 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Task Offloading and Channel Allocation in Spatial-Temporal Dynamic for MEC Networks
May 07, 2025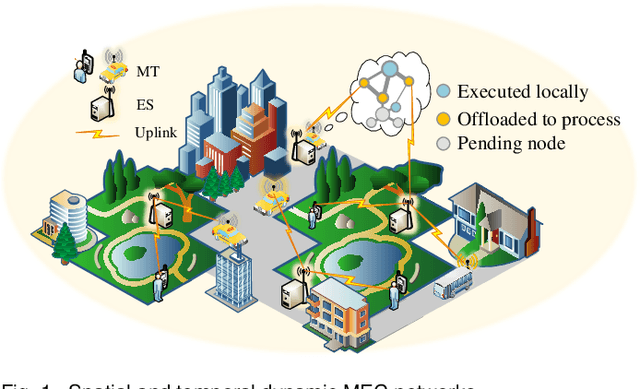
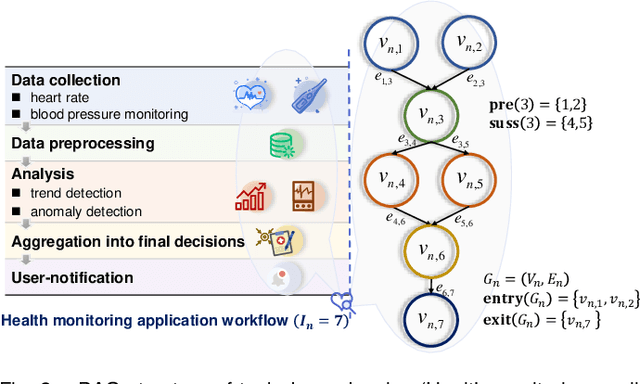
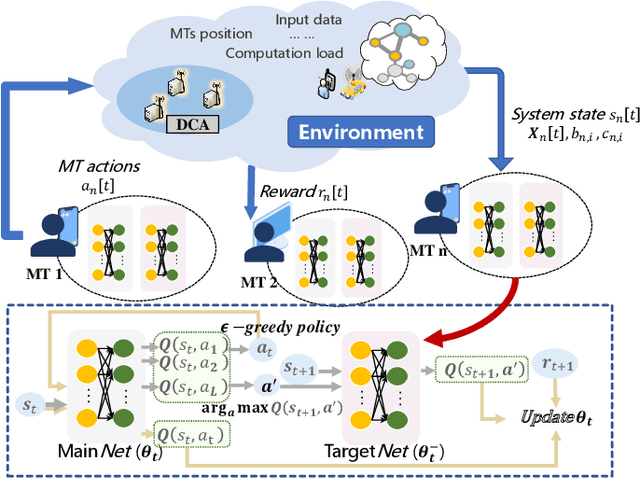
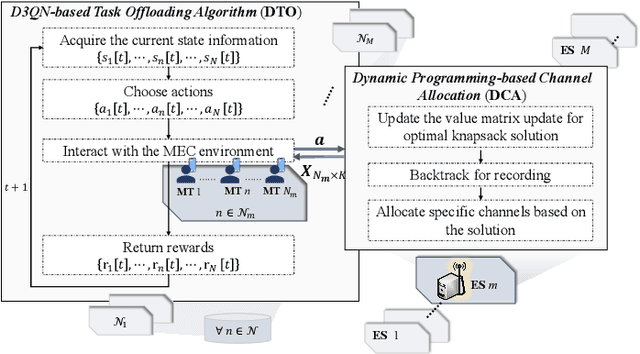
Computation offloading and resource allocation are critical in mobile edge computing (MEC) systems to handle the massive and complex requirements of applications restricted by limited resources. In a multi-user multi-server MEC network, the mobility of terminals causes computing requests to be dynamically distributed in space. At the same time, the non-negligible dependencies among tasks in some specific applications impose temporal correlation constraints on the solution as well, leading the time-adjacent tasks to experience varying resource availability and competition from parallel counterparts. To address such dynamic spatial-temporal characteristics as a challenge in the allocation of communication and computation resources, we formulate a long-term delay-energy trade-off cost minimization problem in the view of jointly optimizing task offloading and resource allocation. We begin by designing a priority evaluation scheme to decouple task dependencies and then develop a grouped Knapsack problem for channel allocation considering the current data load and channel status. Afterward, in order to meet the rapid response needs of MEC systems, we exploit the double duel deep Q network (D3QN) to make offloading decisions and integrate channel allocation results into the reward as part of the dynamic environment feedback in D3QN, constituting the joint optimization of task offloading and channel allocation. Finally, comprehensive simulations demonstrate the performance of the proposed algorithm in the delay-energy trade-off cost and its adaptability for various applications.
