 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Retrieval-Augmented Classification for Dysarthria Severity Assessment
Jun 22, 2026Automatic dysarthria severity assessment is limited by the scarcity of labeled pathological speech data. To address this, we propose Cross-lingual Retrieval-Augmented Classification (CRAC), which leverages speech from a different language via an align-retrieve-fuse pipeline. Supervised contrastive learning first shapes a severity-focused embedding space, then a vector database is built from the opposite-language corpus. During both training and inference, the classifier retrieves top-k references from the aligned space and fuses them with the input via cross-attention. Evaluated on Korean post-stroke and Italian ALS dysarthria datasets under a speaker-independent three-class protocol, CRAC achieves balanced accuracies of 87.3% on Korean and 86.7% on Italian, improving over monolingual baselines by 8.4 and 20.0 percentage points, respectively.
Omni-Embed-Audio: Leveraging Multimodal LLMs for Robust Audio-Text Retrieval
Apr 20, 2026Audio-text retrieval systems based on Contrastive Language-Audio Pretraining (CLAP) achieve strong performance on traditional benchmarks; however, these benchmarks rely on caption-style queries that differ substantially from real-world search behavior, limiting their assessment of practical retrieval robustness. We present Omni-Embed-Audio (OEA), a retrieval-oriented encoder leveraging multimodal LLMs with native audio understanding. To systematically evaluate robustness beyond caption-style queries, we introduce User-Intent Queries (UIQs) - five formulations reflecting natural search behaviors: questions, commands, keyword tags, paraphrases, and exclusion-based negative queries. For negative queries, we develop a hard negative mining pipeline and propose discrimination metrics (HNSR, TFR) assessing models' ability to suppress acoustically similar distractors. Experiments on AudioCaps, Clotho, and MECAT show that OEA achieves comparable text-to-audio retrieval performance to state-of-the-art M2D-CLAP, while demonstrating clear advantages in two critical areas: (1) dominant text-to-text retrieval (+22% relative improvement), and (2) substantially superior hard negative discrimination (+4.3%p HNSR@10, +34.7% relative TFR@10), revealing that LLM backbones provide superior semantic understanding of complex queries.
CAF-Score: Calibrating CLAP with LALMs for Reference-free Audio Captioning Evaluation
Mar 20, 2026While Large Audio-Language Models (LALMs) have advanced audio captioning, robust evaluation remains difficult. Reference-based metrics are expensive and often fail to assess acoustic fidelity, while Contrastive Language-Audio Pretraining (CLAP)-based approaches frequently overlook syntactic errors and fine-grained details. We propose CAF-Score, a reference-free metric that calibrates CLAP's coarse-grained semantic alignment with the fine-grained comprehension and syntactic awareness of LALMs. By combining contrastive audio-text embeddings with LALM reasoning, CAF-Score effectively detects syntactic inconsistencies and subtle hallucinations. Experiments on the BRACE benchmark demonstrate that our approach achieves the highest correlation with human judgments, even outperforming reference-based baselines in challenging scenarios. These results highlight the efficacy of CAF-Score for reference-free audio captioning evaluation. Code and results are available at https://github.com/inseong00/CAF-Score.
Solar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
RILQ: Rank-Insensitive LoRA-based Quantization Error Compensation for Boosting 2-bit Large Language Model Accuracy
Dec 02, 2024Low-rank adaptation (LoRA) has become the dominant method for parameter-efficient LLM fine-tuning, with LoRA-based quantization error compensation (LQEC) emerging as a powerful tool for recovering accuracy in compressed LLMs. However, LQEC has underperformed in sub-4-bit scenarios, with no prior investigation into understanding this limitation. We propose RILQ (Rank-Insensitive LoRA-based Quantization Error Compensation) to understand fundamental limitation and boost 2-bit LLM accuracy. Based on rank analysis revealing model-wise activation discrepancy loss's rank-insensitive nature, RILQ employs this loss to adjust adapters cooperatively across layers, enabling robust error compensation with low-rank adapters. Evaluations on LLaMA-2 and LLaMA-3 demonstrate RILQ's consistent improvements in 2-bit quantized inference across various state-of-the-art quantizers and enhanced accuracy in task-specific fine-tuning. RILQ maintains computational efficiency comparable to existing LoRA methods, enabling adapter-merged weight-quantized LLM inference with significantly enhanced accuracy, making it a promising approach for boosting 2-bit LLM performance.
