 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Search-Based Testing with Pareto Optimization Effectively Cover Failure-Revealing Test Inputs?
Oct 15, 2024Search-based software testing (SBST) is a widely adopted technique for testing complex systems with large input spaces, such as Deep Learning-enabled (DL-enabled) systems. Many SBST techniques focus on Pareto-based optimization, where multiple objectives are optimized in parallel to reveal failures. However, it is important to ensure that identified failures are spread throughout the entire failure-inducing area of a search domain and not clustered in a sub-region. This ensures that identified failures are semantically diverse and reveal a wide range of underlying causes. In this paper, we present a theoretical argument explaining why testing based on Pareto optimization is inadequate for covering failure-inducing areas within a search domain. We support our argument with empirical results obtained by applying two widely used types of Pareto-based optimization techniques, namely NSGA-II (an evolutionary algorithm) and MOPSO (a swarm-based algorithm), to two DL-enabled systems: an industrial Automated Valet Parking (AVP) system and a system for classifying handwritten digits. We measure the coverage of failure-revealing test inputs in the input space using a metric that we refer to as the Coverage Inverted Distance quality indicator. Our results show that NSGA-II and MOPSO are not more effective than a na\"ive random search baseline in covering test inputs that reveal failures. The replication package for this study is available in a GitHub repository.
Bridging the Gap between Real-world and Synthetic Images for Testing Autonomous Driving Systems
Aug 25, 2024
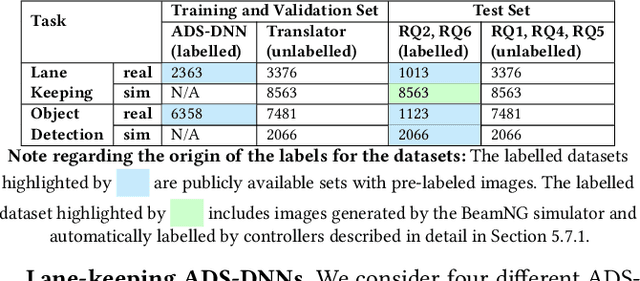
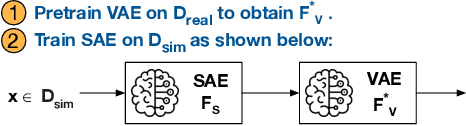
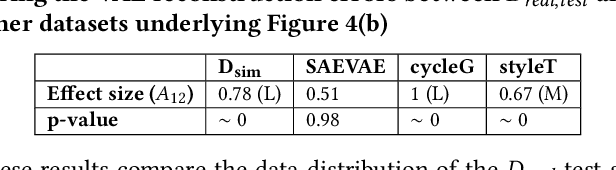
Deep Neural Networks (DNNs) for Autonomous Driving Systems (ADS) are typically trained on real-world images and tested using synthetic simulator images. This approach results in training and test datasets with dissimilar distributions, which can potentially lead to erroneously decreased test accuracy. To address this issue, the literature suggests applying domain-to-domain translators to test datasets to bring them closer to the training datasets. However, translating images used for testing may unpredictably affect the reliability, effectiveness and efficiency of the testing process. Hence, this paper investigates the following questions in the context of ADS: Could translators reduce the effectiveness of images used for ADS-DNN testing and their ability to reveal faults in ADS-DNNs? Can translators result in excessive time overhead during simulation-based testing? To address these questions, we consider three domain-to-domain translators: CycleGAN and neural style transfer, from the literature, and SAEVAE, our proposed translator. Our results for two critical ADS tasks -- lane keeping and object detection -- indicate that translators significantly narrow the gap in ADS test accuracy caused by distribution dissimilarities between training and test data, with SAEVAE outperforming the other two translators. We show that, based on the recent diversity, coverage, and fault-revealing ability metrics for testing deep-learning systems, translators do not compromise the diversity and the coverage of test data, nor do they lead to revealing fewer faults in ADS-DNNs. Further, among the translators considered, SAEVAE incurs a negligible overhead in simulation time and can be efficiently integrated into simulation-based testing. Finally, we show that translators increase the correlation between offline and simulation-based testing results, which can help reduce the cost of simulation-based testing.
