 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBowNet: Dilated Convolution Neural Network for Ultrasound Tongue Contour Extraction
Paper and Code
Jun 10, 2019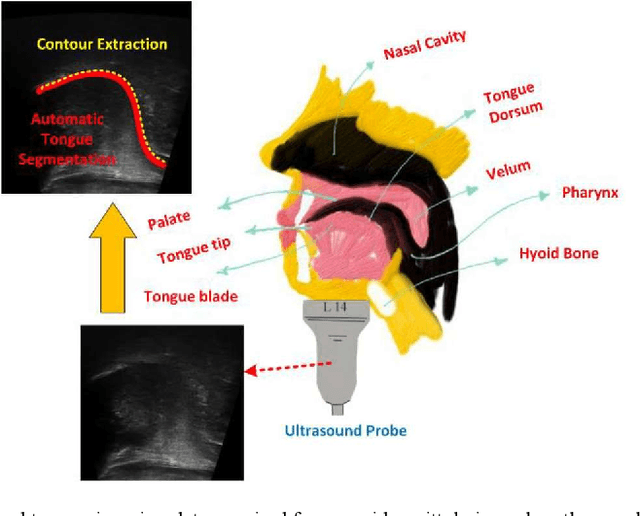
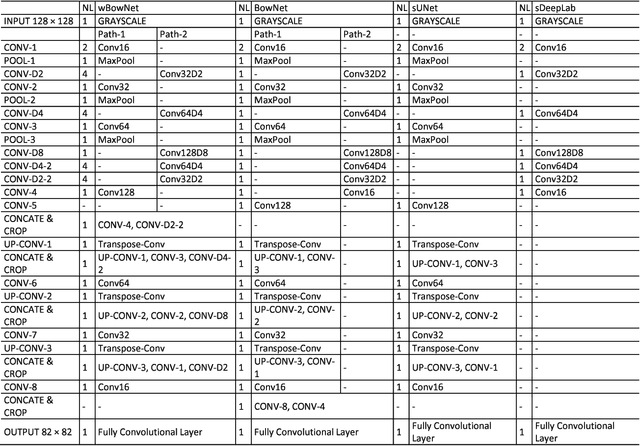
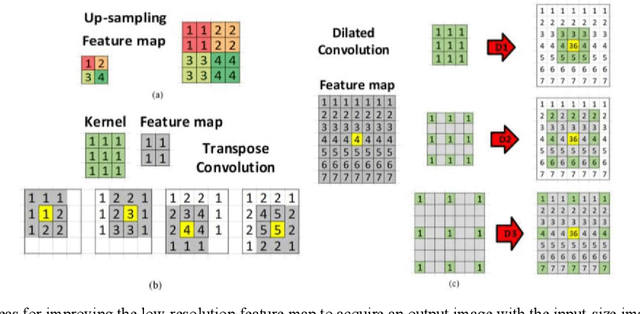
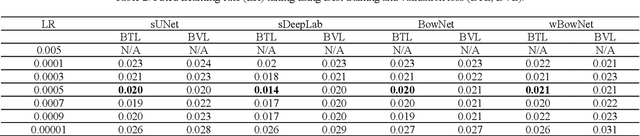
Ultrasound imaging is safe, relatively affordable, and capable of real-time performance. One application of this technology is to visualize and to characterize human tongue shape and motion during a real-time speech to study healthy or impaired speech production. Due to the noisy nature of ultrasound images with low-contrast characteristic, it might require expertise for non-expert users to recognize organ shape such as tongue surface (dorsum). To alleviate this difficulty for quantitative analysis of tongue shape and motion, tongue surface can be extracted, tracked, and visualized instead of the whole tongue region. Delineating the tongue surface from each frame is a cumbersome, subjective, and error-prone task. Furthermore, the rapidity and complexity of tongue gestures have made it a challenging task, and manual segmentation is not a feasible solution for real-time applications. Employing the power of state-of-the-art deep neural network models and training techniques, it is feasible to implement new fully-automatic, accurate, and robust segmentation methods with the capability of real-time performance, applicable for tracking of the tongue contours during the speech. This paper presents two novel deep neural network models named BowNet and wBowNet benefits from the ability of global prediction of decoding-encoding models, with integrated multi-scale contextual information, and capability of full-resolution (local) extraction of dilated convolutions. Experimental results using several ultrasound tongue image datasets revealed that the combination of both localization and globalization searching could improve prediction result significantly. Assessment of BowNet models using both qualitatively and quantitatively studies showed them outstanding achievements in terms of accuracy and robustness in comparison with similar techniques.