 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocas: Your Models are Principled Initializers of Locally-Supported Parametric Memories
Feb 04, 2026In this paper, we aim to bridge test-time-training with a new type of parametric memory that can be flexibly offloaded from or merged into model parameters. We present Locas, a Locally-Supported parametric memory that shares the design of FFN blocks in modern transformers, allowing it to be flexibly permanentized into the model parameters while supporting efficient continual learning. We discuss two major variants of Locas: one with a conventional two-layer MLP design that has a clearer theoretical guarantee; the other one shares the same GLU-FFN structure with SOTA LLMs, and can be easily attached to existing models for both parameter-efficient and computation-efficient continual learning. Crucially, we show that proper initialization of such low-rank sideway-FFN-style memories -- performed in a principled way by reusing model parameters, activations and/or gradients -- is essential for fast convergence, improved generalization, and catastrophic forgetting prevention. We validate the proposed memory mechanism on the PG-19 whole-book language modeling and LoCoMo long-context dialogue question answering tasks. With only 0.02\% additional parameters in the lowest case, Locas-GLU is capable of storing the information from past context while maintaining a much smaller context window. In addition, we also test the model's general capability loss after memorizing the whole book with Locas, through comparative MMLU evaluation. Results show the promising ability of Locas to permanentize past context into parametric knowledge with minimized catastrophic forgetting of the model's existing internal knowledge.
Verified Critical Step Optimization for LLM Agents
Feb 03, 2026As large language model agents tackle increasingly complex long-horizon tasks, effective post-training becomes critical. Prior work faces fundamental challenges: outcome-only rewards fail to precisely attribute credit to intermediate steps, estimated step-level rewards introduce systematic noise, and Monte Carlo sampling approaches for step reward estimation incur prohibitive computational cost. Inspired by findings that only a small fraction of high-entropy tokens drive effective RL for reasoning, we propose Critical Step Optimization (CSO), which focuses preference learning on verified critical steps, decision points where alternate actions demonstrably flip task outcomes from failure to success. Crucially, our method starts from failed policy trajectories rather than expert demonstrations, directly targeting the policy model's weaknesses. We use a process reward model (PRM) to identify candidate critical steps, leverage expert models to propose high-quality alternatives, then continue execution from these alternatives using the policy model itself until task completion. Only alternatives that the policy successfully executes to correct outcomes are verified and used as DPO training data, ensuring both quality and policy reachability. This yields fine-grained, verifiable supervision at critical decisions while avoiding trajectory-level coarseness and step-level noise. Experiments on GAIA-Text-103 and XBench-DeepSearch show that CSO achieves 37% and 26% relative improvement over the SFT baseline and substantially outperforms other post-training methods, while requiring supervision at only 16% of trajectory steps. This demonstrates the effectiveness of selective verification-based learning for agent post-training.
Exploring Information Seeking Agent Consolidation
Jan 31, 2026Information-seeking agents have emerged as a powerful paradigm for solving knowledge-intensive tasks. Existing information-seeking agents are typically specialized for open web, documents, or local knowledge bases, which constrains scalability and cross-domain generalization. In this work, we investigate how to consolidate heterogeneous information-seeking agents into a single foundation agentic model. We study two complementary consolidation strategies: data-level consolidation, which jointly trains a unified model on a mixture of domain-specific datasets, and parameter-level consolidation, which merges independently trained agent models at the parameter level. Our analysis compares these approaches in terms of performance retention, cross-domain generalization, and interference across information-seeking behaviors. Our results show that data-level consolidation remains a strong and stable baseline, while parameter-level consolidation offers a promising, efficient alternative but suffers from interference and robustness challenges. We further identify key design factors for effective agent consolidation at the parameter level, including fine-grained merging granularity, awareness of task heterogeneity, and principled consensus strategy.
Save the Good Prefix: Precise Error Penalization via Process-Supervised RL to Enhance LLM Reasoning
Jan 26, 2026Reinforcement learning (RL) has emerged as a powerful framework for improving the reasoning capabilities of large language models (LLMs). However, most existing RL approaches rely on sparse outcome rewards, which fail to credit correct intermediate steps in partially successful solutions. Process reward models (PRMs) offer fine-grained step-level supervision, but their scores are often noisy and difficult to evaluate. As a result, recent PRM benchmarks focus on a more objective capability: detecting the first incorrect step in a reasoning path. However, this evaluation target is misaligned with how PRMs are typically used in RL, where their step-wise scores are treated as raw rewards to maximize. To bridge this gap, we propose Verifiable Prefix Policy Optimization (VPPO), which uses PRMs only to localize the first error during RL. Given an incorrect rollout, VPPO partitions the trajectory into a verified correct prefix and an erroneous suffix based on the first error, rewarding the former while applying targeted penalties only after the detected mistake. This design yields stable, interpretable learning signals and improves credit assignment. Across multiple reasoning benchmarks, VPPO consistently outperforms sparse-reward RL and prior PRM-guided baselines on both Pass@1 and Pass@K.
