 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAI: Preserving Amplitude Information in Representation-Based Time-Series Anomaly Detection
Jun 08, 2026Representation-based time-series anomaly detection algorithms significantly outperform other methods on diverse anomaly detection tasks. However, we notice that they suffer from a major limitation in our evaluation - their learned embeddings are often amplitude-agnostic. Losing amplitude information can degrade performance on amplitude related anomalies, and this failure is prevalent across all existing representation-based methods. To address aforementioned issues, we propose a new anomaly scoring scheme named PAI. PAI consists of two complementary modules, a diagnostic module and a final score augmentation function. The diagnostic module compares cosine and Euclidean scoring on the same representation bank to test whether amplitude information is already captured in the learned representation. Then in final score augmentation function, PAI computes a point-wise median and MAD deviation score and a local mean-shift score-which are fused with the representation score to produce the final anomaly score. On the TSB-AD-U-Eva and TAB UV datasets, PAI improves all four evaluated representation-based methods across every reported metric, achieving average VUS-PR gains of 98.4% and 36.8%, respectively. Among all evaluated combinations, PaAno + PAI achieves the best performance, outperforming the state-of-the-art method by 15%. Further evaluation on bootstrap confidence intervals, anomaly-type breakdowns, and a TS2Vec input-normalization ablation further support the proposed scheme. These results suggest that explicitly retaining amplitude information is important for representation-based time-series anomaly detection, which has been underemphasized in existing scoring schemes. Code is available at: https://github.com/pantheon5100/PAI
Cinematic Audio Source Separation Using Visual Cues
Mar 27, 2026Cinematic Audio Source Separation (CASS) aims to decompose mixed film audio into speech, music, and sound effects, enabling applications like dubbing and remastering. Existing CASS approaches are audio-only, overlooking the inherent audio-visual nature of films, where sounds often align with visual cues. We present the first framework for audio-visual CASS (AV-CASS), leveraging visual context to enhance separation quality. Our method formulates CASS as a conditional generative modeling problem using conditional flow matching, enabling multimodal audio source separation. To address the lack of cinematic datasets with isolated sound tracks, we introduce a training data synthesis pipeline that pairs in-the-wild audio and video streams (e.g., facial videos for speech, scene videos for effects) and design a dedicated visual encoder for this dual-stream setup. Trained entirely on synthetic data, our model generalizes effectively to real-world cinematic content and achieves strong performance on synthetic, real-world, and audio-only CASS benchmarks. Code and demo are available at \url{https://cass-flowmatching.github.io}.
DualTSR: Unified Dual-Diffusion Transformer for Scene Text Image Super-Resolution
Mar 15, 2026Scene Text Image Super-Resolution (STISR) aims to restore high-resolution details in low-resolution text images, which is crucial for both human readability and machine recognition. Existing methods, however, often depend on external Optical Character Recognition (OCR) models for textual priors or rely on complex multi-component architectures that are difficult to train and reproduce. In this paper, we introduce DualTSR, a unified end-to-end framework that addresses both issues. DualTSR employs a single multimodal transformer backbone trained with a dual diffusion objective. It simultaneously models the continuous distribution of high-resolution images via Conditional Flow Matching and the discrete distribution of textual content via discrete diffusion. This shared design enables visual and textual information to interact at every layer, allowing the model to infer text priors internally instead of relying on an external OCR module. Compared with prior multi-branch diffusion systems, DualTSR offers a simpler end-to-end formulation with fewer hand-crafted components. Experiments on synthetic Chinese benchmarks and a curated real-world evaluation protocol show that DualTSR achieves strong perceptual quality and text fidelity.
A Hidden Semantic Bottleneck in Conditional Embeddings of Diffusion Transformers
Feb 25, 2026Diffusion Transformers have achieved state-of-the-art performance in class-conditional and multimodal generation, yet the structure of their learned conditional embeddings remains poorly understood. In this work, we present the first systematic study of these embeddings and uncover a notable redundancy: class-conditioned embeddings exhibit extreme angular similarity, exceeding 99\% on ImageNet-1K, while continuous-condition tasks such as pose-guided image generation and video-to-audio generation reach over 99.9\%. We further find that semantic information is concentrated in a small subset of dimensions, with head dimensions carrying the dominant signal and tail dimensions contributing minimally. By pruning low-magnitude dimensions--removing up to two-thirds of the embedding space--we show that generation quality and fidelity remain largely unaffected, and in some cases improve. These results reveal a semantic bottleneck in Transformer-based diffusion models, providing new insights into how semantics are encoded and suggesting opportunities for more efficient conditioning mechanisms.
LangPert: Detecting and Handling Task-level Perturbations for Robust Object Rearrangement
Apr 14, 2025Task execution for object rearrangement could be challenged by Task-Level Perturbations (TLP), i.e., unexpected object additions, removals, and displacements that can disrupt underlying visual policies and fundamentally compromise task feasibility and progress. To address these challenges, we present LangPert, a language-based framework designed to detect and mitigate TLP situations in tabletop rearrangement tasks. LangPert integrates a Visual Language Model (VLM) to comprehensively monitor policy's skill execution and environmental TLP, while leveraging the Hierarchical Chain-of-Thought (HCoT) reasoning mechanism to enhance the Large Language Model (LLM)'s contextual understanding and generate adaptive, corrective skill-execution plans. Our experimental results demonstrate that LangPert handles diverse TLP situations more effectively than baseline methods, achieving higher task completion rates, improved execution efficiency, and potential generalization to unseen scenarios.
The Dream Within Huang Long Cave: AI-Driven Interactive Narrative for Family Storytelling and Emotional Reflection
Apr 07, 2025



