 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBudget Recycling Differential Privacy
Mar 18, 2024Differential Privacy (DP) mechanisms usually {force} reduction in data utility by producing ``out-of-bound'' noisy results for a tight privacy budget. We introduce the Budget Recycling Differential Privacy (BR-DP) framework, designed to provide soft-bounded noisy outputs for a broad range of existing DP mechanisms. By ``soft-bounded," we refer to the mechanism's ability to release most outputs within a predefined error boundary, thereby improving utility and maintaining privacy simultaneously. The core of BR-DP consists of two components: a DP kernel responsible for generating a noisy answer per iteration, and a recycler that probabilistically recycles/regenerates or releases the noisy answer. We delve into the privacy accounting of BR-DP, culminating in the development of a budgeting principle that optimally sub-allocates the available budget between the DP kernel and the recycler. Furthermore, we introduce algorithms for tight BR-DP accounting in composition scenarios, and our findings indicate that BR-DP achieves reduced privacy leakage post-composition compared to DP. Additionally, we explore the concept of privacy amplification via subsampling within the BR-DP framework and propose optimal sampling rates for BR-DP across various queries. We experiment with real data, and the results demonstrate BR-DP's effectiveness in lifting the utility-privacy tradeoff provided by DP mechanisms.
AnonPSI: An Anonymity Assessment Framework for PSI
Nov 29, 2023



Private Set Intersection (PSI) is a widely used protocol that enables two parties to securely compute a function over the intersected part of their shared datasets and has been a significant research focus over the years. However, recent studies have highlighted its vulnerability to Set Membership Inference Attacks (SMIA), where an adversary might deduce an individual's membership by invoking multiple PSI protocols. This presents a considerable risk, even in the most stringent versions of PSI, which only return the cardinality of the intersection. This paper explores the evaluation of anonymity within the PSI context. Initially, we highlight the reasons why existing works fall short in measuring privacy leakage, and subsequently propose two attack strategies that address these deficiencies. Furthermore, we provide theoretical guarantees on the performance of our proposed methods. In addition to these, we illustrate how the integration of auxiliary information, such as the sum of payloads associated with members of the intersection (PSI-SUM), can enhance attack efficiency. We conducted a comprehensive performance evaluation of various attack strategies proposed utilizing two real datasets. Our findings indicate that the methods we propose markedly enhance attack efficiency when contrasted with previous research endeavors. {The effective attacking implies that depending solely on existing PSI protocols may not provide an adequate level of privacy assurance. It is recommended to combine privacy-enhancing technologies synergistically to enhance privacy protection even further.
