 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Minimalist Adversarial Perturbations to Test Object-Detection Models: An Adaptive Multi-Metric Evolutionary Search Approach
Apr 25, 2024Deep Learning (DL) models excel in computer vision tasks but can be susceptible to adversarial examples. This paper introduces Triple-Metric EvoAttack (TM-EVO), an efficient algorithm for evaluating the robustness of object-detection DL models against adversarial attacks. TM-EVO utilizes a multi-metric fitness function to guide an evolutionary search efficiently in creating effective adversarial test inputs with minimal perturbations. We evaluate TM-EVO on widely-used object-detection DL models, DETR and Faster R-CNN, and open-source datasets, COCO and KITTI. Our findings reveal that TM-EVO outperforms the state-of-the-art EvoAttack baseline, leading to adversarial tests with less noise while maintaining efficiency.
Multi-Template Temporal Siamese Network for Long-Term Object Tracking
Nov 24, 2022



Siamese Networks are one of most popular visual object tracking methods for their high speed and high accuracy tracking ability as long as the target is well identified. However, most Siamese Network based trackers use the first frame as the ground truth of an object and fail when target appearance changes significantly in next frames. They also have dif iculty distinguishing the target from similar other objects in the frame. We propose two ideas to solve both problems. The first idea is using a bag of dynamic templates, containing diverse, similar, and recent target features and continuously updating it with diverse target appearances. The other idea is to let a network learn the path history and project a potential future target location in a next frame. This tracker achieves state-of-the-art performance on the long-term tracking dataset UAV20L by improving the success rate by a large margin of 15% (65.4 vs 56.6) compared to the state-of-the-art method, HiFT. The of icial python code of this paper is publicly available.
Deep Learning for Automatic Tracking of Tongue Surface in Real-time Ultrasound Videos, Landmarks instead of Contours
Mar 16, 2020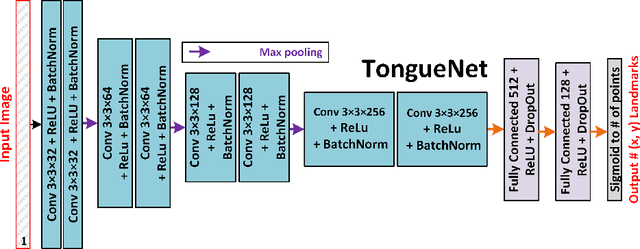


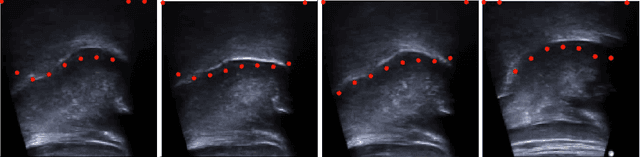
One usage of medical ultrasound imaging is to visualize and characterize human tongue shape and motion during a real-time speech to study healthy or impaired speech production. Due to the low-contrast characteristic and noisy nature of ultrasound images, it might require expertise for non-expert users to recognize tongue gestures in applications such as visual training of a second language. Moreover, quantitative analysis of tongue motion needs the tongue dorsum contour to be extracted, tracked, and visualized. Manual tongue contour extraction is a cumbersome, subjective, and error-prone task. Furthermore, it is not a feasible solution for real-time applications. The growth of deep learning has been vigorously exploited in various computer vision tasks, including ultrasound tongue contour tracking. In the current methods, the process of tongue contour extraction comprises two steps of image segmentation and post-processing. This paper presents a new novel approach of automatic and real-time tongue contour tracking using deep neural networks. In the proposed method, instead of the two-step procedure, landmarks of the tongue surface are tracked. This novel idea enables researchers in this filed to benefits from available previously annotated databases to achieve high accuracy results. Our experiment disclosed the outstanding performances of the proposed technique in terms of generalization, performance, and accuracy.
HRINet: Alternative Supervision Network for High-resolution CT image Interpolation
Feb 11, 2020



Image interpolation in medical area is of high importance as most 3D biomedical volume images are sampled where the distance between consecutive slices significantly greater than the in-plane pixel size due to radiation dose or scanning time. Image interpolation creates a number of new slices between known slices in order to obtain an isotropic volume image. The results can be used for the higher quality of 3D reconstruction and visualization of human body structures. Semantic interpolation on the manifold has been proved to be very useful for smoothing image interpolation. Nevertheless, all previous methods focused on low-resolution image interpolation, and most of them work poorly on high-resolution image. We propose a novel network, High Resolution Interpolation Network (HRINet), aiming at producing high-resolution CT image interpolations. We combine the idea of ACAI and GANs, and propose a novel idea of alternative supervision method by applying supervised and unsupervised training alternatively to raise the accuracy of human organ structures in CT while keeping high quality. We compare an MSE based and a perceptual based loss optimizing methods for high quality interpolation, and show the tradeoff between the structural correctness and sharpness. Our experiments show the great improvement on 256 2 and 5122 images quantitatively and qualitatively.
