 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFALAT: Tracing Failures in LLM Agent Trajectories via Dependency-Guided Search
May 30, 2026LLM-based agents increasingly solve complex tasks through long trajectories involving reasoning steps, tool calls, and inter-agent communication. However, when these agents fail, it is often unclear which agent caused the failure and which step introduced the decisive error. This attribution problem is challenging because mistakes can propagate across the trajectory: later actions may appear incorrect, but only because they depend on an earlier corrupted state. Therefore, failure attribution cannot be treated as independent step-level classification. We propose FALAT, a diagnostic framework for failure attribution in LLM agent trajectories. FALAT frames attribution as a dependency-guided search problem. It first constructs an expectation of how the task should be solved and uses this expectation to identify suspicious regions in the trajectory. It then traces dependencies among decisions, tool outputs, and agent messages to distinguish error-introducing steps from steps that merely inherit or propagate prior mistakes. Finally, FALAT evaluates whether correcting a candidate step would be sufficient to recover the expected outcome, allowing it to identify both the responsible agent and the decisive failure step. We evaluate FALAT on the Who&When benchmark, which includes both algorithm-generated and hand-crafted multi-agent failure trajectories. The results show that FALAT consistently improves responsible-agent and decisive-step attribution. Its best configurations achieve 46.0% step-level accuracy on algorithm-generated trajectories and 29.1% on the more challenging hand-crafted trajectories, outperforming specialized attribution baselines and direct prompting with standalone LLMs. These findings suggest that dependency-aware reasoning is essential for reliable failure diagnosis in LLM agent systems.
SSDAU: Structured Semantic Data Augmentation for Joint Entity and Relation Extraction
May 28, 2026Joint Entity and Relation Extraction (JERE) is highly sensitive to training data quality, making data augmentation a natural way to improve generalization. However, existing augmentation methods often weaken entity relevance and disrupt semantic structure, limiting their effectiveness for JERE. In this paper, we propose \textbf{Structured Semantic Data Augmentation (SSDAU)}, a method designed to preserve triple-aware semantic structure during augmentation. SSDAU segments text by entity labels, captures semantic features through context-aware encoding, and restructures entity semantics to generate augmented data. To distinguish semantically similar entities, SSDAU combines contextualized embeddings with traditional similarity scores. To reduce topic inconsistency, we apply BERTopic-based filtering to remove irrelevant augmentations. We evaluate SSDAU on datasets with different annotation types and compare its performance on five representative JERE models against seven popular augmentation baselines. Experiments show that SSDAU generates semantically consistent data, is more robust to ambiguity than non-LLM methods (8.95\% vs. 23.58\% average relative F1 decrease), and significantly outperforms strong alternatives in most settings.
Learning First Integrals via Backward-Generated Data and Guided Reinforcement Learning
May 20, 2026The discovery of first integrals is of fundamental scientific importance for understanding conservation laws in dynamical systems. However, existing symbolic computation tools and Large Language Models (LLMs) remain limited on this task because high-quality training data are scarce and successful solutions often depend on mathematical intuition. This paper presents FISolver, an LLM-based solver developed to address this challenge. First, we introduce a "Backward Generation" algorithm that systematically builds large-scale datasets of (differential equation, first integral) pairs by deriving differential equations from sampled integrals, thereby alleviating the data scarcity bottleneck. Second, we apply supervised fine-tuning to a compact mathematical model and further improve its performance through reinforcement learning with a Levenshtein Distance-based shaped reward. In addition, we design data synthesis and blending strategies that support effective adaptation to difficult problem families from sparse examples. Experiments show that FISolver, while requiring substantially lower computational cost, significantly outperforms larger mathematical LLMs and commercial solvers such as Mathematica on challenging benchmarks, indicating a new data-driven route for automated discovery of first integrals.