An automated approach to extracting positive and negative clinical research results
Dec 07, 2022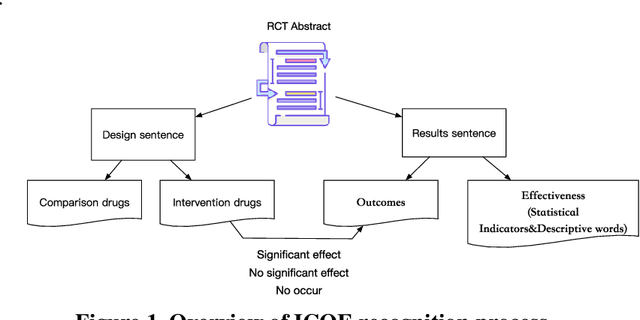
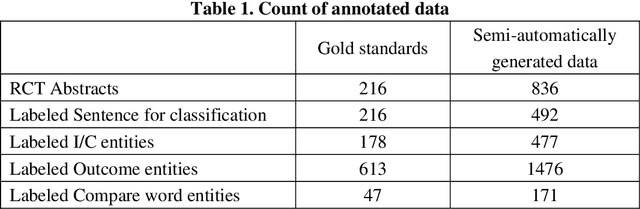
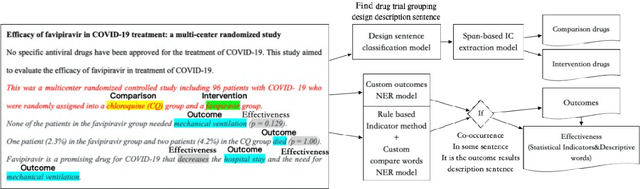
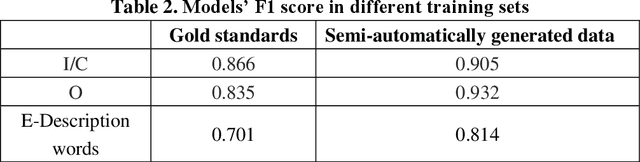
Failure is common in clinical trials since the successful failures presented in negative results always indicate the ways that should not be taken. In this paper, we proposed an automated approach to extracting positive and negative clinical research results by introducing a PICOE (Population, Intervention, Comparation, Outcome, and Effect) framework to represent randomized controlled trials (RCT) reports, where E indicates the effect between a specific I and O. We developed a pipeline to extract and assign the corresponding statistical effect to a specific I-O pair from natural language RCT reports. The extraction models achieved a high degree of accuracy for ICO and E descriptive words extraction through two rounds of training. By defining a threshold of p-value, we find in all Covid-19 related intervention-outcomes pairs with statistical tests, negative results account for nearly 40%. We believe that this observation is noteworthy since they are extracted from the published literature, in which there is an inherent risk of reporting bias, preferring to report positive results rather than negative results. We provided a tool to systematically understand the current level of clinical evidence by distinguishing negative results from the positive results.
DP-FP: Differentially Private Forward Propagation for Large Models
Dec 29, 2021

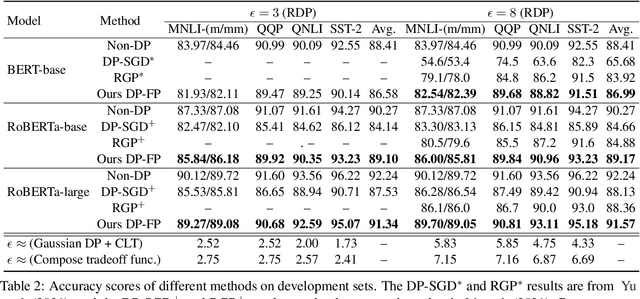
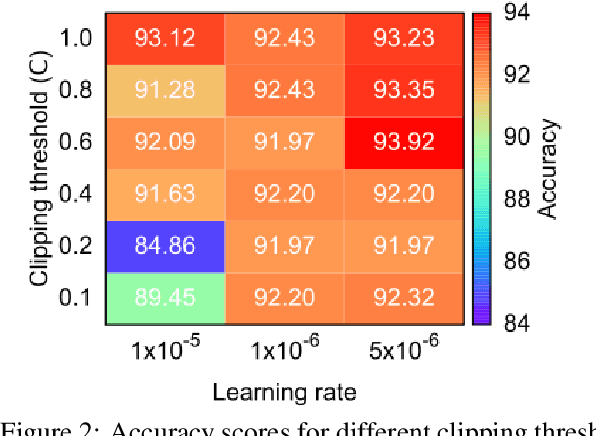
When applied to large-scale learning problems, the conventional wisdom on privacy-preserving deep learning, known as Differential Private Stochastic Gradient Descent (DP-SGD), has met with limited success due to significant performance degradation and high memory overhead when compared to the non-privacy counterpart. We show how to mitigate the performance drop by replacing the DP-SGD with a novel DP Forward-Propagation (DP-FP) followed by an off-the-shelf non-DP optimizer. Our DP-FP employs novel (1) representation clipping followed by noise addition in the forward propagation stage, as well as (2) micro-batch construction via subsampling to achieve DP amplification and reduce noise power to $1/M$, where $M$ is the number of micro-batch in a step. When training a classification model, our DP-FP with all of the privacy-preserving operations on the representation is innately free of gradient bias, total noise proportionally to model size, and memory issues in DP-SGD. As a result, our DP-FP outperforms cutting-edge DP-SGD while retaining the same level of privacy, and it approaches non-private baselines and significantly outperforms state-of-the-art DP-SGD variants. When applied to RoBERTa-large on four downstream tasks, for example, DP-FP achieves an average accuracy of 91.34\% with privacy budgets less than 3, representing a 3.81\% performance improvement over the state-of-the-art DP-SGD and only a 0.9\% loss compared to the non-private baseline but with a significantly lower privacy leakage risk.
