 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-FP: Differentially Private Forward Propagation for Large Models
Paper and Code
Dec 29, 2021

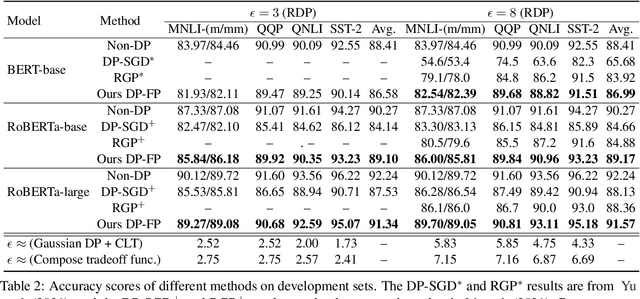
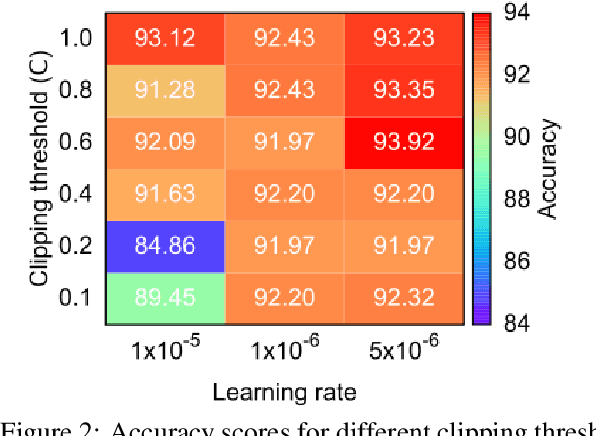
When applied to large-scale learning problems, the conventional wisdom on privacy-preserving deep learning, known as Differential Private Stochastic Gradient Descent (DP-SGD), has met with limited success due to significant performance degradation and high memory overhead when compared to the non-privacy counterpart. We show how to mitigate the performance drop by replacing the DP-SGD with a novel DP Forward-Propagation (DP-FP) followed by an off-the-shelf non-DP optimizer. Our DP-FP employs novel (1) representation clipping followed by noise addition in the forward propagation stage, as well as (2) micro-batch construction via subsampling to achieve DP amplification and reduce noise power to $1/M$, where $M$ is the number of micro-batch in a step. When training a classification model, our DP-FP with all of the privacy-preserving operations on the representation is innately free of gradient bias, total noise proportionally to model size, and memory issues in DP-SGD. As a result, our DP-FP outperforms cutting-edge DP-SGD while retaining the same level of privacy, and it approaches non-private baselines and significantly outperforms state-of-the-art DP-SGD variants. When applied to RoBERTa-large on four downstream tasks, for example, DP-FP achieves an average accuracy of 91.34\% with privacy budgets less than 3, representing a 3.81\% performance improvement over the state-of-the-art DP-SGD and only a 0.9\% loss compared to the non-private baseline but with a significantly lower privacy leakage risk.