 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch-Based Testing Approach for Deep Reinforcement Learning Agents
Jun 15, 2022


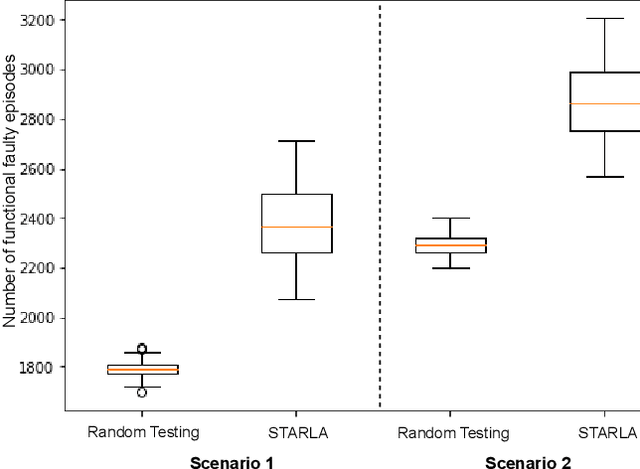
Deep Reinforcement Learning (DRL) algorithms have been increasingly employed during the last decade to solve various decision-making problems such as autonomous driving and robotics. However, these algorithms have faced great challenges when deployed in safety-critical environments since they often exhibit erroneous behaviors that can lead to potentially critical errors. One way to assess the safety of DRL agents is to test them to detect possible faults leading to critical failures during their execution. This raises the question of how we can efficiently test DRL policies to ensure their correctness and adherence to safety requirements. Most existing works on testing DRL agents use adversarial attacks that perturb states or actions of the agent. However, such attacks often lead to unrealistic states of the environment. Their main goal is to test the robustness of DRL agents rather than testing the compliance of agents' policies with respect to requirements. Due to the huge state space of DRL environments, the high cost of test execution, and the black-box nature of DRL algorithms, the exhaustive testing of DRL agents is impossible. In this paper, we propose a Search-based Testing Approach of Reinforcement Learning Agents (STARLA) to test the policy of a DRL agent by effectively searching for failing executions of the agent within a limited testing budget. We use machine learning models and a dedicated genetic algorithm to narrow the search towards faulty episodes. We apply STARLA on a Deep-Q-Learning agent which is widely used as a benchmark and show that it significantly outperforms Random Testing by detecting more faults related to the agent's policy. We also investigate how to extract rules that characterize faulty episodes of the DRL agent using our search results. Such rules can be used to understand the conditions under which the agent fails and thus assess its deployment risks.
Black-Box Testing of Deep Neural Networks through Test Case Diversity
Jan 18, 2022