Distinguishing Transformative from Incremental Clinical Evidence: A Classifier of Clinical Research using Textual features from Abstracts and Citing Sentences
Dec 24, 2021

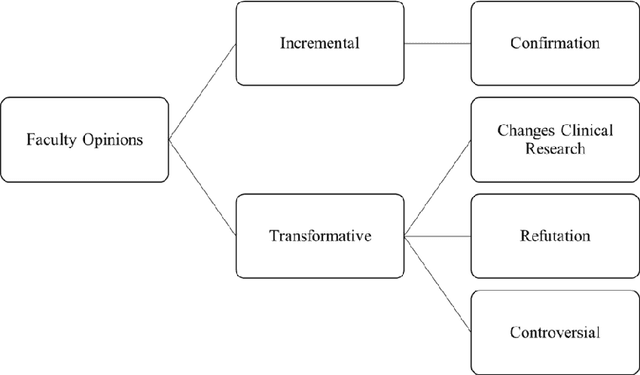
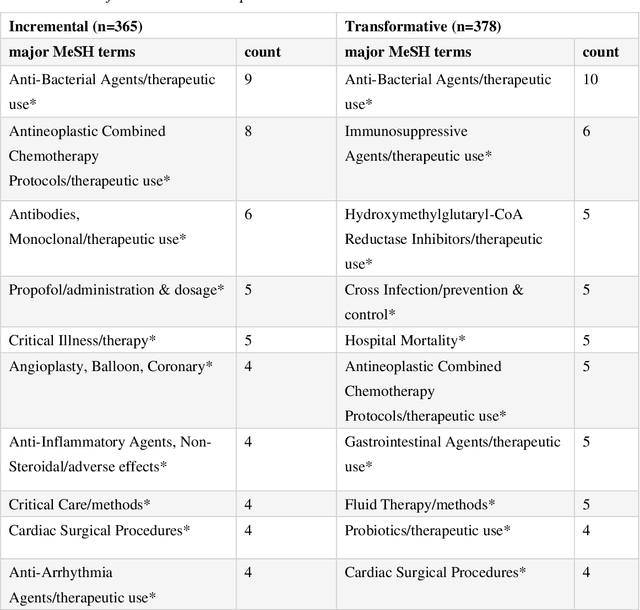
In clinical research and clinical decision-making, it is important to know if a study changes or only supports the current standards of care for specific disease management. We define such a change as transformative and a support as incremental research. It usually requires a huge amount of domain expertise and time for humans to finish such tasks. Faculty Opinions provides us with a well-annotated corpus on whether a research challenges or only confirms established research. In this study, a machine learning approach is proposed to distinguishing transformative from incremental clinical evidence. The texts from both abstract and a 2-year window of citing sentences are collected for a training set of clinical studies recommended and labeled by Faculty Opinions experts. We achieve the best performance with an average AUC of 0.755 (0.705-0.875) using Random Forest as the classifier and citing sentences as the feature. The results showed that transformative research has typical language patterns in citing sentences unlike abstract sentences. We provide an efficient tool for identifying those clinical evidence challenging or only confirming established claims for clinicians and researchers.
