 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAG-MoE: From Simple Mixture to Structural Aggregation in Mixture-of-Experts
May 31, 2026Mixture-of-Experts (MoE) models have become a leading approach for decoupling parameter count from computational cost in large language models, yet effectively scaling MoE performance remains a challenge. Prior work shows that fine-grained experts enlarge the space of expert combinations and improve flexibility, but they also impose substantial routing overhead, creating a new scalability bottleneck. In this paper, we explore a complementary axis for scaling -- how expert outputs are aggregated. We theoretically show that replacing the standard weighted-summation aggregation with structural aggregation expands the expert-combination space without altering the experts or router, and enables possible multi-step reasoning within a single MoE layer. To this end, we propose DAG-MoE, a sparse MoE framework that employs a lightweight module to automatically learn the optimal aggregation structure among the selected experts. Extensive experiments under standard language modeling settings show that DAG-MoE consistently improves performance in both pretraining and fine-tuning, surpassing traditional MoE baselines.
Toward User Preference Alignment in LLM Recommendation via Explicit Context Feedback
May 27, 2026Traditional recommender systems (RecSys) primarily infer user preferences from implicit signals (such as clicks, watches, and purchases), often neglecting the rich explicit contextual feedback users provide through verbal text, like comments and reviews. This explicit context feedback captures the nuanced reasons behind user decisions regarding their preferences. In addition, it offers critical heterogeneous information for user preference alignment and more explainable recommendations. Overlooking such signals can lead to misaligned user preferences and further reinforce filter bubbles, as algorithms fail to understand the "semantic context" behind user choices. Recent advances in Large Language Models (LLMs) present new opportunities to harness user-generated content for more accurate and diverse recommendations, yet current LLM-based recommendations still focus on using item meta-data and underutilize this resource. In this paper, we advocate for prioritizing explicit context feedback in the next generation of LLM-based RecSys. We review the evolution of recommendation paradigms, highlight the value of context-rich feedback, call for new benchmarks and metrics, and introduce frameworks for integrating explicit user signals into scalable LLM-driven RecSys. Centering on user-preference modeling, we aim to foster more personalized, transparent, and explainable RecSys online platforms.
DUEL: Adversarial Self-Play for Multimodal Reasoning
May 24, 2026Reinforcement learning (RL) has emerged as an effective paradigm for improving the reasoning capability of vision-language models (VLMs). However, RL-based optimization typically depends on costly high-quality annotations that are difficult to scale. Existing unsupervised alternatives may drift toward biased solutions due to weak visual grounding and the lack of reliable verification signals. We propose a self-evolving post-training framework, DUEL, where supervision emerges from adversarial interactions between two policies initialized from the same pretrained VLM. A Challenger generates an image-grounded true claim together with a minimally perturbed hard-negative counterpart, while a Solver verifies both claims against the image, encouraging fine-grained visual discrimination under near-neighbor semantics. To stabilize optimization, we introduce a length-normalized log-likelihood reward that preserves informative optimization signals beyond binary outcome supervision and improves learning stability under sparse feedback. Experiments show that DUEL consistently improves visual reasoning and robust discrimination without additional human annotations, external reward models, or image editing tools.
TARo: Token-level Adaptive Routing for LLM Test-time Alignment
Mar 19, 2026Large language models (LLMs) exhibit strong reasoning capabilities but typically require expensive post-training to reach high performance. Recent test-time alignment methods offer a lightweight alternative, but have been explored mainly for preference alignment rather than reasoning. To bridge this gap, we propose, Token-level Adaptive Routing (TARo), which steers frozen LLMs toward structured reasoning entirely at inference time. Specifically, we first train reward models on step-wise mathematical traces to capture fine-grained logical consistency signals, then introduce a learnable token-level router that automatically controls the guidance of the reward model to the base model. Extensive experiments show that TARo significantly improves reasoning performance by up to +22.4% over base model and +8.4% over existing token-level test-time alignment methods, while also boosting out-of-distribution clinical reasoning (MedXpertQA) and instruction following (AlpacaEval). Furthermore, TARo also generalizes from small to large backbones without retraining, extending test-time alignment from preference optimization to robust, cross-domain reasoning.