Generating Minimalist Adversarial Perturbations to Test Object-Detection Models: An Adaptive Multi-Metric Evolutionary Search Approach
Apr 25, 2024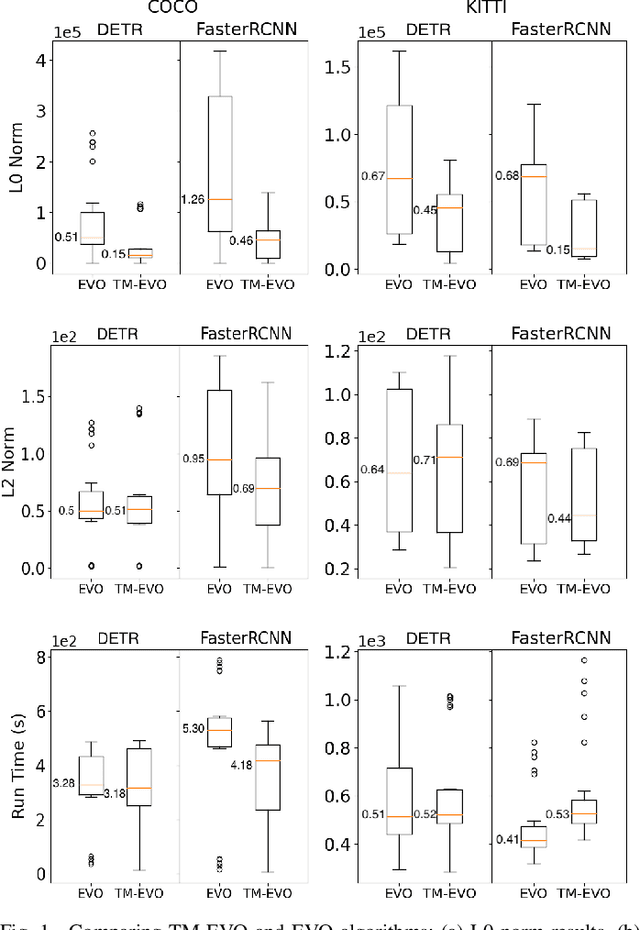
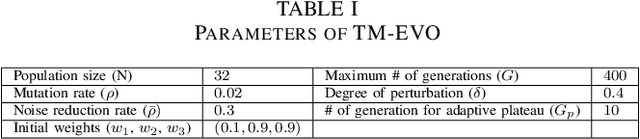
Deep Learning (DL) models excel in computer vision tasks but can be susceptible to adversarial examples. This paper introduces Triple-Metric EvoAttack (TM-EVO), an efficient algorithm for evaluating the robustness of object-detection DL models against adversarial attacks. TM-EVO utilizes a multi-metric fitness function to guide an evolutionary search efficiently in creating effective adversarial test inputs with minimal perturbations. We evaluate TM-EVO on widely-used object-detection DL models, DETR and Faster R-CNN, and open-source datasets, COCO and KITTI. Our findings reveal that TM-EVO outperforms the state-of-the-art EvoAttack baseline, leading to adversarial tests with less noise while maintaining efficiency.
Evaluating the Impact of Flaky Simulators on Testing Autonomous Driving Systems
Nov 30, 2023Simulators are widely used to test Autonomous Driving Systems (ADS), but their potential flakiness can lead to inconsistent test results. We investigate test flakiness in simulation-based testing of ADS by addressing two key questions: (1) How do flaky ADS simulations impact automated testing that relies on randomized algorithms? and (2) Can machine learning (ML) effectively identify flaky ADS tests while decreasing the required number of test reruns? Our empirical results, obtained from two widely-used open-source ADS simulators and five diverse ADS test setups, show that test flakiness in ADS is a common occurrence and can significantly impact the test results obtained by randomized algorithms. Further, our ML classifiers effectively identify flaky ADS tests using only a single test run, achieving F1-scores of $85$%, $82$% and $96$% for three different ADS test setups. Our classifiers significantly outperform our non-ML baseline, which requires executing tests at least twice, by $31$%, $21$%, and $13$% in F1-score performance, respectively. We conclude with a discussion on the scope, implications and limitations of our study. We provide our complete replication package in a Github repository.