A comment-driven evidence appraisal approach for decision-making when only uncertain evidence available
Dec 21, 2021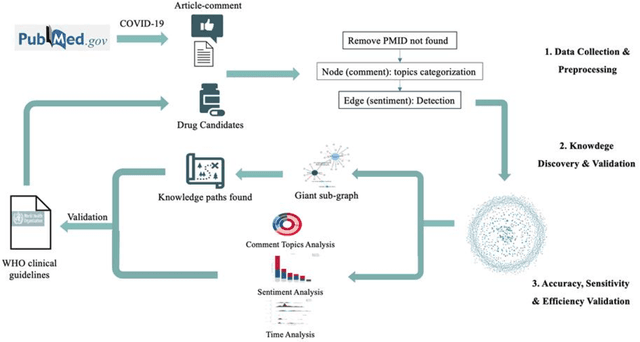



Purpose: To explore whether comments could be used as an assistant tool for heuristic decision-making, especially in cases where missing, incomplete, uncertain, or even incorrect evidence is acquired. Methods: Six COVID-19 drug candidates were selected from WHO clinical guidelines. Evidence-comment networks (ECNs) were completed of these six drug candidates based on evidence-comment pairs from all PubMed indexed COVID-19 publications with formal published comments. WHO guidelines were utilized to validate the feasibility of comment-derived evidence assertions as a fast decision supporting tool. Results: Out of 6 drug candidates, comment-derived evidence assertions of leading subgraphs of 5 drugs were consistent with WHO guidelines, and the overall comment sentiment of 6 drugs was aligned with WHO clinical guidelines. Additionally, comment topics were in accordance with the concerns of guidelines and evidence appraisal criteria. Furthermore, half of the critical comments emerged 4.5 months earlier than the date guidelines were published. Conclusions: Comment-derived evidence assertions have the potential as an evidence appraisal tool for heuristic decisions based on the accuracy, sensitivity, and efficiency of evidence-comment networks. In essence, comments reflect that academic communities do have a self-screening evaluation and self-purification (argumentation) mechanism, thus providing a tool for decision makers to filter evidence.
Extracting and Measuring Uncertain Biomedical Knowledge from Scientific Statements