ReMix: Reinforcement routing for mixtures of LoRAs in LLM finetuning
Mar 10, 2026Low-rank adapters (LoRAs) are a parameter-efficient finetuning technique that injects trainable low-rank matrices into pretrained models to adapt them to new tasks. Mixture-of-LoRAs models expand neural networks efficiently by routing each layer input to a small subset of specialized LoRAs of the layer. Existing Mixture-of-LoRAs routers assign a learned routing weight to each LoRA to enable end-to-end training of the router. Despite their empirical promise, we observe that the routing weights are typically extremely imbalanced across LoRAs in practice, where only one or two LoRAs often dominate the routing weights. This essentially limits the number of effective LoRAs and thus severely hinders the expressive power of existing Mixture-of-LoRAs models. In this work, we attribute this weakness to the nature of learnable routing weights and rethink the fundamental design of the router. To address this critical issue, we propose a new router designed that we call Reinforcement Routing for Mixture-of-LoRAs (ReMix). Our key idea is using non-learnable routing weights to ensure all active LoRAs to be equally effective, with no LoRA dominating the routing weights. However, our routers cannot be trained directly via gradient descent due to our non-learnable routing weights. Hence, we further propose an unbiased gradient estimator for the router by employing the reinforce leave-one-out (RLOO) technique, where we regard the supervision loss as the reward and the router as the policy in reinforcement learning. Our gradient estimator also enables to scale up training compute to boost the predictive performance of our ReMix. Extensive experiments demonstrate that our proposed ReMix significantly outperform state-of-the-art parameter-efficient finetuning methods under a comparable number of activated parameters.
Verifiable Reasoning for LLM-based Generative Recommendation
Mar 08, 2026Reasoning in Large Language Models (LLMs) has recently shown strong potential in enhancing generative recommendation through deep understanding of complex user preference. Existing approaches follow a {reason-then-recommend} paradigm, where LLMs perform step-by-step reasoning before item generation. However, this paradigm inevitably suffers from reasoning degradation (i.e., homogeneous or error-accumulated reasoning) due to the lack of intermediate verification, thus undermining the recommendation. To bridge this gap, we propose a novel \textbf{\textit{reason-verify-recommend}} paradigm, which interleaves reasoning with verification to provide reliable feedback, guiding the reasoning process toward more faithful user preference understanding. To enable effective verification, we establish two key principles for verifier design: 1) reliability ensures accurate evaluation of reasoning correctness and informative guidance generation; and 2) multi-dimensionality emphasizes comprehensive verification across multi-dimensional user preferences. Accordingly, we propose an effective implementation called VRec. It employs a mixture of verifiers to ensure multi-dimensionality, while leveraging a proxy prediction objective to pursue reliability. Experiments on four real-world datasets demonstrate that VRec substantially enhances recommendation effectiveness and scalability without compromising efficiency. The codes can be found at https://github.com/Linxyhaha/Verifiable-Rec.
Text Has Curvature
Feb 13, 2026Does text have an intrinsic curvature? Language is increasingly modeled in curved geometries - hyperbolic spaces for hierarchy, mixed-curvature manifolds for compositional structure - yet a basic scientific question remains unresolved: what does curvature mean for text itself, in a way that is native to language rather than an artifact of the embedding space we choose? We argue that text does indeed have curvature, and show how to detect it, define it, and use it. To this end, we propose Texture, a text-native, word-level discrete curvature signal, and make three contributions. (a) Existence: We provide empirical and theoretical certificates that semantic inference in natural corpora is non-flat, i.e. language has inherent curvature. (b) Definition: We define Texture by reconciling left- and right-context beliefs around a masked word through a Schrodinger bridge, yielding a curvature field that is positive where context focuses meaning and negative where it fans out into competing continuations. (c) Utility: Texture is actionable: it serves as a general-purpose measurement and control primitive enabling geometry without geometric training; we instantiate it on two representative tasks, improving long-context inference through curvature-guided compression and retrieval-augmented generation through curvature-guided routing. Together, our results establish a text-native curvature paradigm, making curvature measurable and practically useful.
Token-Level LLM Collaboration via FusionRoute
Jan 08, 2026Large language models (LLMs) exhibit strengths across diverse domains. However, achieving strong performance across these domains with a single general-purpose model typically requires scaling to sizes that are prohibitively expensive to train and deploy. On the other hand, while smaller domain-specialized models are much more efficient, they struggle to generalize beyond their training distributions. To address this dilemma, we propose FusionRoute, a robust and effective token-level multi-LLM collaboration framework in which a lightweight router simultaneously (i) selects the most suitable expert at each decoding step and (ii) contributes a complementary logit that refines or corrects the selected expert's next-token distribution via logit addition. Unlike existing token-level collaboration methods that rely solely on fixed expert outputs, we provide a theoretical analysis showing that pure expert-only routing is fundamentally limited: unless strong global coverage assumptions hold, it cannot in general realize the optimal decoding policy. By augmenting expert selection with a trainable complementary generator, FusionRoute expands the effective policy class and enables recovery of optimal value functions under mild conditions. Empirically, across both Llama-3 and Gemma-2 families and diverse benchmarks spanning mathematical reasoning, code generation, and instruction following, FusionRoute outperforms both sequence- and token-level collaboration, model merging, and direct fine-tuning, while remaining competitive with domain experts on their respective tasks.
