 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAG-MoE: From Simple Mixture to Structural Aggregation in Mixture-of-Experts
May 31, 2026Mixture-of-Experts (MoE) models have become a leading approach for decoupling parameter count from computational cost in large language models, yet effectively scaling MoE performance remains a challenge. Prior work shows that fine-grained experts enlarge the space of expert combinations and improve flexibility, but they also impose substantial routing overhead, creating a new scalability bottleneck. In this paper, we explore a complementary axis for scaling -- how expert outputs are aggregated. We theoretically show that replacing the standard weighted-summation aggregation with structural aggregation expands the expert-combination space without altering the experts or router, and enables possible multi-step reasoning within a single MoE layer. To this end, we propose DAG-MoE, a sparse MoE framework that employs a lightweight module to automatically learn the optimal aggregation structure among the selected experts. Extensive experiments under standard language modeling settings show that DAG-MoE consistently improves performance in both pretraining and fine-tuning, surpassing traditional MoE baselines.
Agentic Recommender System with Hierarchical Belief-State Memory
May 14, 2026Memory-augmented LLM agents have advanced personalized recommendation, yet existing approaches universally adopt flat memory representations that conflate ephemeral signals with stable preferences, and none provides a complete lifecycle governing how memory should evolve. We propose MARS (Memory-Augmented Agentic Recommender System), a framework that treats recommendation as a partially observable problem and maintains a structured belief state that progressively abstracts noisy behavioral observations into a compact estimate of user preferences. MARS organizes this belief state into three tiers: event memory buffers raw signals, preference memory maintains fine-grained mutable chunks with explicit strength and evidence tracking, and profile memory distills all preferences into a coherent natural language narrative. A complete lifecycle of six operations -- extraction, reinforcement, weakening, consolidation, forgetting, and resynthesis -- is adaptively scheduled by an LLM-based planner rather than fixed-interval heuristics. Experiments on four InstructRec benchmark domains show that \ours achieves state-of-the-art performance with average improvements of 26.4% in HR@1 and 10.3% in NDCG@10 over the strongest baselines with further gains from agentic scheduling in evolving settings.
ReMix: Reinforcement routing for mixtures of LoRAs in LLM finetuning
Mar 10, 2026Low-rank adapters (LoRAs) are a parameter-efficient finetuning technique that injects trainable low-rank matrices into pretrained models to adapt them to new tasks. Mixture-of-LoRAs models expand neural networks efficiently by routing each layer input to a small subset of specialized LoRAs of the layer. Existing Mixture-of-LoRAs routers assign a learned routing weight to each LoRA to enable end-to-end training of the router. Despite their empirical promise, we observe that the routing weights are typically extremely imbalanced across LoRAs in practice, where only one or two LoRAs often dominate the routing weights. This essentially limits the number of effective LoRAs and thus severely hinders the expressive power of existing Mixture-of-LoRAs models. In this work, we attribute this weakness to the nature of learnable routing weights and rethink the fundamental design of the router. To address this critical issue, we propose a new router designed that we call Reinforcement Routing for Mixture-of-LoRAs (ReMix). Our key idea is using non-learnable routing weights to ensure all active LoRAs to be equally effective, with no LoRA dominating the routing weights. However, our routers cannot be trained directly via gradient descent due to our non-learnable routing weights. Hence, we further propose an unbiased gradient estimator for the router by employing the reinforce leave-one-out (RLOO) technique, where we regard the supervision loss as the reward and the router as the policy in reinforcement learning. Our gradient estimator also enables to scale up training compute to boost the predictive performance of our ReMix. Extensive experiments demonstrate that our proposed ReMix significantly outperform state-of-the-art parameter-efficient finetuning methods under a comparable number of activated parameters.