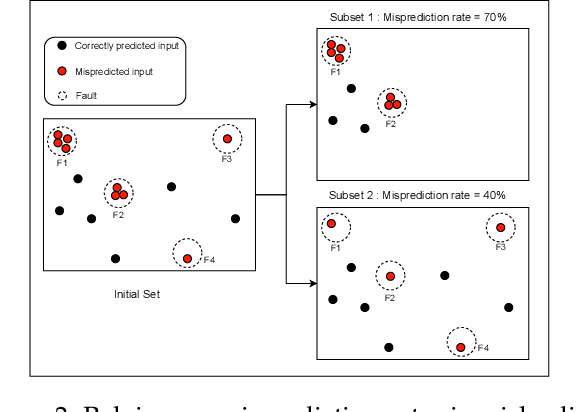

Deep Neural Networks (DNNs) have been extensively used in many areas including image processing, medical diagnostics, and autonomous driving. However, DNNs can exhibit erroneous behaviours that may lead to critical errors, especially when used in safety-critical systems. Inspired by testing techniques for traditional software systems, researchers have proposed neuron coverage criteria, as an analogy to source code coverage, to guide the testing of DNN models. Despite very active research on DNN coverage, several recent studies have questioned the usefulness of such criteria in guiding DNN testing. Further, from a practical standpoint, these criteria are white-box as they require access to the internals or training data of DNN models, which is in many contexts not feasible or convenient. In this paper, we investigate black-box input diversity metrics as an alternative to white-box coverage criteria. To this end, we first select and adapt three diversity metrics and study, in a controlled manner, their capacity to measure actual diversity in input sets. We then analyse their statistical association with fault detection using two datasets and three DNN models. We further compare diversity with state-of-the-art white-box coverage criteria. Our experiments show that relying on the diversity of image features embedded in test input sets is a more reliable indicator than coverage criteria to effectively guide the testing of DNNs. Indeed, we found that one of our selected black-box diversity metrics far outperforms existing coverage criteria in terms of fault-revealing capability and computational time. Results also confirm the suspicions that state-of-the-art coverage metrics are not adequate to guide the construction of test input sets to detect as many faults as possible with natural inputs.
Supporting DNN Safety Analysis and Retraining through Heatmap-based Unsupervised Learning
Feb 03, 2020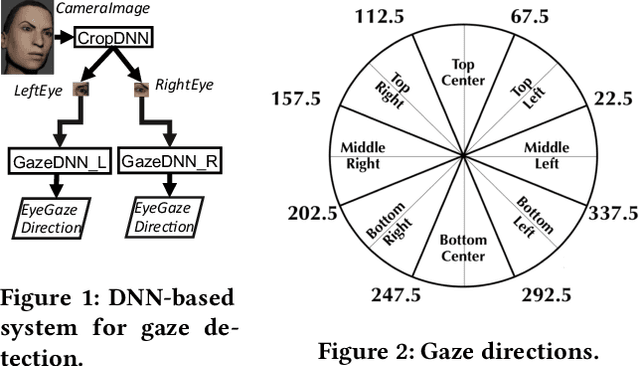
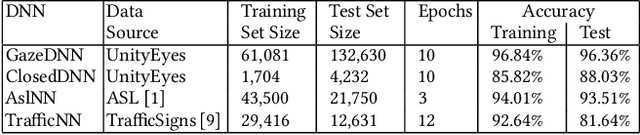
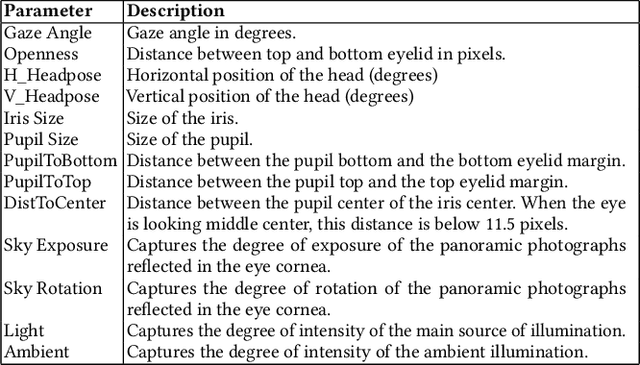
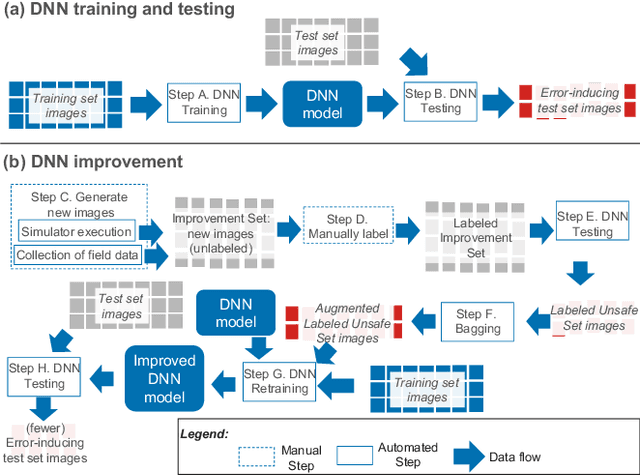
Deep neural networks (DNNs) are increasingly critical in modern safety-critical systems, for example in their perception layer to analyze images. Unfortunately, there is a lack of methods to ensure the functional safety of DNN-based components. The machine learning literature suggests one should trust DNNs demonstrating high accuracy on test sets. In case of low accuracy, DNNs should be retrained using additional inputs similar to the error-inducing ones. We observe two major challenges with existing practices for safety-critical systems: (1) scenarios that are underrepresented in the test set may represent serious risks, which may lead to safety violations, and may not be noticed; (2) debugging DNNs is poorly supported when error causes are difficult to visually detect. To address these problems, we propose HUDD, an approach that automatically supports the identification of root causes for DNN errors. We automatically group error-inducing images whose results are due to common subsets of selected DNN neurons. HUDD identifies root causes by applying a clustering algorithm to matrices (i.e., heatmaps) capturing the relevance of every DNN neuron on the DNN outcome. Also, HUDD retrains DNNs with images that are automatically selected based on their relatedness to the identified image clusters. We have evaluated HUDD with DNNs from the automotive domain. The approach was able to automatically identify all the distinct root causes of DNN errors, thus supporting safety analysis. Also, our retraining approach has shown to be more effective at improving DNN accuracy than existing approaches.