 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMany-Objective Reinforcement Learning for Online Testing of DNN-Enabled Systems
Oct 27, 2022



Deep Neural Networks (DNNs) have been widely used to perform real-world tasks in cyber-physical systems such as Autonomous Diving Systems (ADS). Ensuring the correct behavior of such DNN-Enabled Systems (DES) is a crucial topic. Online testing is one of the promising modes for testing such systems with their application environments (simulated or real) in a closed loop taking into account the continuous interaction between the systems and their environments. However, the environmental variables (e.g., lighting conditions) that might change during the systems' operation in the real world, causing the DES to violate requirements (safety, functional), are often kept constant during the execution of an online test scenario due to the two major challenges: (1) the space of all possible scenarios to explore would become even larger if they changed and (2) there are typically many requirements to test simultaneously. In this paper, we present MORLOT (Many-Objective Reinforcement Learning for Online Testing), a novel online testing approach to address these challenges by combining Reinforcement Learning (RL) and many-objective search. MORLOT leverages RL to incrementally generate sequences of environmental changes while relying on many-objective search to determine the changes so that they are more likely to achieve any of the uncovered objectives. We empirically evaluate MORLOT using CARLA, a high-fidelity simulator widely used for autonomous driving research, integrated with Transfuser, a DNN-enabled ADS for end-to-end driving. The evaluation results show that MORLOT is significantly more effective and efficient than alternatives with a large effect size. In other words, MORLOT is a good option to test DES with dynamically changing environments while accounting for multiple safety requirements.
Can Offline Testing of Deep Neural Networks Replace Their Online Testing?
Jan 26, 2021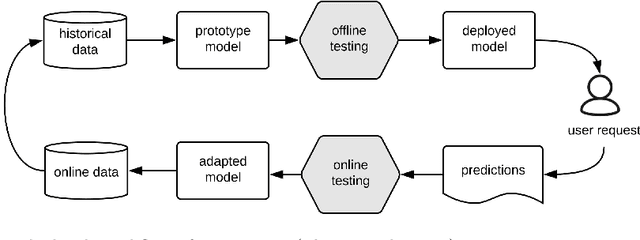
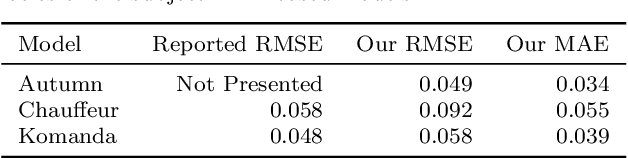
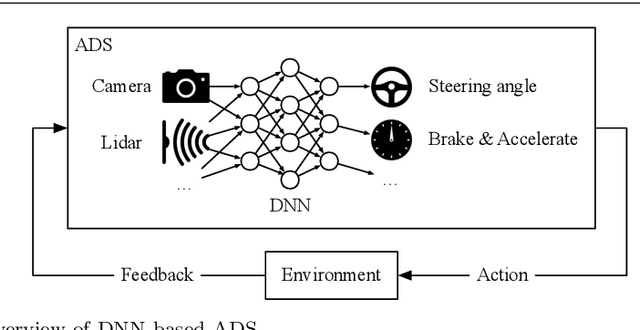
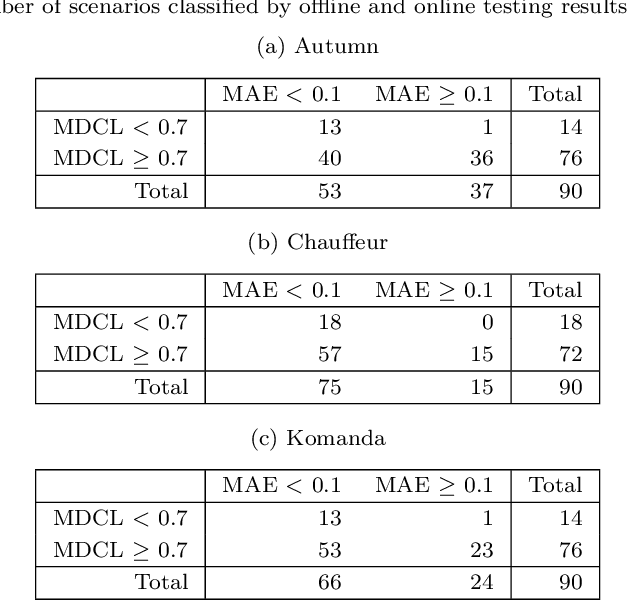
We distinguish two general modes of testing for Deep Neural Networks (DNNs): Offline testing where DNNs are tested as individual units based on test datasets obtained independently from the DNNs under test, and online testing where DNNs are embedded into a specific application environment and tested in a closed-loop mode in interaction with the application environment. Typically, DNNs are subjected to both types of testing during their development life cycle where offline testing is applied immediately after DNN training and online testing follows after offline testing and once a DNN is deployed within a specific application environment. In this paper, we study the relationship between offline and online testing. Our goal is to determine how offline testing and online testing differ or complement one another and if we can use offline testing results to run fewer tests during online testing to reduce the testing cost. Though these questions are generally relevant to all autonomous systems, we study them in the context of automated driving systems where, as study subjects, we use DNNs automating end-to-end controls of steering functions of self-driving vehicles. Our results show that offline testing is more optimistic than online testing as many safety violations identified by online testing could not be identified by offline testing, while large prediction errors generated by offline testing always led to severe safety violations detectable by online testing. Further, we cannot use offline testing results to run fewer tests during online testing in practice since we are not able to identify specific situations where offline testing could be as accurate as online testing in identifying safety requirement violations.
