 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit Assignment with Resets in Language Model Reasoning
May 26, 2026Contemporary reinforcement learning with verifiable reward methods post-train language models on multi-step reasoning by assigning a single outcome reward uniformly across all tokens in a trajectory. Such uniform assignment ignores which steps contributed to success or failure. Improving credit assignment can address this limitation by enabling targeted refinement of faulty reasoning steps, rather than updating entire trajectories uniformly. Resets are one such simple mechanism, enabling more precise credit assignment by returning to an intermediate state and resampling counterfactual continuations, so that outcome differences can be attributed to decisions made at that point. We propose two such methods: Random-Reset Policy Optimization (RRPO), where reset states are drawn randomly from reasoning steps, and Self-Reset Policy Optimization (SRPO), where the model self-localizes the erroneous step in an incorrect trajectory and resets there. We analyze these methods within the Conservative Policy Iteration (CPI) framework. Extending CPI with a credit-assignment oracle that targets improvable states yields provable improvements over random resets. Across models and reasoning benchmarks, SRPO consistently outperforms standard GRPO and RRPO by sampling multiple suffix continuations at a self-localized reset and learning from their rewards, using only the model itself with no external supervision.
Multimodal Generative Recommendation for Fusing Semantic and Collaborative Signals
Feb 03, 2026Sequential recommender systems rank relevant items by modeling a user's interaction history and computing the inner product between the resulting user representation and stored item embeddings. To avoid the significant memory overhead of storing large item sets, the generative recommendation paradigm instead models each item as a series of discrete semantic codes. Here, the next item is predicted by an autoregressive model that generates the code sequence corresponding to the predicted item. However, despite promising ranking capabilities on small datasets, these methods have yet to surpass traditional sequential recommenders on large item sets, limiting their adoption in the very scenarios they were designed to address. To resolve this, we propose MSCGRec, a Multimodal Semantic and Collaborative Generative Recommender. MSCGRec incorporates multiple semantic modalities and introduces a novel self-supervised quantization learning approach for images based on the DINO framework. Additionally, MSCGRec fuses collaborative and semantic signals by extracting collaborative features from sequential recommenders and treating them as a separate modality. Finally, we propose constrained sequence learning that restricts the large output space during training to the set of permissible tokens. We empirically demonstrate on three large real-world datasets that MSCGRec outperforms both sequential and generative recommendation baselines and provide an extensive ablation study to validate the impact of each component.
Structure Enables Effective Self-Localization of Errors in LLMs
Feb 02, 2026Self-correction in language models remains elusive. In this work, we explore whether language models can explicitly localize errors in incorrect reasoning, as a path toward building AI systems that can effectively correct themselves. We introduce a prompting method that structures reasoning as discrete, semantically coherent thought steps, and show that models are able to reliably localize errors within this structure, while failing to do so in conventional, unstructured chain-of-thought reasoning. Motivated by how the human brain monitors errors at discrete decision points and resamples alternatives, we introduce Iterative Correction Sampling of Thoughts (Thought-ICS), a self-correction framework. Thought-ICS iteratively prompts the model to generate reasoning one discrete and complete thought at a time--where each thought represents a deliberate decision by the model--creating natural boundaries for precise error localization. Upon verification, the model localizes the first erroneous step, and the system backtracks to generate alternative reasoning from the last correct point. When asked to correct reasoning verified as incorrect by an oracle, Thought-ICS achieves 20-40% self-correction lift. In a completely autonomous setting without external verification, it outperforms contemporary self-correction baselines.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Imbalanced Gradients in RL Post-Training of Multi-Task LLMs
Oct 22, 2025Multi-task post-training of large language models (LLMs) is typically performed by mixing datasets from different tasks and optimizing them jointly. This approach implicitly assumes that all tasks contribute gradients of similar magnitudes; when this assumption fails, optimization becomes biased toward large-gradient tasks. In this paper, however, we show that this assumption fails in RL post-training: certain tasks produce significantly larger gradients, thus biasing updates toward those tasks. Such gradient imbalance would be justified only if larger gradients implied larger learning gains on the tasks (i.e., larger performance improvements) -- but we find this is not true. Large-gradient tasks can achieve similar or even much lower learning gains than small-gradient ones. Further analyses reveal that these gradient imbalances cannot be explained by typical training statistics such as training rewards or advantages, suggesting that they arise from the inherent differences between tasks. This cautions against naive dataset mixing and calls for future work on principled gradient-level corrections for LLMs.
