 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Long Semantic IDs in Parallel for Recommendation
Jun 06, 2025Semantic ID-based recommendation models tokenize each item into a small number of discrete tokens that preserve specific semantics, leading to better performance, scalability, and memory efficiency. While recent models adopt a generative approach, they often suffer from inefficient inference due to the reliance on resource-intensive beam search and multiple forward passes through the neural sequence model. As a result, the length of semantic IDs is typically restricted (e.g. to just 4 tokens), limiting their expressiveness. To address these challenges, we propose RPG, a lightweight framework for semantic ID-based recommendation. The key idea is to produce unordered, long semantic IDs, allowing the model to predict all tokens in parallel. We train the model to predict each token independently using a multi-token prediction loss, directly integrating semantics into the learning objective. During inference, we construct a graph connecting similar semantic IDs and guide decoding to avoid generating invalid IDs. Experiments show that scaling up semantic ID length to 64 enables RPG to outperform generative baselines by an average of 12.6% on the NDCG@10, while also improving inference efficiency. Code is available at: https://github.com/facebookresearch/RPG_KDD2025.
Learning Graph Quantized Tokenizers for Transformers
Oct 17, 2024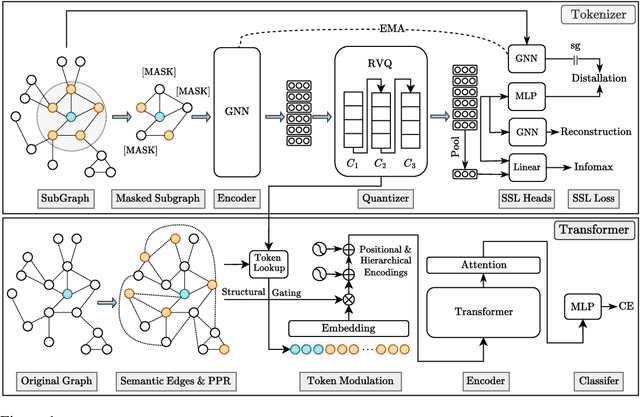
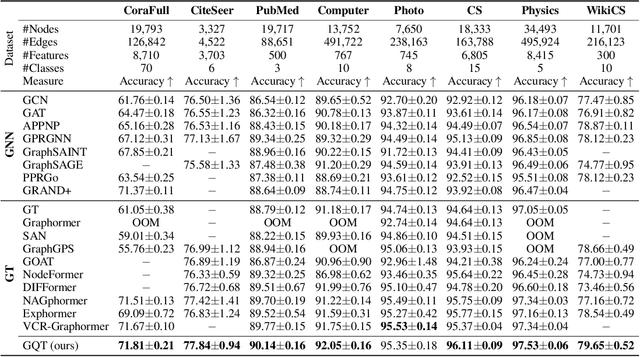
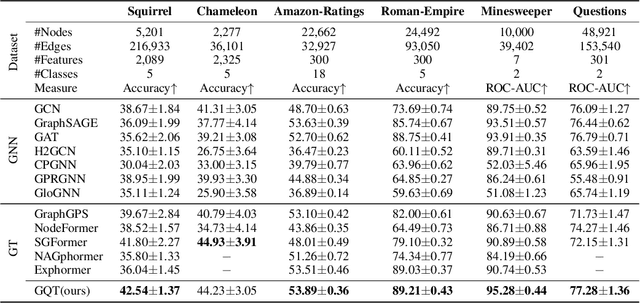
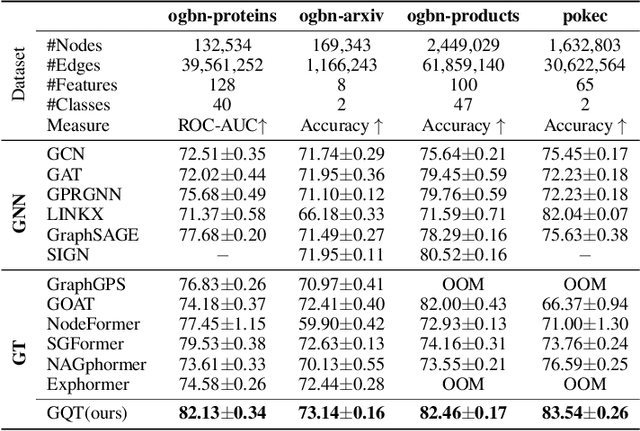
Transformers serve as the backbone architectures of Foundational Models, where a domain-specific tokenizer helps them adapt to various domains. Graph Transformers (GTs) have recently emerged as a leading model in geometric deep learning, outperforming Graph Neural Networks (GNNs) in various graph learning tasks. However, the development of tokenizers for graphs has lagged behind other modalities, with existing approaches relying on heuristics or GNNs co-trained with Transformers. To address this, we introduce GQT (\textbf{G}raph \textbf{Q}uantized \textbf{T}okenizer), which decouples tokenizer training from Transformer training by leveraging multi-task graph self-supervised learning, yielding robust and generalizable graph tokens. Furthermore, the GQT utilizes Residual Vector Quantization (RVQ) to learn hierarchical discrete tokens, resulting in significantly reduced memory requirements and improved generalization capabilities. By combining the GQT with token modulation, a Transformer encoder achieves state-of-the-art performance on 16 out of 18 benchmarks, including large-scale homophilic and heterophilic datasets. The code is available at: https://github.com/limei0307/graph-tokenizer
Language Models are Graph Learners
Oct 03, 2024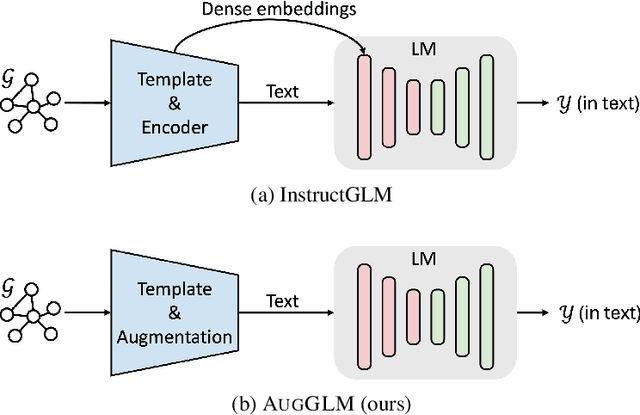

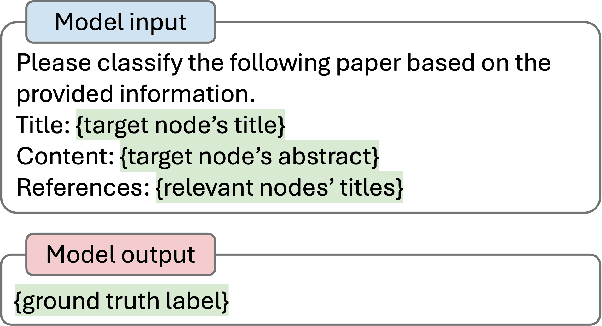
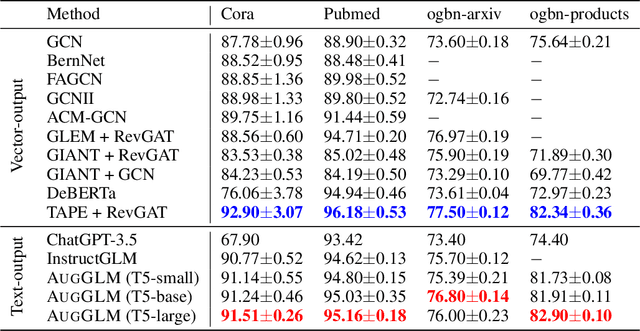