Automatic Test Suite Generation for Key-points Detection DNNs Using Many-Objective Search
Dec 11, 2020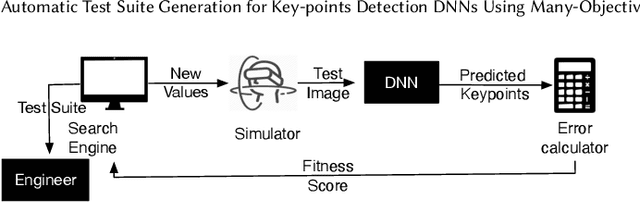
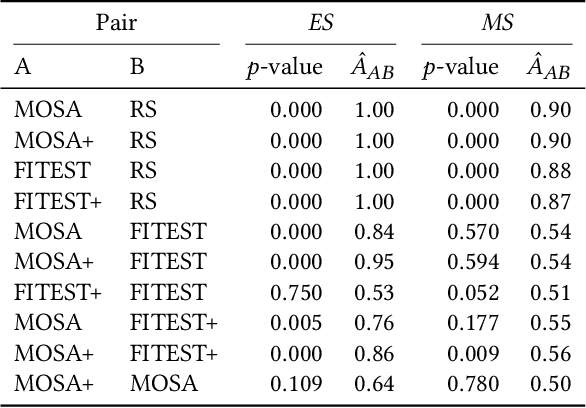
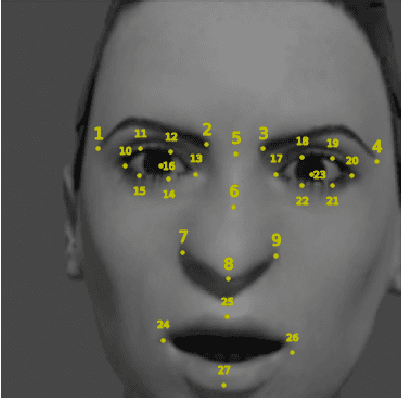

Automatically detecting the positions of key-points (e.g., facial key-points or finger key-points) in an image is an essential problem in many applications, such as driver's gaze detection and drowsiness detection in automated driving systems. With the recent advances of Deep Neural Networks (DNNs), Key-Points detection DNNs (KP-DNNs) have been increasingly employed for that purpose. Nevertheless, KP-DNN testing and validation have remained a challenging problem because KP-DNNs predict many independent key-points at the same time -- where each individual key-point may be critical in the targeted application -- and images can vary a great deal according to many factors. In this paper, we present an approach to automatically generate test data for KP-DNNs using many-objective search. In our experiments, focused on facial key-points detection DNNs developed for an industrial automotive application, we show that our approach can generate test suites to severely mispredict, on average, more than 93% of all key-points. In comparison, random search-based test data generation can only severely mispredict 41% of them. Many of these mispredictions, however, are not avoidable and should not therefore be considered failures. We also empirically compare state-of-the-art, many-objective search algorithms and their variants, tailored for test suite generation. Furthermore, we investigate and demonstrate how to learn specific conditions, based on image characteristics (e.g., head posture and skin color), that lead to severe mispredictions. Such conditions serve as a basis for risk analysis or DNN retraining.
