 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedER: Seed-and-Expand Retrieval from Knowledge Graphs
May 22, 2026Knowledge graphs (KGs) offer a rich representation for relational knowledge, but their irregular structure makes retrieval challenging: ego-graph expansion grows rapidly, and dense embedding methods struggle with multi-hop compositional queries. Existing agent-based graph exploration approaches, while expressive, are often too expensive for large-scale retrieval. We introduce SeedER (Seed-and-Expand Retrieval), a retrieval framework that explicitly leverages KG structure through iterative, low-cost expansion. SeedER first seeds a compact set of core nodes using lightweight dense and entity-based retrieval, then selectively expands this set via a learned graph-aware policy trained with reinforcement learning. This design decomposes global reasoning into reusable local decisions, enabling efficient discovery of query-relevant nodes while tightly controlling expansion cost. We show theoretical limitations of dense retrieval on compositional graph queries, and establish advantages of SeedER from both compositional generalization and graph-constrained submodular optimization perspectives. Empirically, SeedER substantially improves recall with compact candidate sets over strong dense and graph-augmented baselines, making it an effective first-stage retriever for knowledge-intensive reasoning systems.
TxPert: Leveraging Biochemical Relationships for Out-of-Distribution Transcriptomic Perturbation Prediction
May 20, 2025Accurately predicting cellular responses to genetic perturbations is essential for understanding disease mechanisms and designing effective therapies. Yet exhaustively exploring the space of possible perturbations (e.g., multi-gene perturbations or across tissues and cell types) is prohibitively expensive, motivating methods that can generalize to unseen conditions. In this work, we explore how knowledge graphs of gene-gene relationships can improve out-of-distribution (OOD) prediction across three challenging settings: unseen single perturbations; unseen double perturbations; and unseen cell lines. In particular, we present: (i) TxPert, a new state-of-the-art method that leverages multiple biological knowledge networks to predict transcriptional responses under OOD scenarios; (ii) an in-depth analysis demonstrating the impact of graphs, model architecture, and data on performance; and (iii) an expanded benchmarking framework that strengthens evaluation standards for perturbation modeling.
Even Sparser Graph Transformers
Nov 25, 2024



Graph Transformers excel in long-range dependency modeling, but generally require quadratic memory complexity in the number of nodes in an input graph, and hence have trouble scaling to large graphs. Sparse attention variants such as Exphormer can help, but may require high-degree augmentations to the input graph for good performance, and do not attempt to sparsify an already-dense input graph. As the learned attention mechanisms tend to use few of these edges, such high-degree connections may be unnecessary. We show (empirically and with theoretical backing) that attention scores on graphs are usually quite consistent across network widths, and use this observation to propose a two-stage procedure, which we call Spexphormer: first, train a narrow network on the full augmented graph. Next, use only the active connections to train a wider network on a much sparser graph. We establish theoretical conditions when a narrow network's attention scores can match those of a wide network, and show that Spexphormer achieves good performance with drastically reduced memory requirements on various graph datasets.
A Theory for Compressibility of Graph Transformers for Transductive Learning
Nov 20, 2024



Transductive tasks on graphs differ fundamentally from typical supervised machine learning tasks, as the independent and identically distributed (i.i.d.) assumption does not hold among samples. Instead, all train/test/validation samples are present during training, making them more akin to a semi-supervised task. These differences make the analysis of the models substantially different from other models. Recently, Graph Transformers have significantly improved results on these datasets by overcoming long-range dependency problems. However, the quadratic complexity of full Transformers has driven the community to explore more efficient variants, such as those with sparser attention patterns. While the attention matrix has been extensively discussed, the hidden dimension or width of the network has received less attention. In this work, we establish some theoretical bounds on how and under what conditions the hidden dimension of these networks can be compressed. Our results apply to both sparse and dense variants of Graph Transformers.
Exphormer: Sparse Transformers for Graphs
Mar 10, 2023