This paper introduces the art project The Dream Within Huang Long Cave, an AI-driven interactive and immersive narrative experience. The project offers new insights into AI technology, artistic practice, and psychoanalysis. Inspired by actual geographical landscapes and familial archetypes, the work combines psychoanalytic theory and computational technology, providing an artistic response to the concept of the non-existence of the Big Other. The narrative is driven by a combination of a large language model (LLM) and a realistic digital character, forming a virtual agent named YELL. Through dialogue and exploration within a cave automatic virtual environment (CAVE), the audience is invited to unravel the language puzzles presented by YELL and help him overcome his life challenges. YELL is a fictional embodiment of the Big Other, modeled after the artist's real father. Through a cross-temporal interaction with this digital father, the project seeks to deconstruct complex familial relationships. By demonstrating the non-existence of the Big Other, we aim to underscore the authenticity of interpersonal emotions, positioning art as a bridge for emotional connection and understanding within family dynamics.
Strategic priorities for transformative progress in advancing biology with proteomics and artificial intelligence
Feb 21, 2025

Artificial intelligence (AI) is transforming scientific research, including proteomics. Advances in mass spectrometry (MS)-based proteomics data quality, diversity, and scale, combined with groundbreaking AI techniques, are unlocking new challenges and opportunities in biological discovery. Here, we highlight key areas where AI is driving innovation, from data analysis to new biological insights. These include developing an AI-friendly ecosystem for proteomics data generation, sharing, and analysis; improving peptide and protein identification and quantification; characterizing protein-protein interactions and protein complexes; advancing spatial and perturbation proteomics; integrating multi-omics data; and ultimately enabling AI-empowered virtual cells.
Towards a Physics Engine to Simulate Robotic Laser Surgery: Finite Element Modeling of Thermal Laser-Tissue Interactions
Nov 21, 2024



