 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation Extraction Using Large Language Models: A Case Study on Acupuncture Point Locations
Apr 15, 2024In acupuncture therapy, the accurate location of acupoints is essential for its effectiveness. The advanced language understanding capabilities of large language models (LLMs) like Generative Pre-trained Transformers (GPT) present a significant opportunity for extracting relations related to acupoint locations from textual knowledge sources. This study aims to compare the performance of GPT with traditional deep learning models (Long Short-Term Memory (LSTM) and Bidirectional Encoder Representations from Transformers for Biomedical Text Mining (BioBERT)) in extracting acupoint-related location relations and assess the impact of pretraining and fine-tuning on GPT's performance. We utilized the World Health Organization Standard Acupuncture Point Locations in the Western Pacific Region (WHO Standard) as our corpus, which consists of descriptions of 361 acupoints. Five types of relations ('direction_of,' 'distance_of,' 'part_of,' 'near_acupoint,' and 'located_near') (n= 3,174) between acupoints were annotated. Five models were compared: BioBERT, LSTM, pre-trained GPT-3.5, fine-tuned GPT-3.5, as well as pre-trained GPT-4. Performance metrics included micro-average exact match precision, recall, and F1 scores. Our results demonstrate that fine-tuned GPT-3.5 consistently outperformed other models in F1 scores across all relation types. Overall, it achieved the highest micro-average F1 score of 0.92. This study underscores the effectiveness of LLMs like GPT in extracting relations related to acupoint locations, with implications for accurately modeling acupuncture knowledge and promoting standard implementation in acupuncture training and practice. The findings also contribute to advancing informatics applications in traditional and complementary medicine, showcasing the potential of LLMs in natural language processing.
Towards Medical Knowmetrics: Representing and Computing Medical Knowledge using Semantic Predications as the Knowledge Unit and the Uncertainty as the Knowledge Context
Oct 25, 2020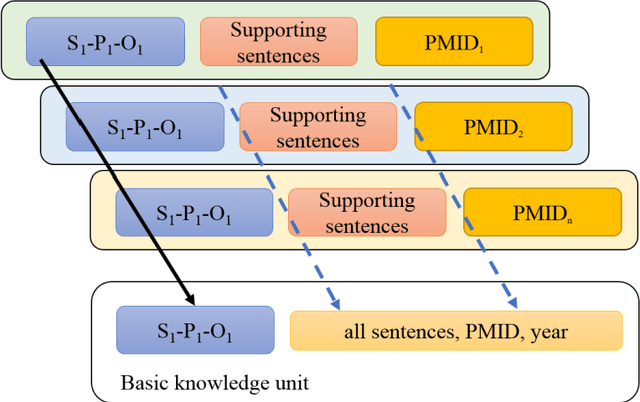
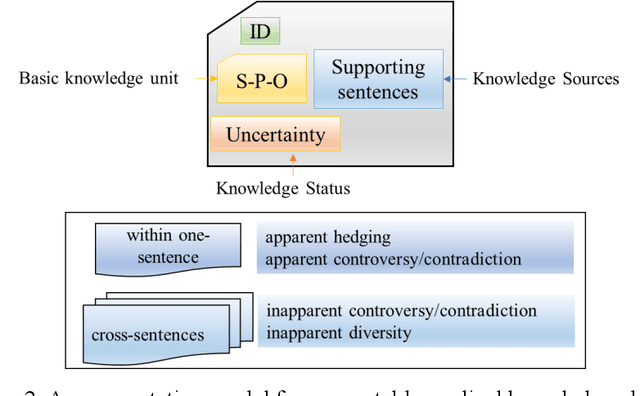


In China, Prof. Hongzhou Zhao and Zeyuan Liu are the pioneers of the concept "knowledge unit" and "knowmetrics" for measuring knowledge. However, the definition of "computable knowledge object" remains controversial so far in different fields. For example, it is defined as 1) quantitative scientific concept in natural science and engineering, 2) knowledge point in the field of education research, and 3) semantic predications, i.e., Subject-Predicate-Object (SPO) triples in biomedical fields. The Semantic MEDLINE Database (SemMedDB), a high-quality public repository of SPO triples extracted from medical literature, provides a basic data infrastructure for measuring medical knowledge. In general, the study of extracting SPO triples as computable knowledge unit from unstructured scientific text has been overwhelmingly focusing on scientific knowledge per se. Since the SPO triples would be possibly extracted from hypothetical, speculative statements or even conflicting and contradictory assertions, the knowledge status (i.e., the uncertainty), which serves as an integral and critical part of scientific knowledge has been largely overlooked. This article aims to put forward a framework for Medical Knowmetrics using the SPO triples as the knowledge unit and the uncertainty as the knowledge context. The lung cancer publications dataset is used to validate the proposed framework. The uncertainty of medical knowledge and how its status evolves over time indirectly reflect the strength of competing knowledge claims, and the probability of certainty for a given SPO triple. We try to discuss the new insights using the uncertainty-centric approaches to detect research fronts, and identify knowledge claims with high certainty level, in order to improve the efficacy of knowledge-driven decision support.