Graph transformers have emerged as a promising architecture for a variety of graph learning and representation tasks. Despite their successes, though, it remains challenging to scale graph transformers to large graphs while maintaining accuracy competitive with message-passing networks. In this paper, we introduce Exphormer, a framework for building powerful and scalable graph transformers. Exphormer consists of a sparse attention mechanism based on two mechanisms: virtual global nodes and expander graphs, whose mathematical characteristics, such as spectral expansion, pseduorandomness, and sparsity, yield graph transformers with complexity only linear in the size of the graph, while allowing us to prove desirable theoretical properties of the resulting transformer models. We show that incorporating \textsc{Exphormer} into the recently-proposed GraphGPS framework produces models with competitive empirical results on a wide variety of graph datasets, including state-of-the-art results on three datasets. We also show that \textsc{Exphormer} can scale to datasets on larger graphs than shown in previous graph transformer architectures. Code can be found at https://github.com/hamed1375/Exphormer.
Evaluating Graph Generative Models with Contrastively Learned Features
Jun 13, 2022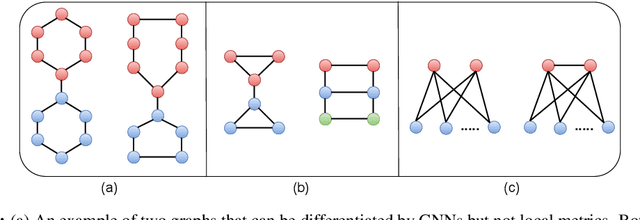
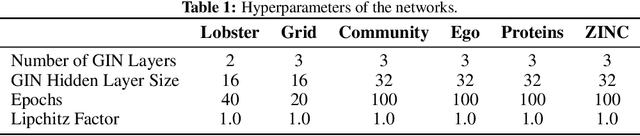
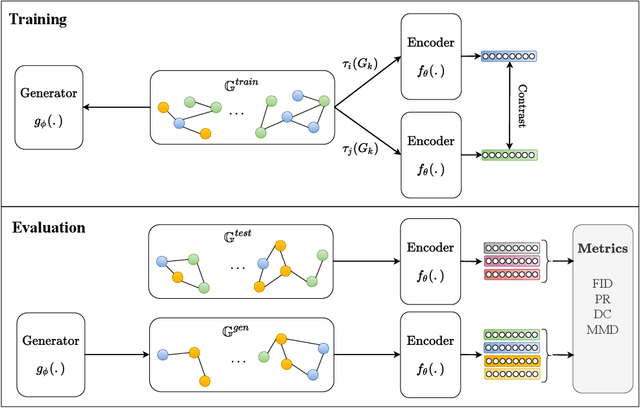
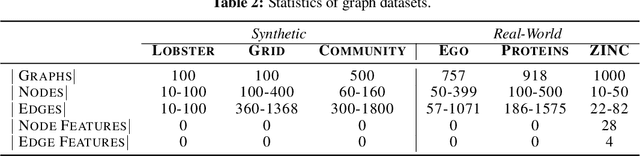
A wide range of models have been proposed for Graph Generative Models, necessitating effective methods to evaluate their quality. So far, most techniques use either traditional metrics based on subgraph counting, or the representations of randomly initialized Graph Neural Networks (GNNs). We propose using representations from contrastively trained GNNs, rather than random GNNs, and show this gives more reliable evaluation metrics. Neither traditional approaches nor GNN-based approaches dominate the other, however: we give examples of graphs that each approach is unable to distinguish. We demonstrate that Graph Substructure Networks (GSNs), which in a way combine both approaches, are better at distinguishing the distances between graph datasets.
TD-GEN: Graph Generation With Tree Decomposition
Jun 20, 2021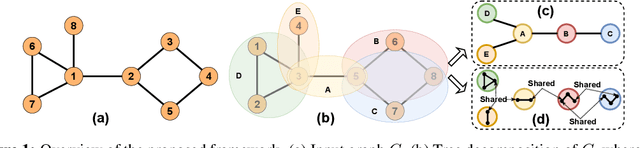
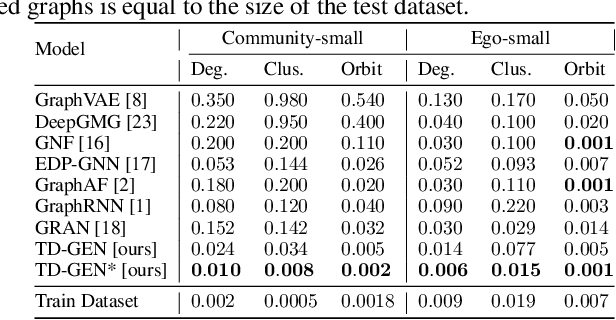
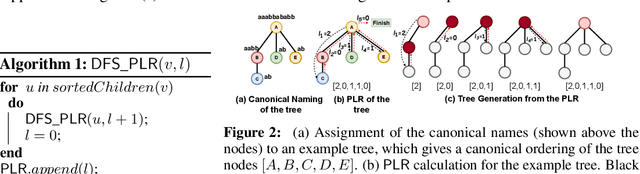
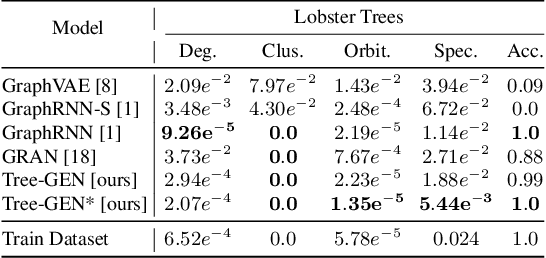
We propose TD-GEN, a graph generation framework based on tree decomposition, and introduce a reduced upper bound on the maximum number of decisions needed for graph generation. The framework includes a permutation invariant tree generation model which forms the backbone of graph generation. Tree nodes are supernodes, each representing a cluster of nodes in the graph. Graph nodes and edges are incrementally generated inside the clusters by traversing the tree supernodes, respecting the structure of the tree decomposition, and following node sharing decisions between the clusters. Finally, we discuss the shortcomings of standard evaluation criteria based on statistical properties of the generated graphs as performance measures. We propose to compare the performance of models based on likelihood. Empirical results on a variety of standard graph generation datasets demonstrate the superior performance of our method.