GRPO and Reflection Reward for Mathematical Reasoning in Large Language Models
Mar 14, 2026The enhancement of reasoning capabilities in large language models (LLMs) has garnered significant attention, with supervised fine-tuning (SFT) and reinforcement learning emerging as dominant paradigms. While recent studies recognize the importance of reflection in reasoning processes, existing methodologies seldom address proactive reflection encouragement during training. This study focuses on mathematical reasoning by proposing a four-stage framework integrating Group Relative Policy Optimization (GRPO) with reflection reward mechanisms to strengthen LLMs' self-reflective capabilities. Besides, this approach incorporates established accuracy and format reward. Experimental results demonstrate GRPO's state-of-the-art performance through reflection-encouraged training, with ablation studies confirming the reflection reward's pivotal role. Comparative evaluations demonstrate full-parameter SFT's superiority over low-rank adaptation (LoRA) despite heightened computational demands. Building on these cumulative findings, this research substantiates GRPO's methodological significance in post-training optimization and envisions its potential to serve as a pivotal enabler for future LLM-based intelligent agents through the synergistic integration of cognitive rewards with dynamic environmental interactions.
Matrix Completion Via Reweighted Logarithmic Norm Minimization
Dec 24, 2025Low-rank matrix completion (LRMC) has demonstrated remarkable success in a wide range of applications. To address the NP-hard nature of the rank minimization problem, the nuclear norm is commonly used as a convex and computationally tractable surrogate for the rank function. However, this approach often yields suboptimal solutions due to the excessive shrinkage of singular values. In this letter, we propose a novel reweighted logarithmic norm as a more effective nonconvex surrogate, which provides a closer approximation than many existing alternatives. We efficiently solve the resulting optimization problem by employing the alternating direction method of multipliers (ADMM). Experimental results on image inpainting demonstrate that the proposed method achieves superior performance compared to state-of-the-art LRMC approaches, both in terms of visual quality and quantitative metrics.
RaSA: Rank-Sharing Low-Rank Adaptation
Mar 16, 2025Low-rank adaptation (LoRA) has been prominently employed for parameter-efficient fine-tuning of large language models (LLMs). However, the limited expressive capacity of LoRA, stemming from the low-rank constraint, has been recognized as a bottleneck, particularly in rigorous tasks like code generation and mathematical reasoning. To address this limitation, we introduce Rank-Sharing Low-Rank Adaptation (RaSA), an innovative extension that enhances the expressive capacity of LoRA by leveraging partial rank sharing across layers. By forming a shared rank pool and applying layer-specific weighting, RaSA effectively increases the number of ranks without augmenting parameter overhead. Our theoretically grounded and empirically validated approach demonstrates that RaSA not only maintains the core advantages of LoRA but also significantly boosts performance in challenging code and math tasks. Code, data and scripts are available at: https://github.com/zwhe99/RaSA.
WarmFed: Federated Learning with Warm-Start for Globalization and Personalization Via Personalized Diffusion Models
Mar 05, 2025Federated Learning (FL) stands as a prominent distributed learning paradigm among multiple clients to achieve a unified global model without privacy leakage. In contrast to FL, Personalized federated learning aims at serving for each client in achieving persoanlized model. However, previous FL frameworks have grappled with a dilemma: the choice between developing a singular global model at the server to bolster globalization or nurturing personalized model at the client to accommodate personalization. Instead of making trade-offs, this paper commences its discourse from the pre-trained initialization, obtaining resilient global information and facilitating the development of both global and personalized models. Specifically, we propose a novel method called WarmFed to achieve this. WarmFed customizes Warm-start through personalized diffusion models, which are generated by local efficient fine-tunining (LoRA). Building upon the Warm-Start, we advance a server-side fine-tuning strategy to derive the global model, and propose a dynamic self-distillation (DSD) to procure more resilient personalized models simultaneously. Comprehensive experiments underscore the substantial gains of our approach across both global and personalized models, achieved within just one-shot and five communication(s).