Internalizing Self-Consistency in Language Models: Multi-Agent Consensus Alignment
Sep 18, 2025



Language Models (LMs) are inconsistent reasoners, often generating contradictory responses to identical prompts. While inference-time methods can mitigate these inconsistencies, they fail to address the core problem: LMs struggle to reliably select reasoning pathways leading to consistent outcomes under exploratory sampling. To address this, we formalize self-consistency as an intrinsic property of well-aligned reasoning models and introduce Multi-Agent Consensus Alignment (MACA), a reinforcement learning framework that post-trains models to favor reasoning trajectories aligned with their internal consensus using majority/minority outcomes from multi-agent debate. These trajectories emerge from deliberative exchanges where agents ground reasoning in peer arguments, not just aggregation of independent attempts, creating richer consensus signals than single-round majority voting. MACA enables agents to teach themselves to be more decisive and concise, and better leverage peer insights in multi-agent settings without external supervision, driving substantial improvements across self-consistency (+27.6% on GSM8K), single-agent reasoning (+23.7% on MATH), sampling-based inference (+22.4% Pass@20 on MATH), and multi-agent ensemble decision-making (+42.7% on MathQA). These findings, coupled with strong generalization to unseen benchmarks (+16.3% on GPQA, +11.6% on CommonsenseQA), demonstrate robust self-alignment that more reliably unlocks latent reasoning potential of language models.
Generating Long Semantic IDs in Parallel for Recommendation
Jun 06, 2025Semantic ID-based recommendation models tokenize each item into a small number of discrete tokens that preserve specific semantics, leading to better performance, scalability, and memory efficiency. While recent models adopt a generative approach, they often suffer from inefficient inference due to the reliance on resource-intensive beam search and multiple forward passes through the neural sequence model. As a result, the length of semantic IDs is typically restricted (e.g. to just 4 tokens), limiting their expressiveness. To address these challenges, we propose RPG, a lightweight framework for semantic ID-based recommendation. The key idea is to produce unordered, long semantic IDs, allowing the model to predict all tokens in parallel. We train the model to predict each token independently using a multi-token prediction loss, directly integrating semantics into the learning objective. During inference, we construct a graph connecting similar semantic IDs and guide decoding to avoid generating invalid IDs. Experiments show that scaling up semantic ID length to 64 enables RPG to outperform generative baselines by an average of 12.6% on the NDCG@10, while also improving inference efficiency. Code is available at: https://github.com/facebookresearch/RPG_KDD2025.
Higher-order Structure Boosts Link Prediction on Temporal Graphs
May 21, 2025Temporal Graph Neural Networks (TGNNs) have gained growing attention for modeling and predicting structures in temporal graphs. However, existing TGNNs primarily focus on pairwise interactions while overlooking higher-order structures that are integral to link formation and evolution in real-world temporal graphs. Meanwhile, these models often suffer from efficiency bottlenecks, further limiting their expressive power. To tackle these challenges, we propose a Higher-order structure Temporal Graph Neural Network, which incorporates hypergraph representations into temporal graph learning. In particular, we develop an algorithm to identify the underlying higher-order structures, enhancing the model's ability to capture the group interactions. Furthermore, by aggregating multiple edge features into hyperedge representations, HTGN effectively reduces memory cost during training. We theoretically demonstrate the enhanced expressiveness of our approach and validate its effectiveness and efficiency through extensive experiments on various real-world temporal graphs. Experimental results show that HTGN achieves superior performance on dynamic link prediction while reducing memory costs by up to 50\% compared to existing methods.
