternatives with a large effect size. In other words, MORLOT is a good option to test DES with dynamically changing environments while accounting for multiple safety requirements.
HUDD: A tool to debug DNNs for safety analysis
Oct 15, 2022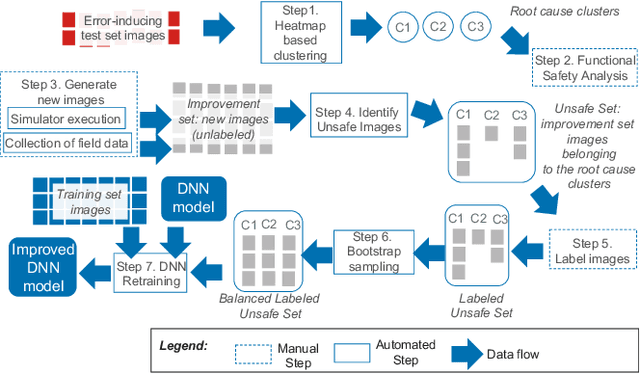
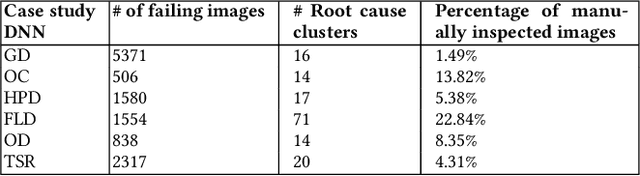
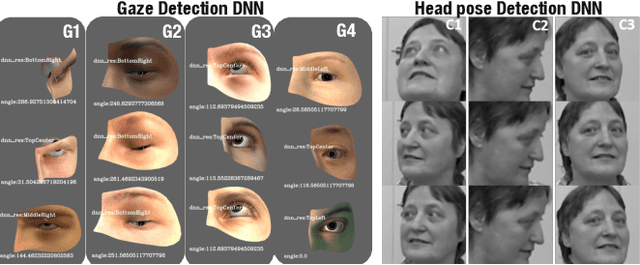
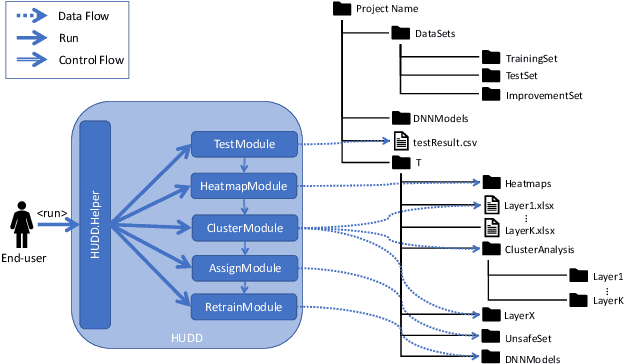
We present HUDD, a tool that supports safety analysis practices for systems enabled by Deep Neural Networks (DNNs) by automatically identifying the root causes for DNN errors and retraining the DNN. HUDD stands for Heatmap-based Unsupervised Debugging of DNNs, it automatically clusters error-inducing images whose results are due to common subsets of DNN neurons. The intent is for the generated clusters to group error-inducing images having common characteristics, that is, having a common root cause. HUDD identifies root causes by applying a clustering algorithm to matrices (i.e., heatmaps) capturing the relevance of every DNN neuron on the DNN outcome. Also, HUDD retrains DNNs with images that are automatically selected based on their relatedness to the identified image clusters. Our empirical evaluation with DNNs from the automotive domain have shown that HUDD automatically identifies all the distinct root causes of DNN errors, thus supporting safety analysis. Also, our retraining approach has shown to be more effective at improving DNN accuracy than existing approaches. A demo video of HUDD is available at https://youtu.be/drjVakP7jdU.
Search-Based Testing Approach for Deep Reinforcement Learning Agents
Jun 15, 2022


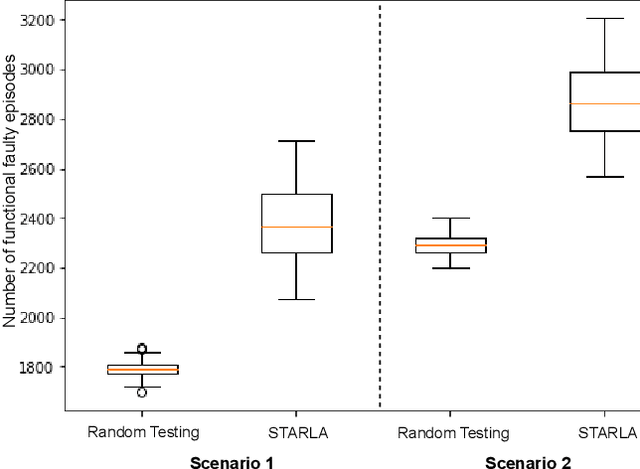
Deep Reinforcement Learning (DRL) algorithms have been increasingly employed during the last decade to solve various decision-making problems such as autonomous driving and robotics. However, these algorithms have faced great challenges when deployed in safety-critical environments since they often exhibit erroneous behaviors that can lead to potentially critical errors. One way to assess the safety of DRL agents is to test them to detect possible faults leading to critical failures during their execution. This raises the question of how we can efficiently test DRL policies to ensure their correctness and adherence to safety requirements. Most existing works on testing DRL agents use adversarial attacks that perturb states or actions of the agent. However, such attacks often lead to unrealistic states of the environment. Their main goal is to test the robustness of DRL agents rather than testing the compliance of agents' policies with respect to requirements. Due to the huge state space of DRL environments, the high cost of test execution, and the black-box nature of DRL algorithms, the exhaustive testing of DRL agents is impossible. In this paper, we propose a Search-based Testing Approach of Reinforcement Learning Agents (STARLA) to test the policy of a DRL agent by effectively searching for failing executions of the agent within a limited testing budget. We use machine learning models and a dedicated genetic algorithm to narrow the search towards faulty episodes. We apply STARLA on a Deep-Q-Learning agent which is widely used as a benchmark and show that it significantly outperforms Random Testing by detecting more faults related to the agent's policy. We also investigate how to extract rules that characterize faulty episodes of the DRL agent using our search results. Such rules can be used to understand the conditions under which the agent fails and thus assess its deployment risks.