WarmFed: Federated Learning with Warm-Start for Globalization and Personalization Via Personalized Diffusion Models
Mar 05, 2025Federated Learning (FL) stands as a prominent distributed learning paradigm among multiple clients to achieve a unified global model without privacy leakage. In contrast to FL, Personalized federated learning aims at serving for each client in achieving persoanlized model. However, previous FL frameworks have grappled with a dilemma: the choice between developing a singular global model at the server to bolster globalization or nurturing personalized model at the client to accommodate personalization. Instead of making trade-offs, this paper commences its discourse from the pre-trained initialization, obtaining resilient global information and facilitating the development of both global and personalized models. Specifically, we propose a novel method called WarmFed to achieve this. WarmFed customizes Warm-start through personalized diffusion models, which are generated by local efficient fine-tunining (LoRA). Building upon the Warm-Start, we advance a server-side fine-tuning strategy to derive the global model, and propose a dynamic self-distillation (DSD) to procure more resilient personalized models simultaneously. Comprehensive experiments underscore the substantial gains of our approach across both global and personalized models, achieved within just one-shot and five communication(s).
MFP-VTON: Enhancing Mask-Free Person-to-Person Virtual Try-On via Diffusion Transformer
Feb 03, 2025



The garment-to-person virtual try-on (VTON) task, which aims to generate fitting images of a person wearing a reference garment, has made significant strides. However, obtaining a standard garment is often more challenging than using the garment already worn by the person. To improve ease of use, we propose MFP-VTON, a Mask-Free framework for Person-to-Person VTON. Recognizing the scarcity of person-to-person data, we adapt a garment-to-person model and dataset to construct a specialized dataset for this task. Our approach builds upon a pretrained diffusion transformer, leveraging its strong generative capabilities. During mask-free model fine-tuning, we introduce a Focus Attention loss to emphasize the garment of the reference person and the details outside the garment of the target person. Experimental results demonstrate that our model excels in both person-to-person and garment-to-person VTON tasks, generating high-fidelity fitting images.
IGR: Improving Diffusion Model for Garment Restoration from Person Image
Dec 16, 2024



Garment restoration, the inverse of virtual try-on task, focuses on restoring standard garment from a person image, requiring accurate capture of garment details. However, existing methods often fail to preserve the identity of the garment or rely on complex processes. To address these limitations, we propose an improved diffusion model for restoring authentic garments. Our approach employs two garment extractors to independently capture low-level features and high-level semantics from the person image. Leveraging a pretrained latent diffusion model, these features are integrated into the denoising process through garment fusion blocks, which combine self-attention and cross-attention layers to align the restored garment with the person image. Furthermore, a coarse-to-fine training strategy is introduced to enhance the fidelity and authenticity of the generated garments. Experimental results demonstrate that our model effectively preserves garment identity and generates high-quality restorations, even in challenging scenarios such as complex garments or those with occlusions.
Computing Offloading and Semantic Compression for Intelligent Computing Tasks in MEC Systems
Jul 06, 2023



This paper investigates the intelligent computing task-oriented computing offloading and semantic compression in mobile edge computing (MEC) systems. With the popularity of intelligent applications in various industries, terminals increasingly need to offload intelligent computing tasks with complex demands to MEC servers for computing, which is a great challenge for bandwidth and computing capacity allocation in MEC systems. Considering the accuracy requirement of intelligent computing tasks, we formulate an optimization problem of computing offloading and semantic compression. We jointly optimize the system utility which are represented as computing accuracy and task delay respectively to acquire the optimized system utility. To solve the proposed optimization problem, we decompose it into computing capacity allocation subproblem and compression offloading subproblem and obtain solutions through convex optimization and successive convex approximation. After that, the offloading decisions, computing capacity and compressed ratio are obtained in closed forms. We design the computing offloading and semantic compression algorithm for intelligent computing tasks in MEC systems then. Simulation results represent that our algorithm converges quickly and acquires better performance and resource utilization efficiency through the trend with total number of users and computing capacity compared with benchmarks.