Can Offline Testing of Deep Neural Networks Replace Their Online Testing?
Jan 26, 2021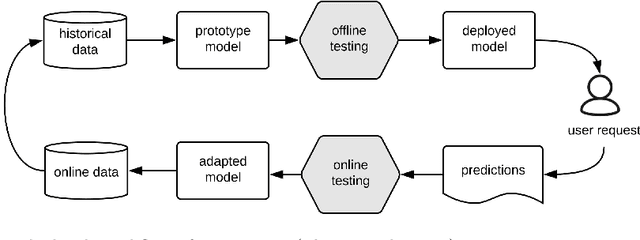
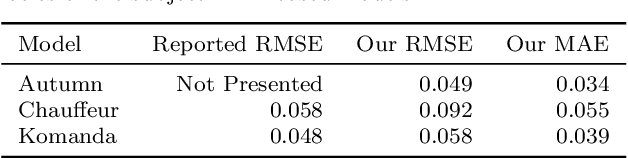
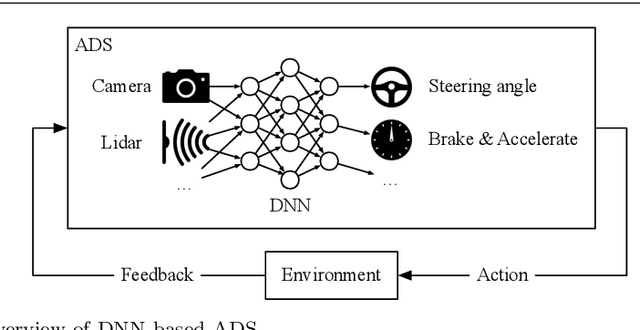
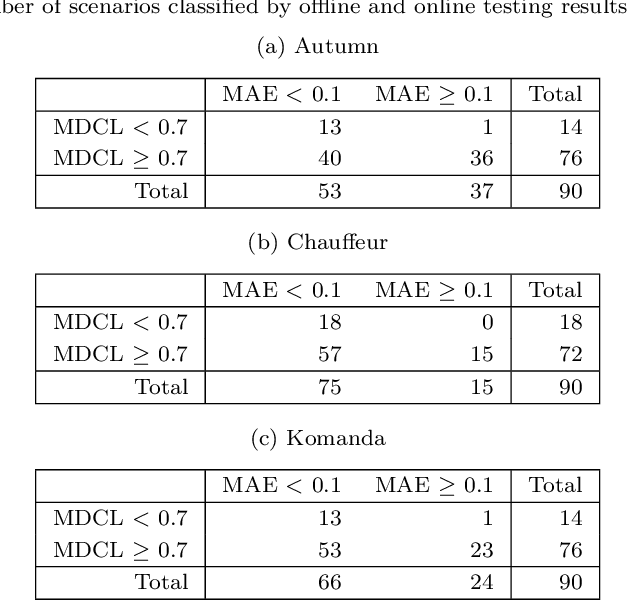
We distinguish two general modes of testing for Deep Neural Networks (DNNs): Offline testing where DNNs are tested as individual units based on test datasets obtained independently from the DNNs under test, and online testing where DNNs are embedded into a specific application environment and tested in a closed-loop mode in interaction with the application environment. Typically, DNNs are subjected to both types of testing during their development life cycle where offline testing is applied immediately after DNN training and online testing follows after offline testing and once a DNN is deployed within a specific application environment. In this paper, we study the relationship between offline and online testing. Our goal is to determine how offline testing and online testing differ or complement one another and if we can use offline testing results to run fewer tests during online testing to reduce the testing cost. Though these questions are generally relevant to all autonomous systems, we study them in the context of automated driving systems where, as study subjects, we use DNNs automating end-to-end controls of steering functions of self-driving vehicles. Our results show that offline testing is more optimistic than online testing as many safety violations identified by online testing could not be identified by offline testing, while large prediction errors generated by offline testing always led to severe safety violations detectable by online testing. Further, we cannot use offline testing results to run fewer tests during online testing in practice since we are not able to identify specific situations where offline testing could be as accurate as online testing in identifying safety requirement violations.