BI-MDRG: Bridging Image History in Multimodal Dialogue Response Generation
Aug 12, 2024
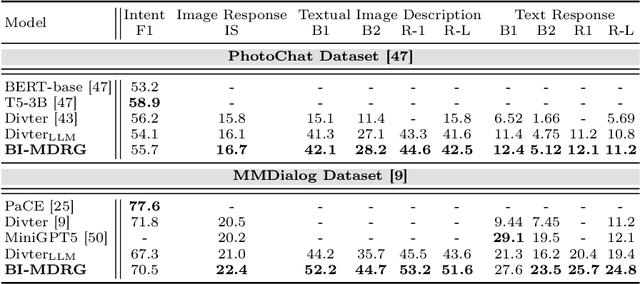


Multimodal Dialogue Response Generation (MDRG) is a recently proposed task where the model needs to generate responses in texts, images, or a blend of both based on the dialogue context. Due to the lack of a large-scale dataset specifically for this task and the benefits of leveraging powerful pre-trained models, previous work relies on the text modality as an intermediary step for both the image input and output of the model rather than adopting an end-to-end approach. However, this approach can overlook crucial information about the image, hindering 1) image-grounded text response and 2) consistency of objects in the image response. In this paper, we propose BI-MDRG that bridges the response generation path such that the image history information is utilized for enhanced relevance of text responses to the image content and the consistency of objects in sequential image responses. Through extensive experiments on the multimodal dialogue benchmark dataset, we show that BI-MDRG can effectively increase the quality of multimodal dialogue. Additionally, recognizing the gap in benchmark datasets for evaluating the image consistency in multimodal dialogue, we have created a curated set of 300 dialogues annotated to track object consistency across conversations.
Guidance-Based Prompt Data Augmentation in Specialized Domains for Named Entity Recognition
Jul 26, 2024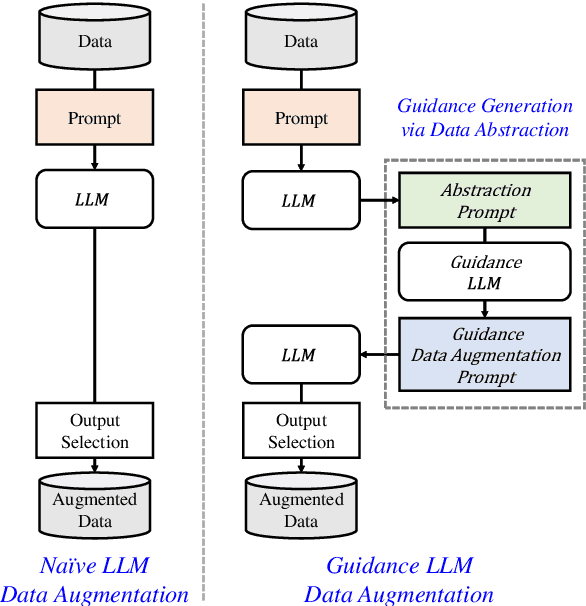
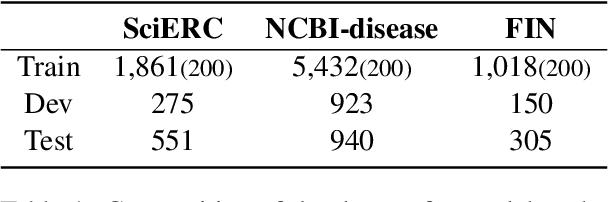

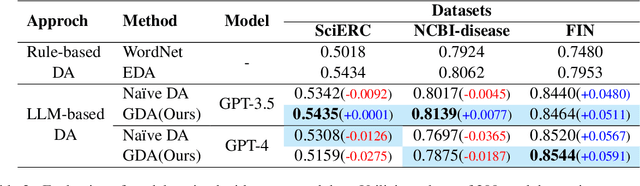
While the abundance of rich and vast datasets across numerous fields has facilitated the advancement of natural language processing, sectors in need of specialized data types continue to struggle with the challenge of finding quality data. Our study introduces a novel guidance data augmentation technique utilizing abstracted context and sentence structures to produce varied sentences while maintaining context-entity relationships, addressing data scarcity challenges. By fostering a closer relationship between context, sentence structure, and role of entities, our method enhances data augmentation's effectiveness. Consequently, by showcasing diversification in both entity-related vocabulary and overall sentence structure, and simultaneously improving the training performance of named entity recognition task.