Rethinking ANN-based Retrieval: Multifaceted Learnable Index for Large-scale Recommendation System
Feb 18, 2026Approximate nearest neighbor (ANN) search is widely used in the retrieval stage of large-scale recommendation systems. In this stage, candidate items are indexed using their learned embedding vectors, and ANN search is executed for each user (or item) query to retrieve a set of relevant items. However, ANN-based retrieval has two key limitations. First, item embeddings and their indices are typically learned in separate stages: indexing is often performed offline after embeddings are trained, which can yield suboptimal retrieval quality-especially for newly created items. Second, although ANN offers sublinear query time, it must still be run for every request, incurring substantial computation cost at industry scale. In this paper, we propose MultiFaceted Learnable Index (MFLI), a scalable, real-time retrieval paradigm that learns multifaceted item embeddings and indices within a unified framework and eliminates ANN search at serving time. Specifically, we construct a multifaceted hierarchical codebook via residual quantization of item embeddings and co-train the codebook with the embeddings. We further introduce an efficient multifaceted indexing structure and mechanisms that support real-time updates. At serving time, the learned hierarchical indices are used directly to identify relevant items, avoiding ANN search altogether. Extensive experiments on real-world data with billions of users show that MFLI improves recall on engagement tasks by up to 11.8\%, cold-content delivery by up to 57.29\%, and semantic relevance by 13.5\% compared with prior state-of-the-art methods. We also deploy MFLI in the system and report online experimental results demonstrating improved engagement, less popularity bias, and higher serving efficiency.
Principled Synthetic Data Enables the First Scaling Laws for LLMs in Recommendation
Feb 07, 2026Large Language Models (LLMs) represent a promising frontier for recommender systems, yet their development has been impeded by the absence of predictable scaling laws, which are crucial for guiding research and optimizing resource allocation. We hypothesize that this may be attributed to the inherent noise, bias, and incompleteness of raw user interaction data in prior continual pre-training (CPT) efforts. This paper introduces a novel, layered framework for generating high-quality synthetic data that circumvents such issues by creating a curated, pedagogical curriculum for the LLM. We provide powerful, direct evidence for the utility of our curriculum by showing that standard sequential models trained on our principled synthetic data significantly outperform ($+130\%$ on recall@100 for SasRec) models trained on real data in downstream ranking tasks, demonstrating its superiority for learning generalizable user preference patterns. Building on this, we empirically demonstrate, for the first time, robust power-law scaling for an LLM that is continually pre-trained on our high-quality, recommendation-specific data. Our experiments reveal consistent and predictable perplexity reduction across multiple synthetic data modalities. These findings establish a foundational methodology for reliable scaling LLM capabilities in the recommendation domain, thereby shifting the research focus from mitigating data deficiencies to leveraging high-quality, structured information.
Efficient Sequential Recommendation for Long Term User Interest Via Personalization
Jan 07, 2026Recent years have witnessed success of sequential modeling, generative recommender, and large language model for recommendation. Though the scaling law has been validated for sequential models, it showed inefficiency in computational capacity when considering real-world applications like recommendation, due to the non-linear(quadratic) increasing nature of the transformer model. To improve the efficiency of the sequential model, we introduced a novel approach to sequential recommendation that leverages personalization techniques to enhance efficiency and performance. Our method compresses long user interaction histories into learnable tokens, which are then combined with recent interactions to generate recommendations. This approach significantly reduces computational costs while maintaining high recommendation accuracy. Our method could be applied to existing transformer based recommendation models, e.g., HSTU and HLLM. Extensive experiments on multiple sequential models demonstrate its versatility and effectiveness. Source code is available at \href{https://github.com/facebookresearch/PerSRec}{https://github.com/facebookresearch/PerSRec}.