Digital Twins Are Not Monozygotic -- Cross-Replicating ADAS Testing in Two Industry-Grade Automotive Simulators
Dec 12, 2020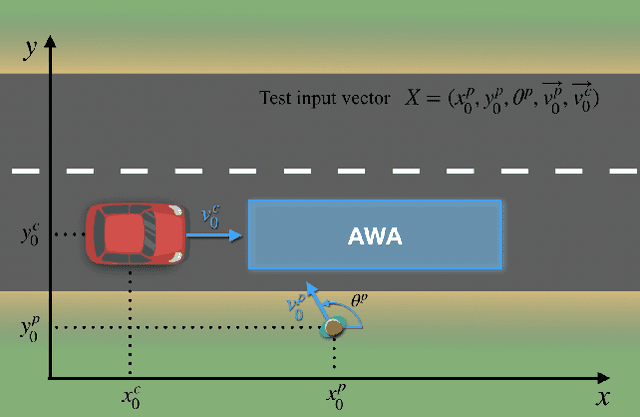
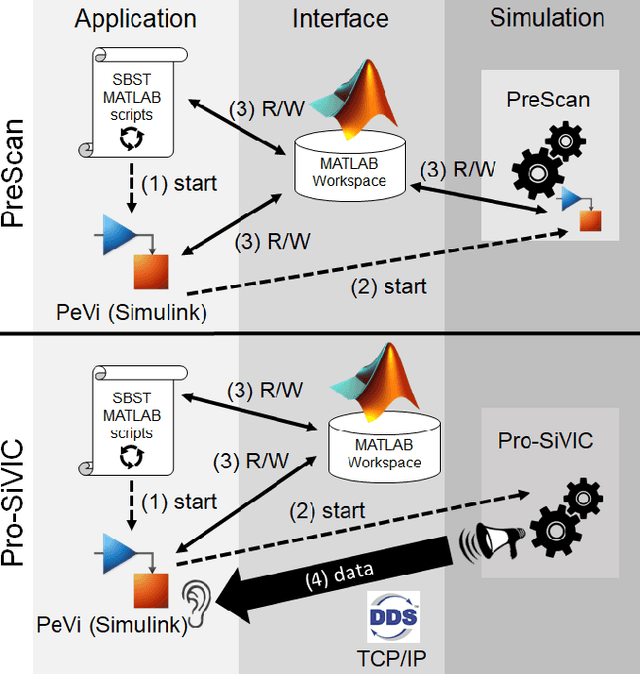

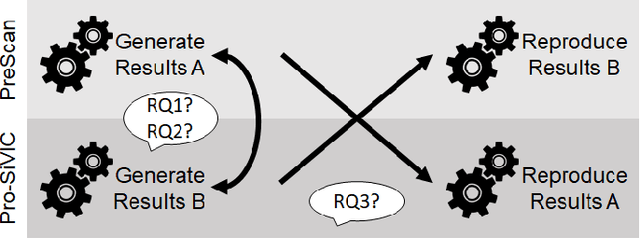
The increasing levels of software- and data-intensive driving automation call for an evolution of automotive software testing. As a recommended practice of the Verification and Validation (V&V) process of ISO/PAS 21448, a candidate standard for safety of the intended functionality for road vehicles, simulation-based testing has the potential to reduce both risks and costs. There is a growing body of research on devising test automation techniques using simulators for Advanced Driver-Assistance Systems (ADAS). However, how similar are the results if the same test scenarios are executed in different simulators? We conduct a replication study of applying a Search-Based Software Testing (SBST) solution to a real-world ADAS (PeVi, a pedestrian vision detection system) using two different commercial simulators, namely, TASS/Siemens PreScan and ESI Pro-SiVIC. Based on a minimalistic scene, we compare critical test scenarios generated using our SBST solution in these two simulators. We show that SBST can be used to effectively and efficiently generate critical test scenarios in both simulators, and the test results obtained from the two simulators can reveal several weaknesses of the ADAS under test. However, executing the same test scenarios in the two simulators leads to notable differences in the details of the test outputs, in particular, related to (1) safety violations revealed by tests, and (2) dynamics of cars and pedestrians. Based on our findings, we recommend future V&V plans to include multiple simulators to support robust simulation-based testing and to base test objectives on measures that are less dependant on the internals of the simulators.