Everyone Can Be Picasso? A Computational Framework into the Myth of Human versus AI Painting
Apr 17, 2023



The recent advances of AI technology, particularly in AI-Generated Content (AIGC), have enabled everyone to easily generate beautiful paintings with simple text description. With the stunning quality of AI paintings, it is widely questioned whether there still exists difference between human and AI paintings and whether human artists will be replaced by AI. To answer these questions, we develop a computational framework combining neural latent space and aesthetics features with visual analytics to investigate the difference between human and AI paintings. First, with categorical comparison of human and AI painting collections, we find that AI artworks show distributional difference from human artworks in both latent space and some aesthetic features like strokes and sharpness, while in other aesthetic features like color and composition there is less difference. Second, with individual artist analysis of Picasso, we show human artists' strength in evolving new styles compared to AI. Our findings provide concrete evidence for the existing discrepancies between human and AI paintings and further suggest improvements of AI art with more consideration of aesthetics and human artists' involvement.
Information fusion approach for biomass estimation in a plateau mountainous forest using a synergistic system comprising UAS-based digital camera and LiDAR
Apr 14, 2022

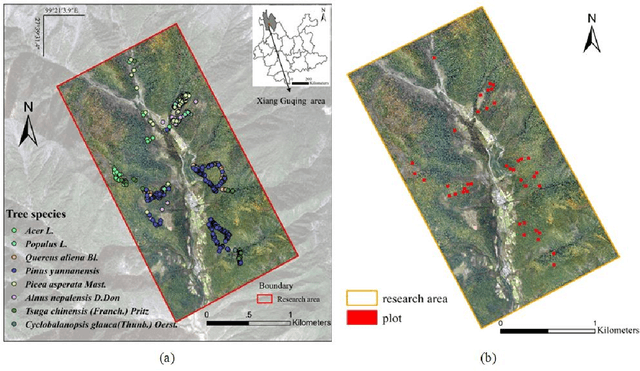

Forest land plays a vital role in global climate, ecosystems, farming and human living environments. Therefore, forest biomass estimation methods are necessary to monitor changes in the forest structure and function, which are key data in natural resources research. Although accurate forest biomass measurements are important in forest inventory and assessments, high-density measurements that involve airborne light detection and ranging (LiDAR) at a low flight height in large mountainous areas are highly expensive. The objective of this study was to quantify the aboveground biomass (AGB) of a plateau mountainous forest reserve using a system that synergistically combines an unmanned aircraft system (UAS)-based digital aerial camera and LiDAR to leverage their complementary advantages. In this study, we utilized digital aerial photogrammetry (DAP), which has the unique advantages of speed, high spatial resolution, and low cost, to compensate for the deficiency of forestry inventory using UAS-based LiDAR that requires terrain-following flight for high-resolution data acquisition. Combined with the sparse LiDAR points acquired by using a high-altitude and high-speed UAS for terrain extraction, dense normalized DAP point clouds can be obtained to produce an accurate and high-resolution canopy height model (CHM). Based on the CHM and spectral attributes obtained from multispectral images, we estimated and mapped the AGB of the region of interest with considerable cost efficiency. Our study supports the development of predictive models for large-scale wall-to-wall AGB mapping by leveraging the complementarity between DAP and LiDAR measurements. This work also reveals the potential of utilizing a UAS-based digital camera and LiDAR synergistically in a plateau mountainous forest area.