Inference-Time Scaling of Verification: Self-Evolving Deep Research Agents via Test-Time Rubric-Guided Verification
Jan 22, 2026Recent advances in Deep Research Agents (DRAs) are transforming automated knowledge discovery and problem-solving. While the majority of existing efforts focus on enhancing policy capabilities via post-training, we propose an alternative paradigm: self-evolving the agent's ability by iteratively verifying the policy model's outputs, guided by meticulously crafted rubrics. This approach gives rise to the inference-time scaling of verification, wherein an agent self-improves by evaluating its generated answers to produce iterative feedback and refinements. We derive the rubrics based on an automatically constructed DRA Failure Taxonomy, which systematically classifies agent failures into five major categories and thirteen sub-categories. We present DeepVerifier, a rubrics-based outcome reward verifier that leverages the asymmetry of verification and outperforms vanilla agent-as-judge and LLM judge baselines by 12%-48% in meta-evaluation F1 score. To enable practical self-evolution, DeepVerifier integrates as a plug-and-play module during test-time inference. The verifier produces detailed rubric-based feedback, which is fed back to the agent for iterative bootstrapping, refining responses without additional training. This test-time scaling delivers 8%-11% accuracy gains on challenging subsets of GAIA and XBench-DeepResearch when powered by capable closed-source LLMs. Finally, to support open-source advancement, we release DeepVerifier-4K, a curated supervised fine-tuning dataset of 4,646 high-quality agent steps focused on DRA verification. These examples emphasize reflection and self-critique, enabling open models to develop robust verification capabilities.
RAGShaper: Eliciting Sophisticated Agentic RAG Skills via Automated Data Synthesis
Jan 13, 2026Agentic Retrieval-Augmented Generation (RAG) empowers large language models to autonomously plan and retrieve information for complex problem-solving. However, the development of robust agents is hindered by the scarcity of high-quality training data that reflects the noise and complexity of real-world retrieval environments. Conventional manual annotation is unscalable and often fails to capture the dynamic reasoning strategies required to handle retrieval failures. To bridge this gap, we introduce RAGShaper, a novel data synthesis framework designed to automate the construction of RAG tasks and robust agent trajectories. RAGShaper incorporates an InfoCurator to build dense information trees enriched with adversarial distractors spanning Perception and Cognition levels. Furthermore, we propose a constrained navigation strategy that forces a teacher agent to confront these distractors, thereby eliciting trajectories that explicitly demonstrate error correction and noise rejection. Comprehensive experiments confirm that models trained on our synthesized corpus significantly outperform existing baselines, exhibiting superior robustness in noise-intensive and complex retrieval tasks.
DocDancer: Towards Agentic Document-Grounded Information Seeking
Jan 08, 2026Document Question Answering (DocQA) focuses on answering questions grounded in given documents, yet existing DocQA agents lack effective tool utilization and largely rely on closed-source models. In this work, we introduce DocDancer, an end-to-end trained open-source Doc agent. We formulate DocQA as an information-seeking problem and propose a tool-driven agent framework that explicitly models document exploration and comprehension. To enable end-to-end training of such agents, we introduce an Exploration-then-Synthesis data synthesis pipeline that addresses the scarcity of high-quality training data for DocQA. Training on the synthesized data, the trained models on two long-context document understanding benchmarks, MMLongBench-Doc and DocBench, show their effectiveness. Further analysis provides valuable insights for the agentic tool design and synthetic data.