Comparing Offline and Online Testing of Deep Neural Networks: An Autonomous Car Case Study
Nov 28, 2019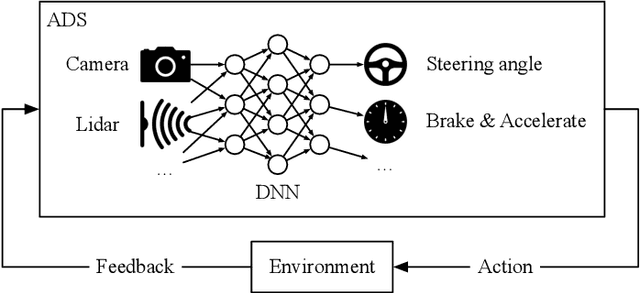
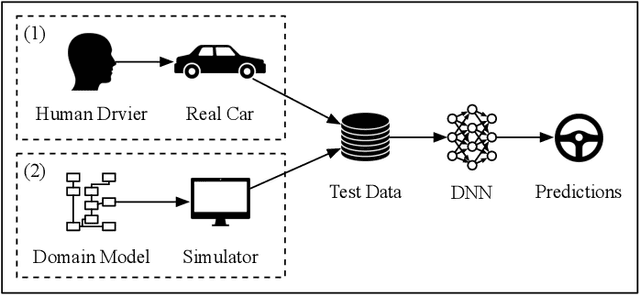
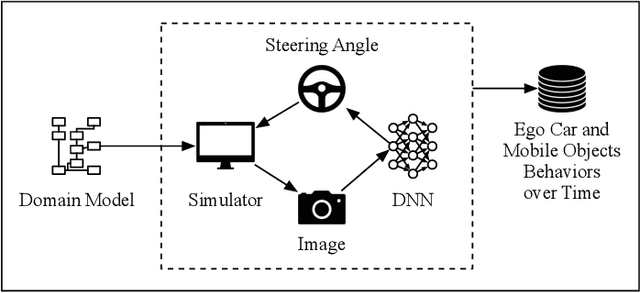
There is a growing body of research on developing testing techniques for Deep Neural Networks (DNN). We distinguish two general modes of testing for DNNs: Offline testing where DNNs are tested as individual units based on test datasets obtained independently from the DNNs under test, and online testing where DNNs are embedded into a specific application and tested in a close-loop mode in interaction with the application environment. In addition, we identify two sources for generating test datasets for DNNs: Datasets obtained from real-life and datasets generated by simulators. While offline testing can be used with datasets obtained from either sources, online testing is largely confined to using simulators since online testing within real-life applications can be time-consuming, expensive and dangerous. In this paper, we study the following two important questions aiming to compare test datasets and testing modes for DNNs: First, can we use simulator-generated data as a reliable substitute to real-world data for the purpose of DNN testing? Second, how do online and offline testing results differ and complement each other? Though these questions are generally relevant to all autonomous systems, we study them in the context of automated driving systems where, as study subjects, we use DNNs automating end-to-end control of cars' steering actuators. Our results show that simulator-generated datasets are able to yield DNN prediction errors that are similar to those obtained by testing DNNs with real-life datasets. Further, offline testing is more optimistic than online testing as many safety violations identified by online testing could not be identified by offline testing, while large prediction errors generated by offline testing always led to severe safety violations detectable by online testing.