Real-time Ultrasound-enhanced Multimodal Imaging of Tongue using 3D Printable Stabilizer System: A Deep Learning Approach
Nov 22, 2019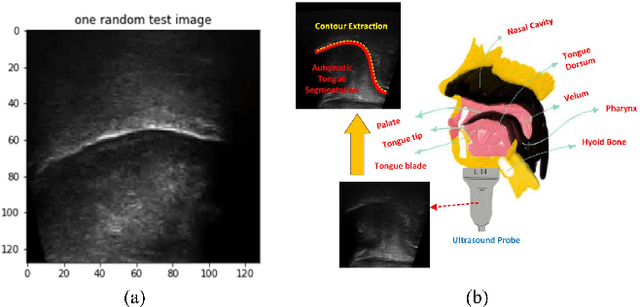

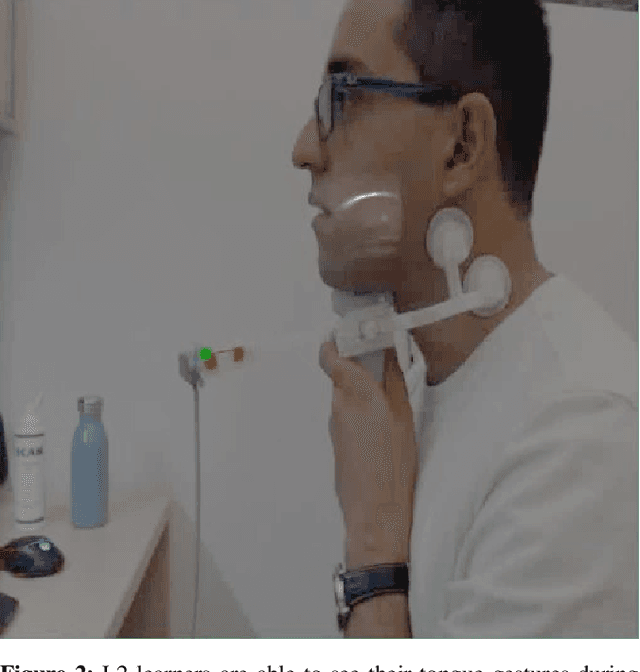

Despite renewed awareness of the importance of articulation, it remains a challenge for instructors to handle the pronunciation needs of language learners. There are relatively scarce pedagogical tools for pronunciation teaching and learning. Unlike inefficient, traditional pronunciation instructions like listening and repeating, electronic visual feedback (EVF) systems such as ultrasound technology have been employed in new approaches. Recently, an ultrasound-enhanced multimodal method has been developed for visualizing tongue movements of a language learner overlaid on the face-side of the speaker's head. That system was evaluated for several language courses via a blended learning paradigm at the university level. The result was asserted that visualizing the articulator's system as biofeedback to language learners will significantly improve articulation learning efficiency. In spite of the successful usage of multimodal techniques for pronunciation training, it still requires manual works and human manipulation. In this article, we aim to contribute to this growing body of research by addressing difficulties of the previous approaches by proposing a new comprehensive, automatic, real-time multimodal pronunciation training system, benefits from powerful artificial intelligence techniques. The main objective of this research was to combine the advantages of ultrasound technology, three-dimensional printing, and deep learning algorithms to enhance the performance of previous systems. Our preliminary pedagogical evaluation of the proposed system revealed a significant improvement in flexibility, control, robustness, and autonomy.