Improving Conversational Abilities of Quantized Large Language Models via Direct Preference Alignment
Jul 03, 2024The rapid advancement of large language models (LLMs) has facilitated their transformation into conversational chatbots that can grasp contextual nuances and generate pertinent sentences, closely mirroring human values through advanced techniques such as instruction tuning and reinforcement learning from human feedback (RLHF). However, the computational efficiency required for LLMs, achieved through techniques like post-training quantization (PTQ), presents challenges such as token-flipping that can impair chatbot performance. In response, we propose a novel preference alignment approach, quantization-aware direct preference optimization (QDPO), that aligns quantized LLMs with their full-precision counterparts, improving conversational abilities. Evaluated on two instruction-tuned LLMs in various languages, QDPO demonstrated superior performance in improving conversational abilities compared to established PTQ and knowledge-distillation fine-tuning techniques, marking a significant step forward in the development of efficient and effective conversational LLMs.
Towards Fast Multilingual LLM Inference: Speculative Decoding and Specialized Drafters
Jun 24, 2024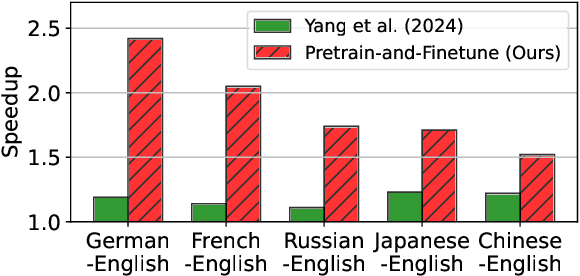



Large language models (LLMs) have revolutionized natural language processing and broadened their applicability across diverse commercial applications. However, the deployment of these models is constrained by high inference time in multilingual settings. To mitigate this challenge, this paper explores a training recipe of an assistant model in speculative decoding, which are leveraged to draft and-then its future tokens are verified by the target LLM. We show that language-specific draft models, optimized through a targeted pretrain-and-finetune strategy, substantially brings a speedup of inference time compared to the previous methods. We validate these models across various languages in inference time, out-of-domain speedup, and GPT-4o evaluation.
Evaluating Visual and Cultural Interpretation: The K-Viscuit Benchmark with Human-VLM Collaboration
Jun 24, 2024To create culturally inclusive vision-language models (VLMs), the foremost requirement is developing a test benchmark that can diagnose the models' ability to respond to questions reflecting cultural elements. This paper addresses the necessity for such benchmarks, noting that existing research has relied on human annotators' manual efforts, which impedes diversity and efficiency. We propose a semi-automated pipeline for constructing cultural VLM benchmarks to enhance diversity and efficiency. This pipeline leverages human-VLM collaboration, where VLMs generate questions based on guidelines, human-annotated examples, and image-wise relevant knowledge, which are then reviewed by native speakers for quality and cultural relevance. The effectiveness of our adaptable pipeline is demonstrated through a specific application: creating a dataset tailored to Korean culture, dubbed K-Viscuit. The resulting benchmark features two types of questions: Type 1 questions measure visual recognition abilities, while Type 2 assess fine-grained visual reasoning skills. This ensures a thorough diagnosis of VLM models across various aspects. Our evaluation using K-Viscuit revealed that open-source models notably lag behind proprietary models in understanding Korean culture, highlighting areas for improvement. We provided diverse analyses of VLM performance across different cultural aspects. Besides, we explored the potential of incorporating external knowledge retrieval to enhance the generation process, suggesting future directions for improving cultural interpretation ability of VLMs. Our dataset and code will be made publicly available.