Comparing Offline and Online Testing of Deep Neural Networks: An Autonomous Car Case Study
Nov 28, 2019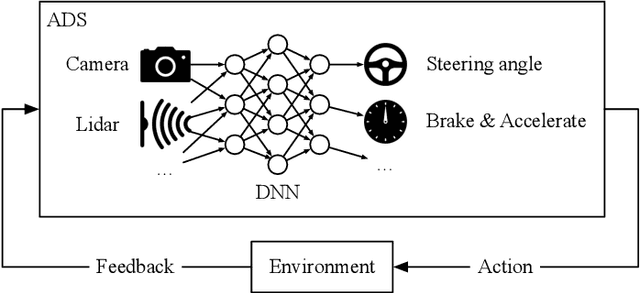
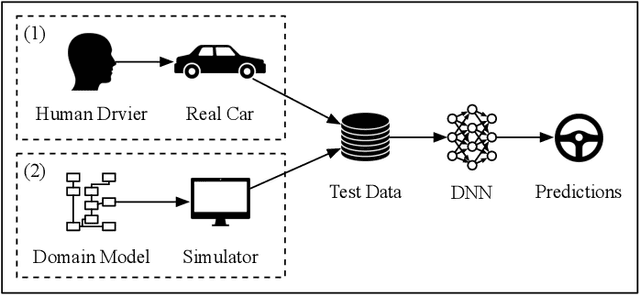
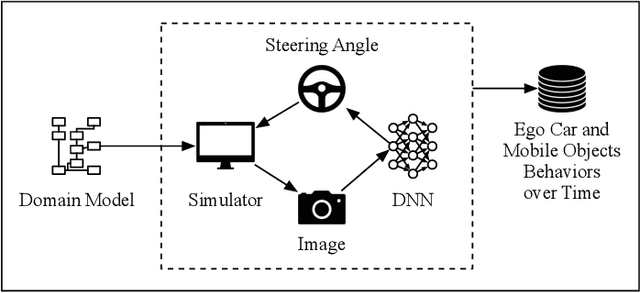
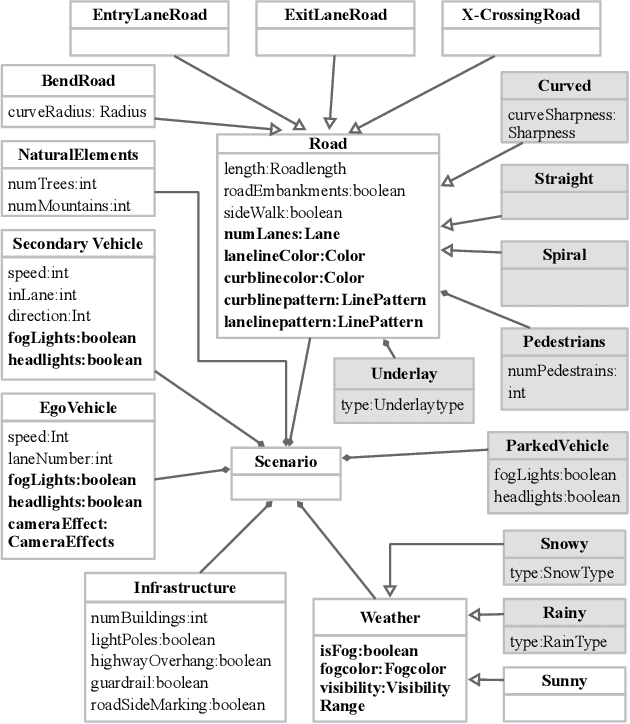
There is a growing body of research on developing testing techniques for Deep Neural Networks (DNN). We distinguish two general modes of testing for DNNs: Offline testing where DNNs are tested as individual units based on test datasets obtained independently from the DNNs under test, and online testing where DNNs are embedded into a specific application and tested in a close-loop mode in interaction with the application environment. In addition, we identify two sources for generating test datasets for DNNs: Datasets obtained from real-life and datasets generated by simulators. While offline testing can be used with datasets obtained from either sources, online testing is largely confined to using simulators since online testing within real-life applications can be time-consuming, expensive and dangerous. In this paper, we study the following two important questions aiming to compare test datasets and testing modes for DNNs: First, can we use simulator-generated data as a reliable substitute to real-world data for the purpose of DNN testing? Second, how do online and offline testing results differ and complement each other? Though these questions are generally relevant to all autonomous systems, we study them in the context of automated driving systems where, as study subjects, we use DNNs automating end-to-end control of cars' steering actuators. Our results show that simulator-generated datasets are able to yield DNN prediction errors that are similar to those obtained by testing DNNs with real-life datasets. Further, offline testing is more optimistic than online testing as many safety violations identified by online testing could not be identified by offline testing, while large prediction errors generated by offline testing always led to severe safety violations detectable by online testing.