Stable and Efficient Single-Rollout RL for Multimodal Reasoning
Dec 20, 2025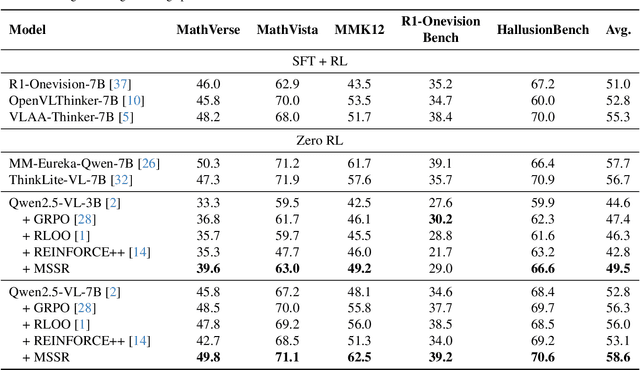
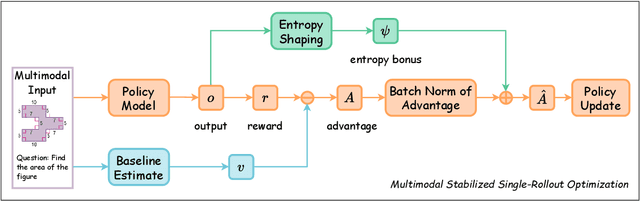

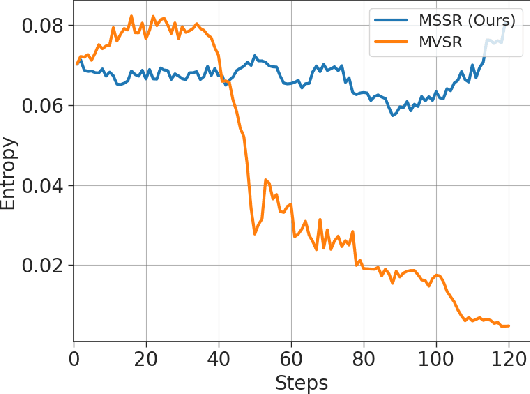
Reinforcement Learning with Verifiable Rewards (RLVR) has become a key paradigm to improve the reasoning capabilities of Multimodal Large Language Models (MLLMs). However, prevalent group-based algorithms such as GRPO require multi-rollout sampling for each prompt. While more efficient single-rollout variants have recently been explored in text-only settings, we find that they suffer from severe instability in multimodal contexts, often leading to training collapse. To address this training efficiency-stability trade-off, we introduce $\textbf{MSSR}$ (Multimodal Stabilized Single-Rollout), a group-free RLVR framework that achieves both stable optimization and effective multimodal reasoning performance. MSSR achieves this via an entropy-based advantage-shaping mechanism that adaptively regularizes advantage magnitudes, preventing collapse and maintaining training stability. While such mechanisms have been used in group-based RLVR, we show that in the multimodal single-rollout setting they are not merely beneficial but essential for stability. In in-distribution evaluations, MSSR demonstrates superior training compute efficiency, achieving similar validation accuracy to the group-based baseline with half the training steps. When trained for the same number of steps, MSSR's performance surpasses the group-based baseline and shows consistent generalization improvements across five diverse reasoning-intensive benchmarks. Together, these results demonstrate that MSSR enables stable, compute-efficient, and effective RLVR for complex multimodal reasoning tasks.
Can LLMs Guide Their Own Exploration? Gradient-Guided Reinforcement Learning for LLM Reasoning
Dec 17, 2025
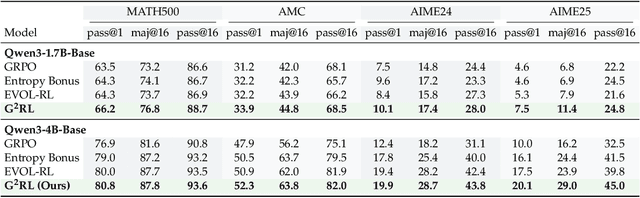
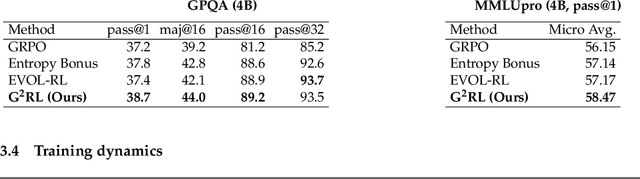
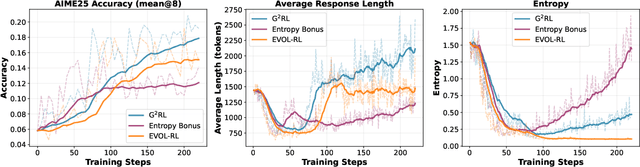
Reinforcement learning has become essential for strengthening the reasoning abilities of large language models, yet current exploration mechanisms remain fundamentally misaligned with how these models actually learn. Entropy bonuses and external semantic comparators encourage surface level variation but offer no guarantee that sampled trajectories differ in the update directions that shape optimization. We propose G2RL, a gradient guided reinforcement learning framework in which exploration is driven not by external heuristics but by the model own first order update geometry. For each response, G2RL constructs a sequence level feature from the model final layer sensitivity, obtainable at negligible cost from a standard forward pass, and measures how each trajectory would reshape the policy by comparing these features within a sampled group. Trajectories that introduce novel gradient directions receive a bounded multiplicative reward scaler, while redundant or off manifold updates are deemphasized, yielding a self referential exploration signal that is naturally aligned with PPO style stability and KL control. Across math and general reasoning benchmarks (MATH500, AMC, AIME24, AIME25, GPQA, MMLUpro) on Qwen3 base 1.7B and 4B models, G2RL consistently improves pass@1, maj@16, and pass@k over entropy based GRPO and external embedding methods. Analyzing the induced geometry, we find that G2RL expands exploration into substantially more orthogonal and often opposing gradient directions while maintaining semantic coherence, revealing that a policy own update space provides a far more faithful and effective basis for guiding exploration in large language model reinforcement learning.
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning
Nov 17, 2025Recent advances in large language models have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.