IrisNet: Deep Learning for Automatic and Real-time Tongue Contour Tracking in Ultrasound Video Data using Peripheral Vision
Nov 10, 2019
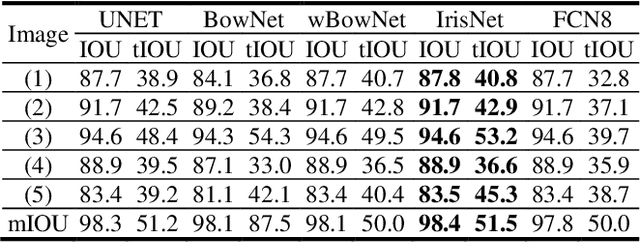


The progress of deep convolutional neural networks has been successfully exploited in various real-time computer vision tasks such as image classification and segmentation. Owing to the development of computational units, availability of digital datasets, and improved performance of deep learning models, fully automatic and accurate tracking of tongue contours in real-time ultrasound data became practical only in recent years. Recent studies have shown that the performance of deep learning techniques is significant in the tracking of ultrasound tongue contours in real-time applications such as pronunciation training using multimodal ultrasound-enhanced approaches. Due to the high correlation between ultrasound tongue datasets, it is feasible to have a general model that accomplishes automatic tongue tracking for almost all datasets. In this paper, we proposed a deep learning model comprises of a convolutional module mimicking the peripheral vision ability of the human eye to handle real-time, accurate, and fully automatic tongue contour tracking tasks, applicable for almost all primary ultrasound tongue datasets. Qualitative and quantitative assessment of IrisNet on different ultrasound tongue datasets and PASCAL VOC2012 revealed its outstanding generalization achievement in compare with similar techniques.
Transfer Learning for Ultrasound Tongue Contour Extraction with Different Domains
Jun 10, 2019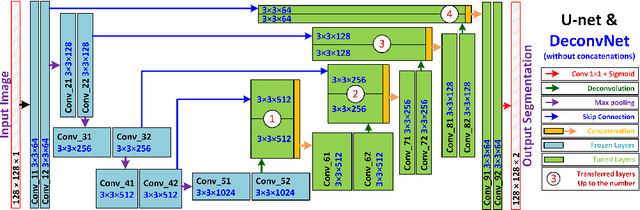
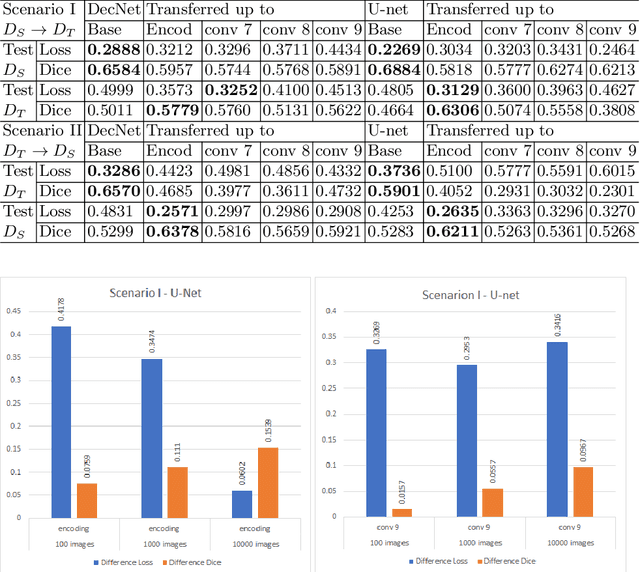
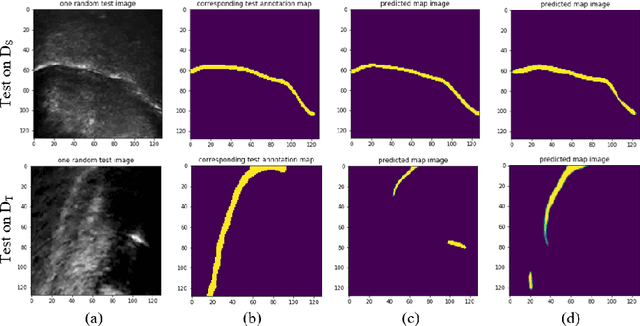
Medical ultrasound technology is widely used in routine clinical applications such as disease diagnosis and treatment as well as other applications like real-time monitoring of human tongue shapes and motions as visual feedback in second language training. Due to the low-contrast characteristic and noisy nature of ultrasound images, it might require expertise for non-expert users to recognize tongue gestures. Manual tongue segmentation is a cumbersome, subjective, and error-prone task. Furthermore, it is not a feasible solution for real-time applications. In the last few years, deep learning methods have been used for delineating and tracking tongue dorsum. Deep convolutional neural networks (DCNNs), which have shown to be successful in medical image analysis tasks, are typically weak for the same task on different domains. In many cases, DCNNs trained on data acquired with one ultrasound device, do not perform well on data of varying ultrasound device or acquisition protocol. Domain adaptation is an alternative solution for this difficulty by transferring the weights from the model trained on a large annotated legacy dataset to a new model for adapting on another different dataset using fine-tuning. In this study, after conducting extensive experiments, we addressed the problem of domain adaptation on small ultrasound datasets for tongue contour extraction. We trained a U-net network comprises of an encoder-decoder path from scratch, and then with several surrogate scenarios, some parts of the trained network were fine-tuned on another dataset as the domain-adapted networks. We repeat scenarios from target to source domains to find a balance point for knowledge transfer from source to target and vice versa. The performance of new fine-tuned networks was evaluated on the same task with images from different domains.