The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning Models
Mar 04, 2025
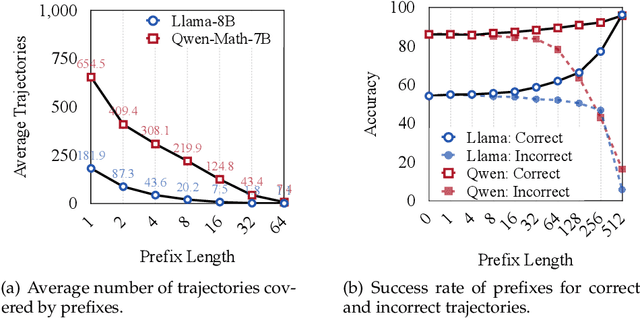
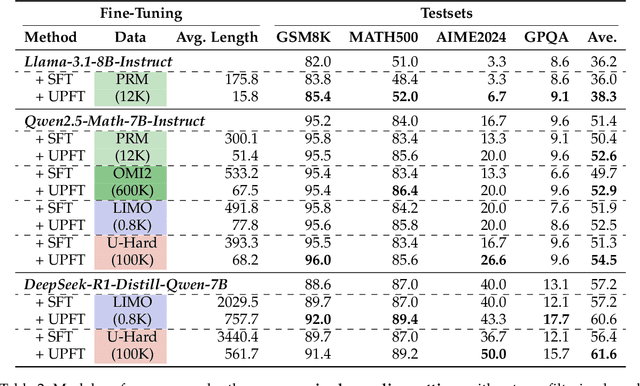

Improving the reasoning capabilities of large language models (LLMs) typically requires supervised fine-tuning with labeled data or computationally expensive sampling. We introduce Unsupervised Prefix Fine-Tuning (UPFT), which leverages the observation of Prefix Self-Consistency -- the shared initial reasoning steps across diverse solution trajectories -- to enhance LLM reasoning efficiency. By training exclusively on the initial prefix substrings (as few as 8 tokens), UPFT removes the need for labeled data or exhaustive sampling. Experiments on reasoning benchmarks show that UPFT matches the performance of supervised methods such as Rejection Sampling Fine-Tuning, while reducing training time by 75% and sampling cost by 99%. Further analysis reveals that errors tend to appear in later stages of the reasoning process and that prefix-based training preserves the model's structural knowledge. This work demonstrates how minimal unsupervised fine-tuning can unlock substantial reasoning gains in LLMs, offering a scalable and resource-efficient alternative to conventional approaches.
MFP-VTON: Enhancing Mask-Free Person-to-Person Virtual Try-On via Diffusion Transformer
Feb 03, 2025



The garment-to-person virtual try-on (VTON) task, which aims to generate fitting images of a person wearing a reference garment, has made significant strides. However, obtaining a standard garment is often more challenging than using the garment already worn by the person. To improve ease of use, we propose MFP-VTON, a Mask-Free framework for Person-to-Person VTON. Recognizing the scarcity of person-to-person data, we adapt a garment-to-person model and dataset to construct a specialized dataset for this task. Our approach builds upon a pretrained diffusion transformer, leveraging its strong generative capabilities. During mask-free model fine-tuning, we introduce a Focus Attention loss to emphasize the garment of the reference person and the details outside the garment of the target person. Experimental results demonstrate that our model excels in both person-to-person and garment-to-person VTON tasks, generating high-fidelity fitting images.
IGR: Improving Diffusion Model for Garment Restoration from Person Image
Dec 16, 2024



Garment restoration, the inverse of virtual try-on task, focuses on restoring standard garment from a person image, requiring accurate capture of garment details. However, existing methods often fail to preserve the identity of the garment or rely on complex processes. To address these limitations, we propose an improved diffusion model for restoring authentic garments. Our approach employs two garment extractors to independently capture low-level features and high-level semantics from the person image. Leveraging a pretrained latent diffusion model, these features are integrated into the denoising process through garment fusion blocks, which combine self-attention and cross-attention layers to align the restored garment with the person image. Furthermore, a coarse-to-fine training strategy is introduced to enhance the fidelity and authenticity of the generated garments. Experimental results demonstrate that our model effectively preserves garment identity and generates high-quality restorations, even in challenging scenarios such as complex garments or those with occlusions.