Pairwise Point Cloud Registration using Graph Matching and Rotation-invariant Features
May 05, 2021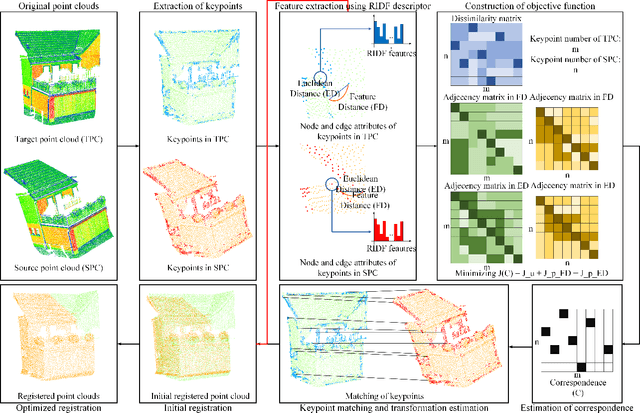


Registration is a fundamental but critical task in point cloud processing, which usually depends on finding element correspondence from two point clouds. However, the finding of reliable correspondence relies on establishing a robust and discriminative description of elements and the correct matching of corresponding elements. In this letter, we develop a coarse-to-fine registration strategy, which utilizes rotation-invariant features and a new weighted graph matching method for iteratively finding correspondence. In the graph matching method, the similarity of nodes and edges in Euclidean and feature space are formulated to construct the optimization function. The proposed strategy is evaluated using two benchmark datasets and compared with several state-of-the-art methods. Regarding the experimental results, our proposed method can achieve a fine registration with rotation errors of less than 0.2 degrees and translation errors of less than 0.1m.
GraNet: Global Relation-aware Attentional Network for ALS Point Cloud Classification
Dec 24, 2020
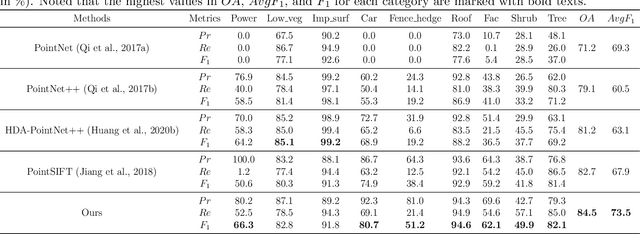
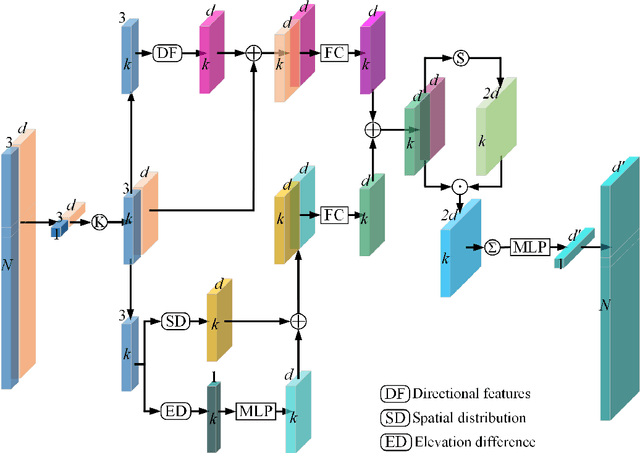
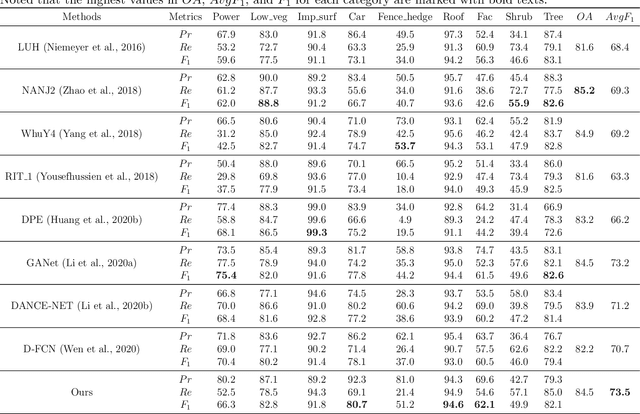
In this work, we propose a novel neural network focusing on semantic labeling of ALS point clouds, which investigates the importance of long-range spatial and channel-wise relations and is termed as global relation-aware attentional network (GraNet). GraNet first learns local geometric description and local dependencies using a local spatial discrepancy attention convolution module (LoSDA). In LoSDA, the orientation information, spatial distribution, and elevation differences are fully considered by stacking several local spatial geometric learning modules and the local dependencies are embedded by using an attention pooling module. Then, a global relation-aware attention module (GRA), consisting of a spatial relation-aware attention module (SRA) and a channel relation aware attention module (CRA), are investigated to further learn the global spatial and channel-wise relationship between any spatial positions and feature vectors. The aforementioned two important modules are embedded in the multi-scale network architecture to further consider scale changes in large urban areas. We conducted comprehensive experiments on two ALS point cloud datasets to evaluate the performance of our proposed framework. The results show that our method can achieve higher classification accuracy compared with other commonly used advanced classification methods. The overall accuracy (OA) of our method on the ISPRS benchmark dataset can be improved to 84.5% to classify nine semantic classes, with an average F1 measure (AvgF1) of 73.5%. In detail, we have following F1 values for each object class: powerlines: 66.3%, low vegetation: 82.8%, impervious surface: 91.8%, car: 80.7%, fence: 51.2%, roof: 94.6%, facades: 62.1%, shrub: 49.9%, trees: 82.1%. Besides, experiments were conducted using a new ALS point cloud dataset covering highly dense urban areas.