Dec 05, 2021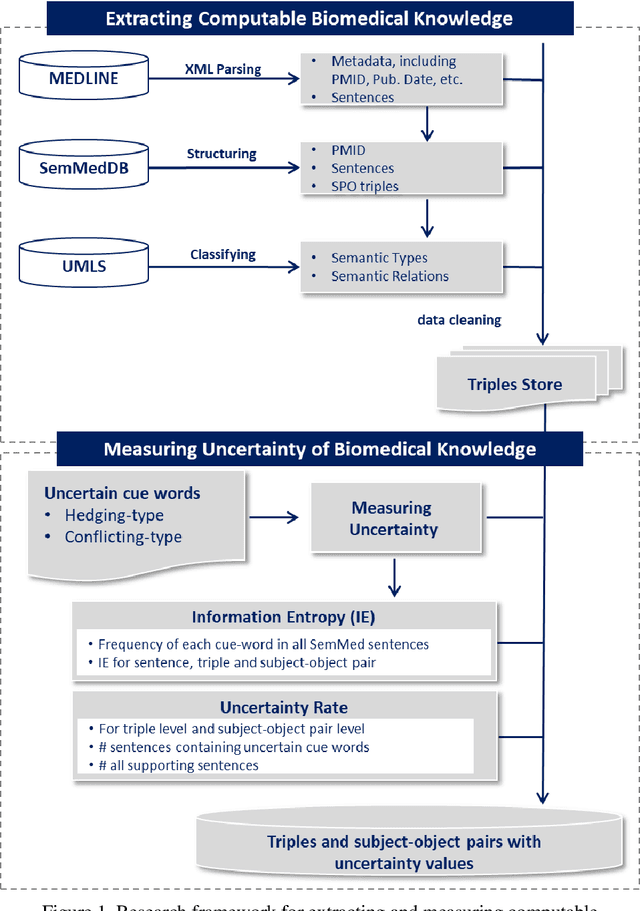

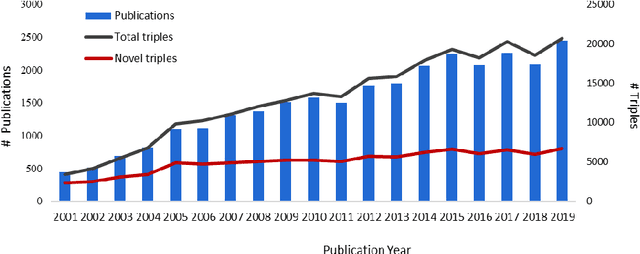
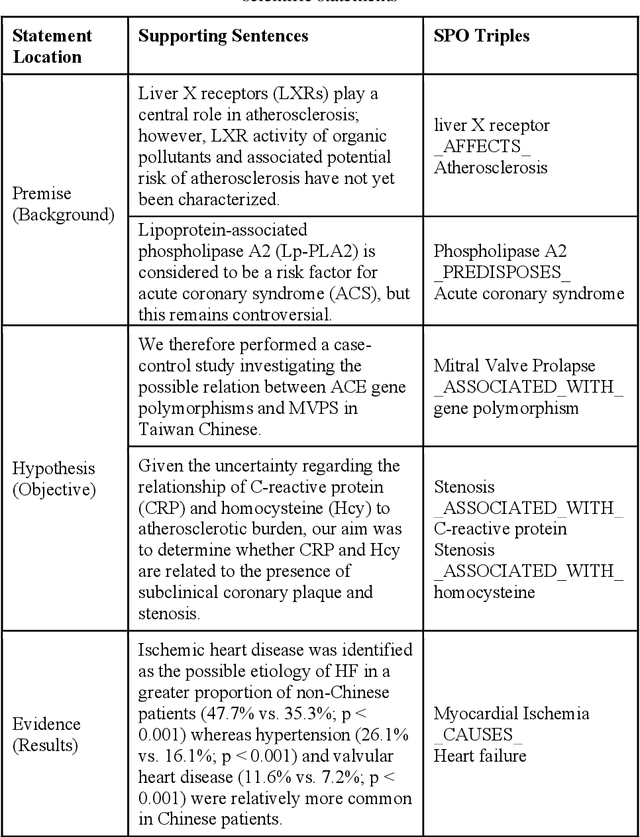
Purpose: This study aims to develop a novel approach to extracting and measuring uncertain biomedical knowledge from scientific statements. Design/methodology/approach: Taking cardiovascular research publications in China as a sample, we extracted the SPO triples as knowledge unit and the hedging/conflicting uncertainties as the knowledge context. We introduced Information Entropy and Uncertainty Rate as potential metrics to quantity the uncertainty of biomedical knowledge claims represented at different levels, such as the SPO triples (micro level), as well as the semantic type pairs (micro-level). Findings: The results indicated that while the number of scientific publications and total SPO triples showed a liner growth, the novel SPO triples occurring per year remained stable. After examining the frequency of uncertain cue words in different part of scientific statements, we found hedging words tend to appear in conclusive and purposeful sentences, whereas conflicting terms often appear in background and act as the premise (e.g., unsettled scientific issues) of the work to be investigated. Practical implications: Our approach identified major uncertain knowledge areas, such as diagnostic biomarkers, genetic characteristics, and pharmacologic therapies surrounding cardiovascular diseases in China. These areas are suggested to be prioritized in which new hypotheses need to be verified, and disputes, conflicts, as well as contradictions to be settled further.