GEM: Empowering LLM for both Embedding Generation and Language Understanding
Jun 04, 2025Large decoder-only language models (LLMs) have achieved remarkable success in generation and reasoning tasks, where they generate text responses given instructions. However, many applications, e.g., retrieval augmented generation (RAG), still rely on separate embedding models to generate text embeddings, which can complicate the system and introduce discrepancies in understanding of the query between the embedding model and LLMs. To address this limitation, we propose a simple self-supervised approach, Generative Embedding large language Model (GEM), that enables any large decoder-only LLM to generate high-quality text embeddings while maintaining its original text generation and reasoning capabilities. Our method inserts new special token(s) into a text body, and generates summarization embedding of the text by manipulating the attention mask. This method could be easily integrated into post-training or fine tuning stages of any existing LLMs. We demonstrate the effectiveness of our approach by applying it to two popular LLM families, ranging from 1B to 8B parameters, and evaluating the transformed models on both text embedding benchmarks (MTEB) and NLP benchmarks (MMLU). The results show that our proposed method significantly improves the original LLMs on MTEB while having a minimal impact on MMLU. Our strong results indicate that our approach can empower LLMs with state-of-the-art text embedding capabilities while maintaining their original NLP performance
S'MoRE: Structural Mixture of Residual Experts for LLM Fine-tuning
Apr 08, 2025Fine-tuning pre-trained large language models (LLMs) presents a dual challenge of balancing parameter efficiency and model capacity. Existing methods like low-rank adaptations (LoRA) are efficient but lack flexibility, while Mixture-of-Experts (MoE) architectures enhance model capacity at the cost of more & under-utilized parameters. To address these limitations, we propose Structural Mixture of Residual Experts (S'MoRE), a novel framework that seamlessly integrates the efficiency of LoRA with the flexibility of MoE. Specifically, S'MoRE employs hierarchical low-rank decomposition of expert weights, yielding residuals of varying orders interconnected in a multi-layer structure. By routing input tokens through sub-trees of residuals, S'MoRE emulates the capacity of many experts by instantiating and assembling just a few low-rank matrices. We craft the inter-layer propagation of S'MoRE's residuals as a special type of Graph Neural Network (GNN), and prove that under similar parameter budget, S'MoRE improves "structural flexibility" of traditional MoE (or Mixture-of-LoRA) by exponential order. Comprehensive theoretical analysis and empirical results demonstrate that S'MoRE achieves superior fine-tuning performance, offering a transformative approach for efficient LLM adaptation.
FedMM: Saddle Point Optimization for Federated Adversarial Domain Adaptation
Oct 24, 2021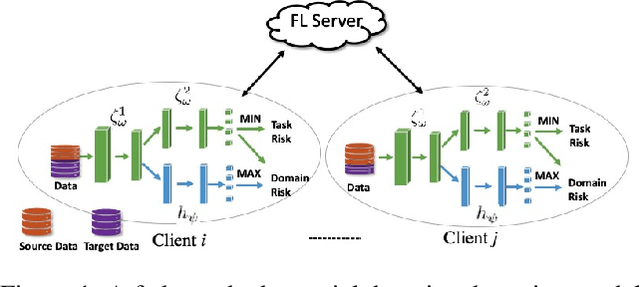
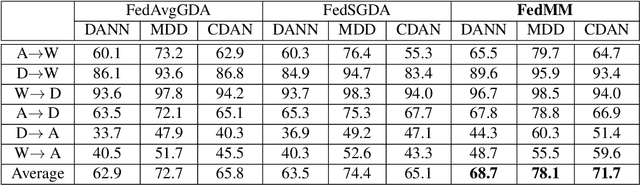

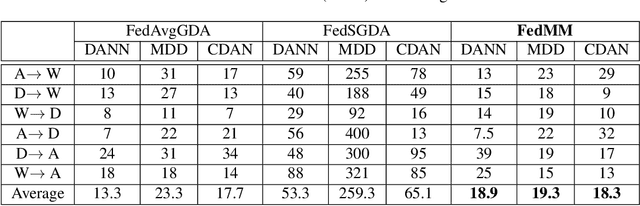
Federated adversary domain adaptation is a unique distributed minimax training task due to the prevalence of label imbalance among clients, with each client only seeing a subset of the classes of labels required to train a global model. To tackle this problem, we propose a distributed minimax optimizer referred to as FedMM, designed specifically for the federated adversary domain adaptation problem. It works well even in the extreme case where each client has different label classes and some clients only have unsupervised tasks. We prove that FedMM ensures convergence to a stationary point with domain-shifted unsupervised data. On a variety of benchmark datasets, extensive experiments show that FedMM consistently achieves either significant communication savings or significant accuracy improvements over federated optimizers based on the gradient descent ascent (GDA) algorithm. When training from scratch, for example, it outperforms other GDA based federated average methods by around $20\%$ in accuracy over the same communication rounds; and it consistently outperforms when training from pre-trained models with an accuracy improvement from $5.4\%$ to $9\%$ for different networks.