Language Models (LMs) are increasingly challenging the dominance of domain-specific models, including Graph Neural Networks (GNNs) and Graph Transformers (GTs), in graph learning tasks. Following this trend, we propose a novel approach that empowers off-the-shelf LMs to achieve performance comparable to state-of-the-art GNNs on node classification tasks, without requiring any architectural modification. By preserving the LM's original architecture, our approach retains a key benefit of LM instruction tuning: the ability to jointly train on diverse datasets, fostering greater flexibility and efficiency. To achieve this, we introduce two key augmentation strategies: (1) Enriching LMs' input using topological and semantic retrieval methods, which provide richer contextual information, and (2) guiding the LMs' classification process through a lightweight GNN classifier that effectively prunes class candidates. Our experiments on real-world datasets show that backbone Flan-T5 models equipped with these augmentation strategies outperform state-of-the-art text-output node classifiers and are comparable to top-performing vector-output node classifiers. By bridging the gap between specialized task-specific node classifiers and general LMs, this work paves the way for more versatile and widely applicable graph learning models. We will open-source the code upon publication.
EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
May 19, 2024Content-based recommendation systems play a crucial role in delivering personalized content to users in the digital world. In this work, we introduce EmbSum, a novel framework that enables offline pre-computations of users and candidate items while capturing the interactions within the user engagement history. By utilizing the pretrained encoder-decoder model and poly-attention layers, EmbSum derives User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) to calculate relevance scores between users and candidate items. EmbSum actively learns the long user engagement histories by generating user-interest summary with supervision from large language model (LLM). The effectiveness of EmbSum is validated on two datasets from different domains, surpassing state-of-the-art (SoTA) methods with higher accuracy and fewer parameters. Additionally, the model's ability to generate summaries of user interests serves as a valuable by-product, enhancing its usefulness for personalized content recommendations.
SPAR: Personalized Content-Based Recommendation via Long Engagement Attention
Feb 16, 2024



Leveraging users' long engagement histories is essential for personalized content recommendations. The success of pretrained language models (PLMs) in NLP has led to their use in encoding user histories and candidate items, framing content recommendations as textual semantic matching tasks. However, existing works still struggle with processing very long user historical text and insufficient user-item interaction. In this paper, we introduce a content-based recommendation framework, SPAR, which effectively tackles the challenges of holistic user interest extraction from the long user engagement history. It achieves so by leveraging PLM, poly-attention layers and attention sparsity mechanisms to encode user's history in a session-based manner. The user and item side features are sufficiently fused for engagement prediction while maintaining standalone representations for both sides, which is efficient for practical model deployment. Moreover, we enhance user profiling by exploiting large language model (LLM) to extract global interests from user engagement history. Extensive experiments on two benchmark datasets demonstrate that our framework outperforms existing state-of-the-art (SoTA) methods.