Dynamic Differential-Privacy Preserving SGD
Nov 15, 2021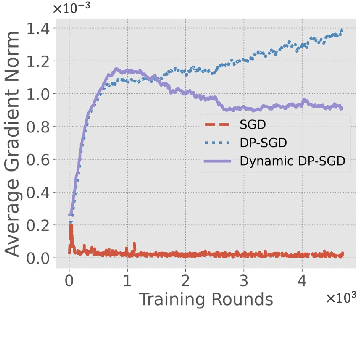
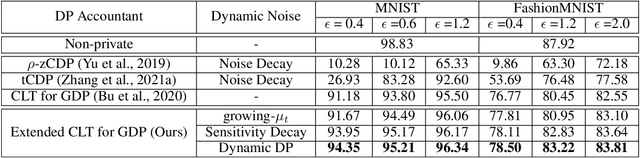
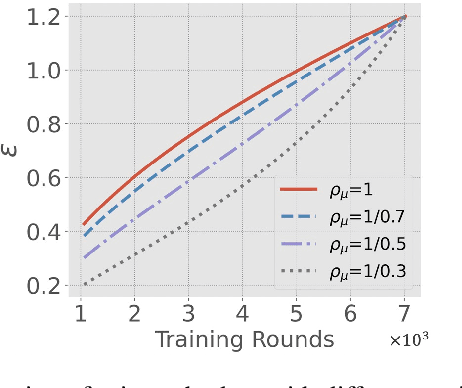
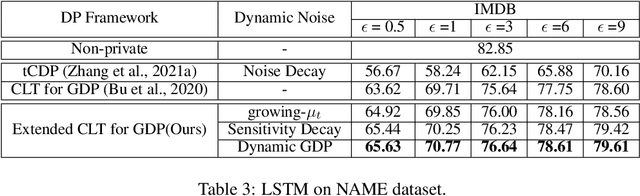
Differentially-Private Stochastic Gradient Descent (DP-SGD) prevents training-data privacy breaches by adding noise to the clipped gradient during SGD training to satisfy the differential privacy (DP) definition. On the other hand, the same clipping operation and additive noise across training steps results in unstable updates and even a ramp-up period, which significantly reduces the model's accuracy. In this paper, we extend the Gaussian DP central limit theorem to calibrate the clipping value and the noise power for each individual step separately. We, therefore, are able to propose the dynamic DP-SGD, which has a lower privacy cost than the DP-SGD during updates until they achieve the same target privacy budget at a target number of updates. Dynamic DP-SGD, in particular, improves model accuracy without sacrificing privacy by gradually lowering both clipping value and noise power while adhering to a total privacy budget constraint. Extensive experiments on a variety of deep learning tasks, including image classification, natural language processing, and federated learning, show that the proposed dynamic DP-SGD algorithm stabilizes updates and, as a result, significantly improves model accuracy in the strong privacy protection region when compared to DP-SGD.
FedMM: Saddle Point Optimization for Federated Adversarial Domain Adaptation
Oct 24, 2021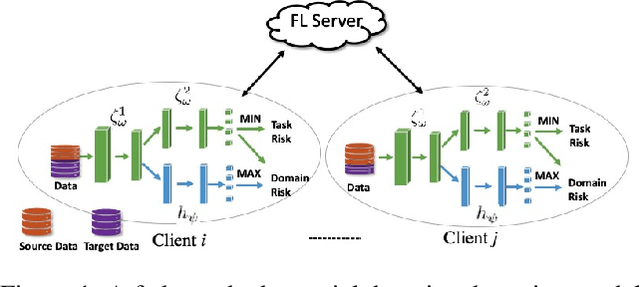
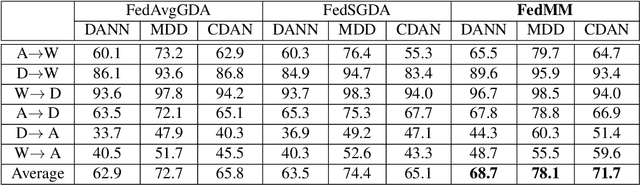

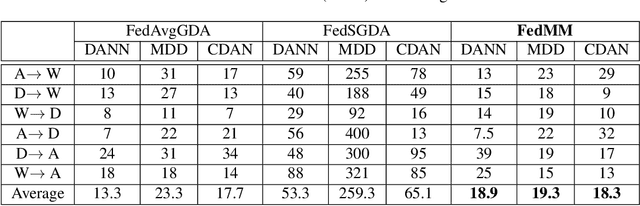
Federated adversary domain adaptation is a unique distributed minimax training task due to the prevalence of label imbalance among clients, with each client only seeing a subset of the classes of labels required to train a global model. To tackle this problem, we propose a distributed minimax optimizer referred to as FedMM, designed specifically for the federated adversary domain adaptation problem. It works well even in the extreme case where each client has different label classes and some clients only have unsupervised tasks. We prove that FedMM ensures convergence to a stationary point with domain-shifted unsupervised data. On a variety of benchmark datasets, extensive experiments show that FedMM consistently achieves either significant communication savings or significant accuracy improvements over federated optimizers based on the gradient descent ascent (GDA) algorithm. When training from scratch, for example, it outperforms other GDA based federated average methods by around $20\%$ in accuracy over the same communication rounds; and it consistently outperforms when training from pre-trained models with an accuracy improvement from $5.4\%$ to $9\%$ for different networks.