ASFGNN: Automated Separated-Federated Graph Neural Network
Nov 06, 2020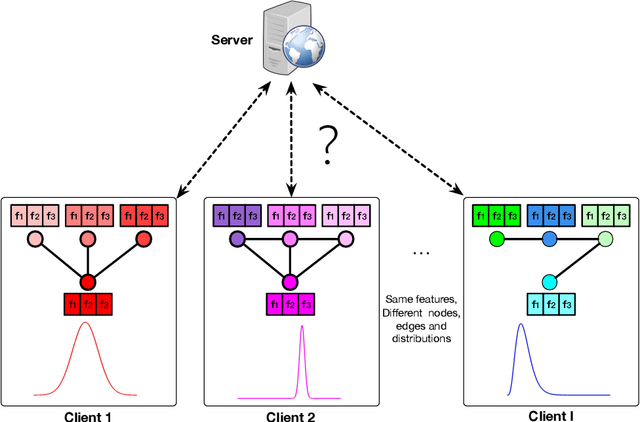
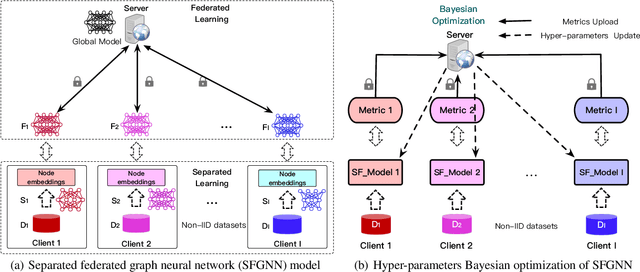
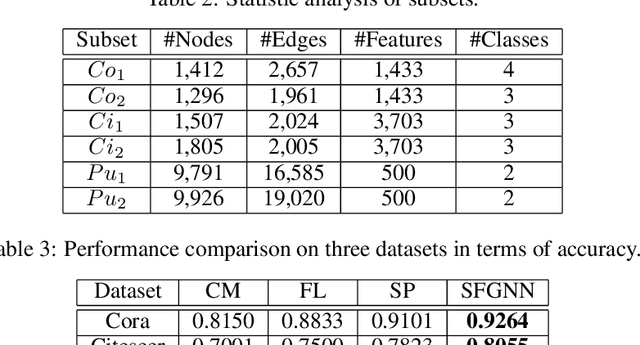
Graph Neural Networks (GNNs) have achieved remarkable performance by taking advantage of graph data. The success of GNN models always depends on rich features and adjacent relationships. However, in practice, such data are usually isolated by different data owners (clients) and thus are likely to be Non-Independent and Identically Distributed (Non-IID). Meanwhile, considering the limited network status of data owners, hyper-parameters optimization for collaborative learning approaches is time-consuming in data isolation scenarios. To address these problems, we propose an Automated Separated-Federated Graph Neural Network (ASFGNN) learning paradigm. ASFGNN consists of two main components, i.e., the training of GNN and the tuning of hyper-parameters. Specifically, to solve the data Non-IID problem, we first propose a separated-federated GNN learning model, which decouples the training of GNN into two parts: the message passing part that is done by clients separately, and the loss computing part that is learnt by clients federally. To handle the time-consuming parameter tuning problem, we leverage Bayesian optimization technique to automatically tune the hyper-parameters of all the clients. We conduct experiments on benchmark datasets and the results demonstrate that ASFGNN significantly outperforms the naive federated GNN, in terms of both accuracy and parameter-tuning efficiency.