BowNet: Dilated Convolution Neural Network for Ultrasound Tongue Contour Extraction
Jun 10, 2019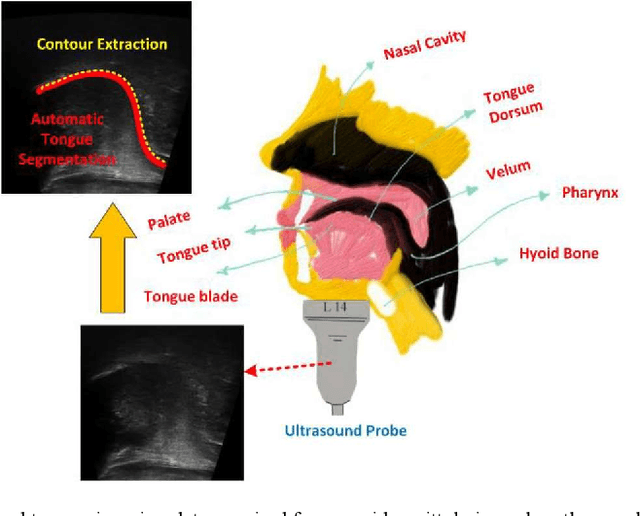
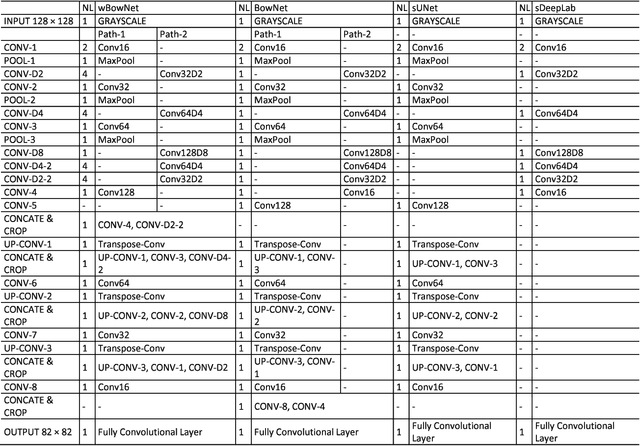
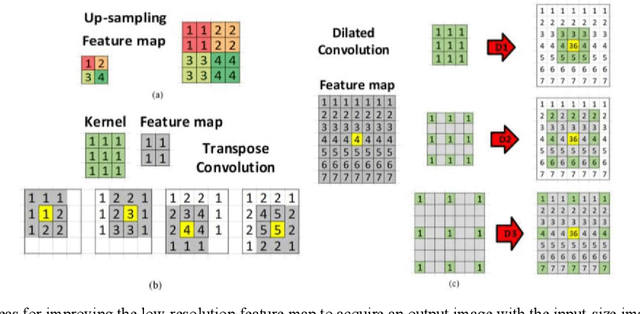
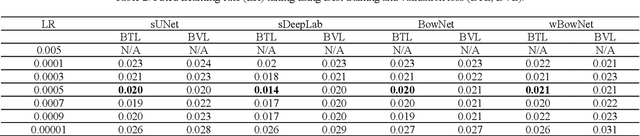
Ultrasound imaging is safe, relatively affordable, and capable of real-time performance. One application of this technology is to visualize and to characterize human tongue shape and motion during a real-time speech to study healthy or impaired speech production. Due to the noisy nature of ultrasound images with low-contrast characteristic, it might require expertise for non-expert users to recognize organ shape such as tongue surface (dorsum). To alleviate this difficulty for quantitative analysis of tongue shape and motion, tongue surface can be extracted, tracked, and visualized instead of the whole tongue region. Delineating the tongue surface from each frame is a cumbersome, subjective, and error-prone task. Furthermore, the rapidity and complexity of tongue gestures have made it a challenging task, and manual segmentation is not a feasible solution for real-time applications. Employing the power of state-of-the-art deep neural network models and training techniques, it is feasible to implement new fully-automatic, accurate, and robust segmentation methods with the capability of real-time performance, applicable for tracking of the tongue contours during the speech. This paper presents two novel deep neural network models named BowNet and wBowNet benefits from the ability of global prediction of decoding-encoding models, with integrated multi-scale contextual information, and capability of full-resolution (local) extraction of dilated convolutions. Experimental results using several ultrasound tongue image datasets revealed that the combination of both localization and globalization searching could improve prediction result significantly. Assessment of BowNet models using both qualitatively and quantitatively studies showed them outstanding achievements in terms of accuracy and robustness in comparison with similar techniques.