Towards Medical Knowmetrics: Representing and Computing Medical Knowledge using Semantic Predications as the Knowledge Unit and the Uncertainty as the Knowledge Context
Oct 25, 2020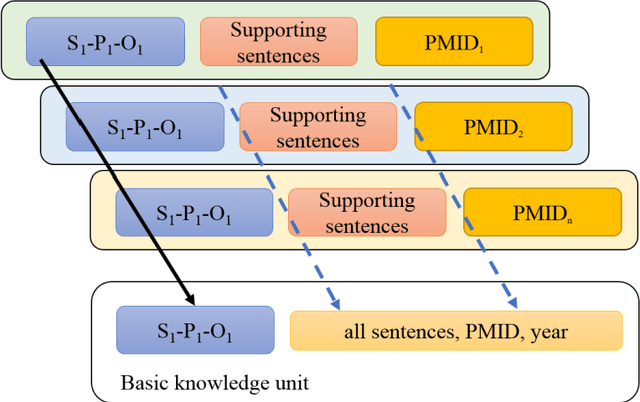
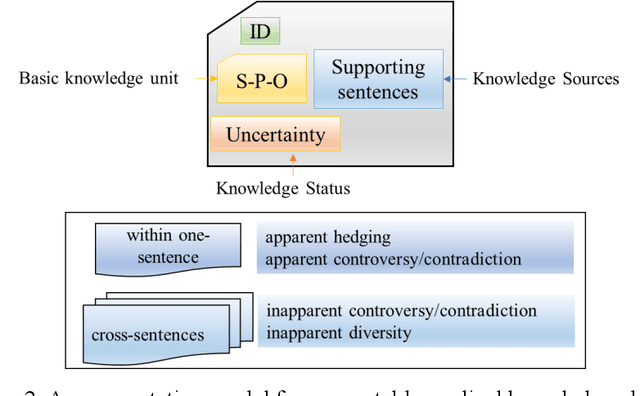


In China, Prof. Hongzhou Zhao and Zeyuan Liu are the pioneers of the concept "knowledge unit" and "knowmetrics" for measuring knowledge. However, the definition of "computable knowledge object" remains controversial so far in different fields. For example, it is defined as 1) quantitative scientific concept in natural science and engineering, 2) knowledge point in the field of education research, and 3) semantic predications, i.e., Subject-Predicate-Object (SPO) triples in biomedical fields. The Semantic MEDLINE Database (SemMedDB), a high-quality public repository of SPO triples extracted from medical literature, provides a basic data infrastructure for measuring medical knowledge. In general, the study of extracting SPO triples as computable knowledge unit from unstructured scientific text has been overwhelmingly focusing on scientific knowledge per se. Since the SPO triples would be possibly extracted from hypothetical, speculative statements or even conflicting and contradictory assertions, the knowledge status (i.e., the uncertainty), which serves as an integral and critical part of scientific knowledge has been largely overlooked. This article aims to put forward a framework for Medical Knowmetrics using the SPO triples as the knowledge unit and the uncertainty as the knowledge context. The lung cancer publications dataset is used to validate the proposed framework. The uncertainty of medical knowledge and how its status evolves over time indirectly reflect the strength of competing knowledge claims, and the probability of certainty for a given SPO triple. We try to discuss the new insights using the uncertainty-centric approaches to detect research fronts, and identify knowledge claims with high certainty level, in order to improve the efficacy of knowledge-driven decision support.