S'MoRE: Structural Mixture of Residual Experts for LLM Fine-tuning
Apr 08, 2025Fine-tuning pre-trained large language models (LLMs) presents a dual challenge of balancing parameter efficiency and model capacity. Existing methods like low-rank adaptations (LoRA) are efficient but lack flexibility, while Mixture-of-Experts (MoE) architectures enhance model capacity at the cost of more & under-utilized parameters. To address these limitations, we propose Structural Mixture of Residual Experts (S'MoRE), a novel framework that seamlessly integrates the efficiency of LoRA with the flexibility of MoE. Specifically, S'MoRE employs hierarchical low-rank decomposition of expert weights, yielding residuals of varying orders interconnected in a multi-layer structure. By routing input tokens through sub-trees of residuals, S'MoRE emulates the capacity of many experts by instantiating and assembling just a few low-rank matrices. We craft the inter-layer propagation of S'MoRE's residuals as a special type of Graph Neural Network (GNN), and prove that under similar parameter budget, S'MoRE improves "structural flexibility" of traditional MoE (or Mixture-of-LoRA) by exponential order. Comprehensive theoretical analysis and empirical results demonstrate that S'MoRE achieves superior fine-tuning performance, offering a transformative approach for efficient LLM adaptation.
Language Models are Graph Learners
Oct 03, 2024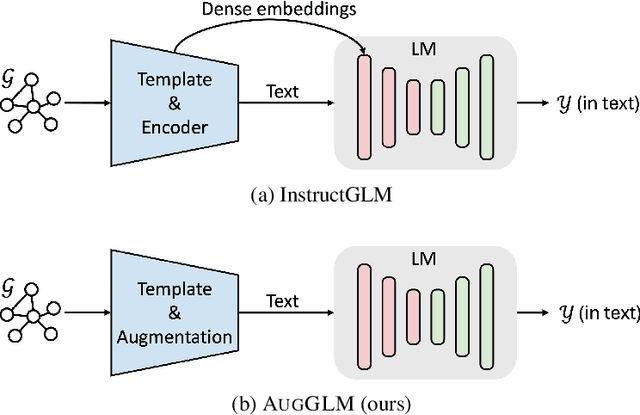

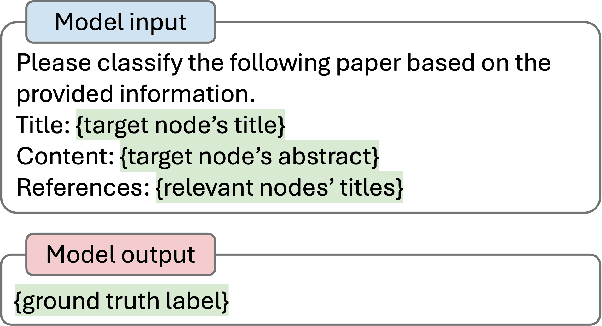
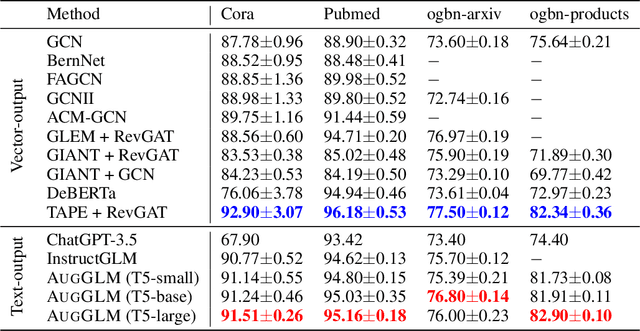
Language Models (LMs) are increasingly challenging the dominance of domain-specific models, including Graph Neural Networks (GNNs) and Graph Transformers (GTs), in graph learning tasks. Following this trend, we propose a novel approach that empowers off-the-shelf LMs to achieve performance comparable to state-of-the-art GNNs on node classification tasks, without requiring any architectural modification. By preserving the LM's original architecture, our approach retains a key benefit of LM instruction tuning: the ability to jointly train on diverse datasets, fostering greater flexibility and efficiency. To achieve this, we introduce two key augmentation strategies: (1) Enriching LMs' input using topological and semantic retrieval methods, which provide richer contextual information, and (2) guiding the LMs' classification process through a lightweight GNN classifier that effectively prunes class candidates. Our experiments on real-world datasets show that backbone Flan-T5 models equipped with these augmentation strategies outperform state-of-the-art text-output node classifiers and are comparable to top-performing vector-output node classifiers. By bridging the gap between specialized task-specific node classifiers and general LMs, this work paves the way for more versatile and widely applicable graph learning models. We will open-source the code upon publication.