So2Sat LCZ42: A Benchmark Dataset for Global Local Climate Zones Classification
Dec 19, 2019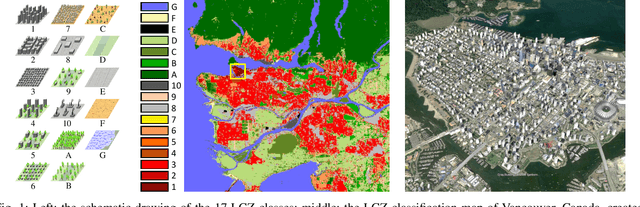
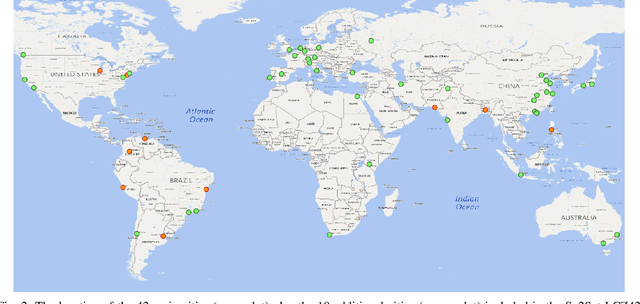

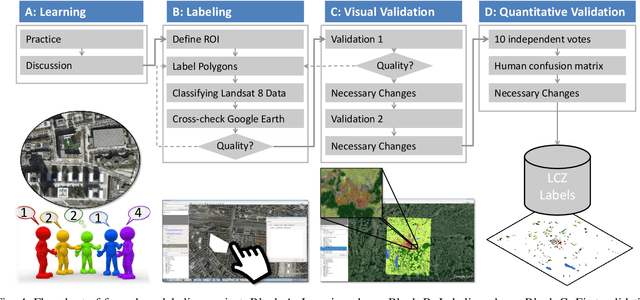
Access to labeled reference data is one of the grand challenges in supervised machine learning endeavors. This is especially true for an automated analysis of remote sensing images on a global scale, which enables us to address global challenges such as urbanization and climate change using state-of-the-art machine learning techniques. To meet these pressing needs, especially in urban research, we provide open access to a valuable benchmark dataset named "So2Sat LCZ42," which consists of local climate zone (LCZ) labels of about half a million Sentinel-1 and Sentinel-2 image patches in 42 urban agglomerations (plus 10 additional smaller areas) across the globe. This dataset was labeled by 15 domain experts following a carefully designed labeling work flow and evaluation process over a period of six months. As rarely done in other labeled remote sensing dataset, we conducted rigorous quality assessment by domain experts. The dataset achieved an overall confidence of 85%. We believe this LCZ dataset is a first step towards an unbiased globallydistributed dataset for urban growth monitoring using machine learning methods, because LCZ provide a rather objective measure other than many other semantic land use and land cover classifications. It provides measures of the morphology, compactness, and height of urban areas, which are less dependent on human and culture. This dataset can be accessed from http://doi.org/10.14459/2018mp1483140.