This paper presents a computational model, based on the Finite Element Method (FEM), that simulates the thermal response of laser-irradiated tissue. This model addresses a gap in the current ecosystem of surgical robot simulators, which generally lack support for lasers and other energy-based end effectors. In the proposed model, the thermal dynamics of the tissue are calculated as the solution to a heat conduction problem with appropriate boundary conditions. The FEM formulation allows the model to capture complex phenomena, such as convection, which is crucial for creating realistic simulations. The accuracy of the model was verified via benchtop laser-tissue interaction experiments using agar tissue phantoms and ex-vivo chicken muscle. The results revealed an average root-mean-square error (RMSE) of less than 2 degrees Celsius across most experimental conditions.
Physics Informed Distillation for Diffusion Models
Nov 13, 2024



Diffusion models have recently emerged as a potent tool in generative modeling. However, their inherent iterative nature often results in sluggish image generation due to the requirement for multiple model evaluations. Recent progress has unveiled the intrinsic link between diffusion models and Probability Flow Ordinary Differential Equations (ODEs), thus enabling us to conceptualize diffusion models as ODE systems. Simultaneously, Physics Informed Neural Networks (PINNs) have substantiated their effectiveness in solving intricate differential equations through implicit modeling of their solutions. Building upon these foundational insights, we introduce Physics Informed Distillation (PID), which employs a student model to represent the solution of the ODE system corresponding to the teacher diffusion model, akin to the principles employed in PINNs. Through experiments on CIFAR 10 and ImageNet 64x64, we observe that PID achieves performance comparable to recent distillation methods. Notably, it demonstrates predictable trends concerning method-specific hyperparameters and eliminates the need for synthetic dataset generation during the distillation process. Both of which contribute to its easy-to-use nature as a distillation approach for Diffusion Models. Our code and pre-trained checkpoint are publicly available at: https://github.com/pantheon5100/pid_diffusion.git.
"Benefit Game: Alien Seaweed Swarms" -- Real-time Gamification of Digital Seaweed Ecology
Aug 30, 2024


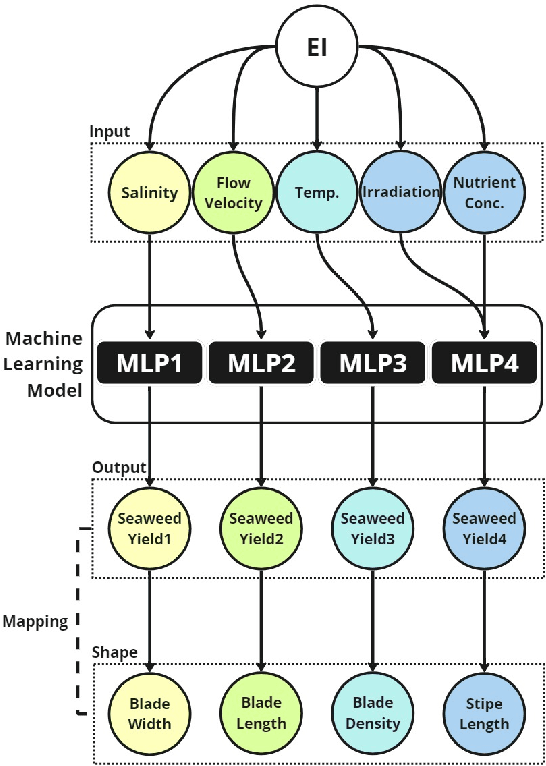
"Benefit Game: Alien Seaweed Swarms" combines artificial life art and interactive game with installation to explore the impact of human activity on fragile seaweed ecosystems. The project aims to promote ecological consciousness by creating a balance in digital seaweed ecologies. Inspired by the real species "Laminaria saccharina", the author employs Procedural Content Generation via Machine Learning technology to generate variations of virtual seaweeds and symbiotic fungi. The audience can explore the consequences of human activities through gameplay and observe the ecosystem's feedback on the benefits and risks of seaweed aquaculture. This Benefit Game offers dynamic and real-time responsive artificial seaweed ecosystems for an interactive experience that enhances ecological consciousness.