Multi-Objective Design of State Feedback Controllers Using Reinforced Quantum-Behaved Particle Swarm Optimization
Jul 04, 2016



In this paper, a novel and generic multi-objective design paradigm is proposed which utilizes quantum-behaved PSO(QPSO) for deciding the optimal configuration of the LQR controller for a given problem considering a set of competing objectives. There are three main contributions introduced in this paper as follows. (1) The standard QPSO algorithm is reinforced with an informed initialization scheme based on the simulated annealing algorithm and Gaussian neighborhood selection mechanism. (2) It is also augmented with a local search strategy which integrates the advantages of memetic algorithm into conventional QPSO. (3) An aggregated dynamic weighting criterion is introduced that dynamically combines the soft and hard constraints with control objectives to provide the designer with a set of Pareto optimal solutions and lets her to decide the target solution based on practical preferences. The proposed method is compared against a gradient-based method, seven meta-heuristics, and the trial-and-error method on two control benchmarks using sensitivity analysis and full factorial parameter selection and the results are validated using one-tailed T-test. The experimental results suggest that the proposed method outperforms opponent methods in terms of controller effort, measures associated with transient response and criteria related to steady-state.
Visualizing Natural Language Descriptions: A Survey
Jul 03, 2016
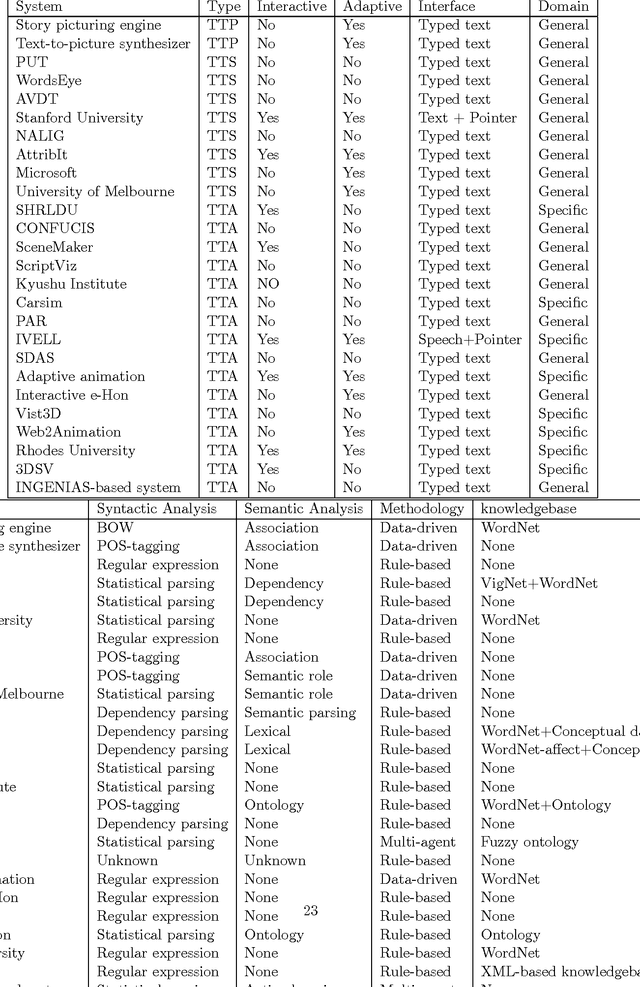

A natural language interface exploits the conceptual simplicity and naturalness of the language to create a high-level user-friendly communication channel between humans and machines. One of the promising applications of such interfaces is generating visual interpretations of semantic content of a given natural language that can be then visualized either as a static scene or a dynamic animation. This survey discusses requirements and challenges of developing such systems and reports 26 graphical systems that exploit natural language interfaces and addresses both artificial intelligence and visualization aspects. This work serves as a frame of reference to researchers and to enable further advances in the field.
* Due to copyright most of the figures only appear in the journal version