Preference Discerning with LLM-Enhanced Generative Retrieval
Dec 11, 2024



Sequential recommendation systems aim to provide personalized recommendations for users based on their interaction history. To achieve this, they often incorporate auxiliary information, such as textual descriptions of items and auxiliary tasks, like predicting user preferences and intent. Despite numerous efforts to enhance these models, they still suffer from limited personalization. To address this issue, we propose a new paradigm, which we term preference discerning. In preference dscerning, we explicitly condition a generative sequential recommendation system on user preferences within its context. To this end, we generate user preferences using Large Language Models (LLMs) based on user reviews and item-specific data. To evaluate preference discerning capabilities of sequential recommendation systems, we introduce a novel benchmark that provides a holistic evaluation across various scenarios, including preference steering and sentiment following. We assess current state-of-the-art methods using our benchmark and show that they struggle to accurately discern user preferences. Therefore, we propose a new method named Mender ($\textbf{M}$ultimodal Prefer$\textbf{en}$ce $\textbf{d}$iscern$\textbf{er}$), which improves upon existing methods and achieves state-of-the-art performance on our benchmark. Our results show that Mender can be effectively guided by human preferences even though they have not been observed during training, paving the way toward more personalized sequential recommendation systems. We will open-source the code and benchmarks upon publication.
Unifying Generative and Dense Retrieval for Sequential Recommendation
Nov 27, 2024

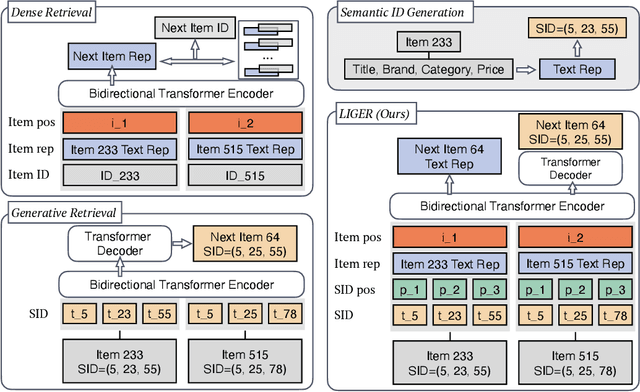
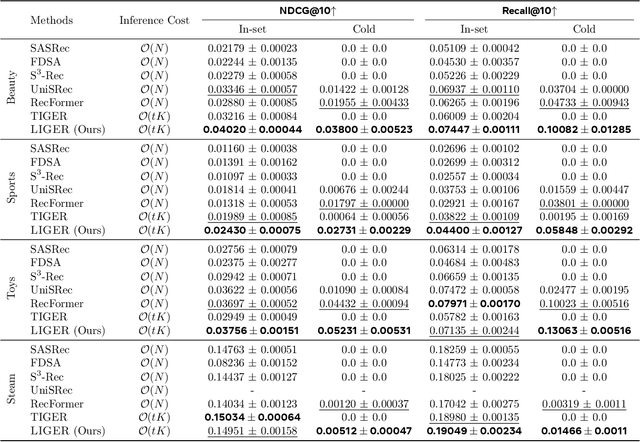
Sequential dense retrieval models utilize advanced sequence learning techniques to compute item and user representations, which are then used to rank relevant items for a user through inner product computation between the user and all item representations. However, this approach requires storing a unique representation for each item, resulting in significant memory requirements as the number of items grow. In contrast, the recently proposed generative retrieval paradigm offers a promising alternative by directly predicting item indices using a generative model trained on semantic IDs that encapsulate items' semantic information. Despite its potential for large-scale applications, a comprehensive comparison between generative retrieval and sequential dense retrieval under fair conditions is still lacking, leaving open questions regarding performance, and computation trade-offs. To address this, we compare these two approaches under controlled conditions on academic benchmarks and propose LIGER (LeveragIng dense retrieval for GEnerative Retrieval), a hybrid model that combines the strengths of these two widely used methods. LIGER integrates sequential dense retrieval into generative retrieval, mitigating performance differences and enhancing cold-start item recommendation in the datasets evaluated. This hybrid approach provides insights into the trade-offs between these approaches and demonstrates improvements in efficiency and effectiveness for recommendation systems in small-scale benchmarks.