 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLike Father, Like Son: Kinship-Aware Preference Mapping (KARMA) for Automatic Alignment in Large Language Models
Feb 26, 2025



Recent advancements in Large Language Model (LLM) alignment have sought to mitigate the cost of human annotations by leveraging pretrained models to generate preference data. However, existing methods often compare responses from models with substantially different capabilities, yielding superficial distinctions that fail to provide meaningful guidance on what constitutes a superior response. To address this limitation, we propose Kinship-Aware pReference MApping (KARMA), a novel framework that systematically pairs responses from models with comparable competencies. By constraining preference comparisons to outputs of similar complexity and quality, KARMA enhances the informativeness of preference data and improves the granularity of alignment signals. Empirical evaluations demonstrate that our kinship-aware approach leads to more consistent and interpretable alignment outcomes, ultimately facilitating a more principled and reliable pathway for aligning LLM behavior with human preferences.
Guidance-Based Prompt Data Augmentation in Specialized Domains for Named Entity Recognition
Jul 26, 2024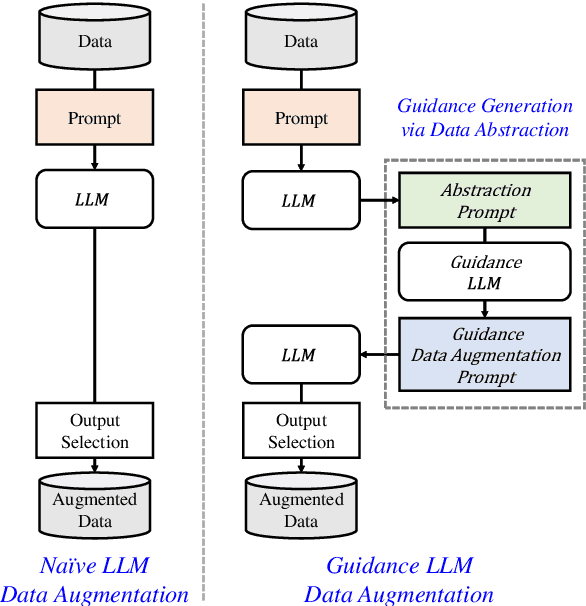
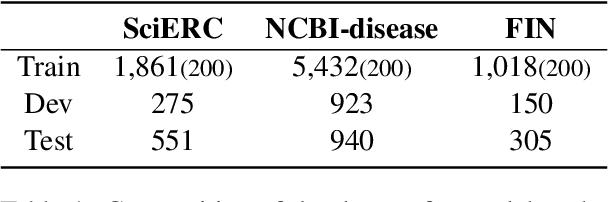

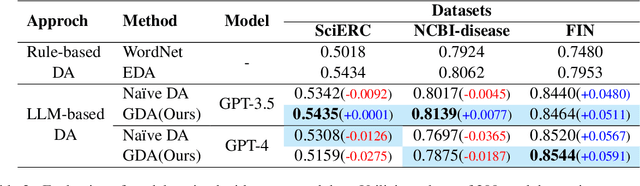
While the abundance of rich and vast datasets across numerous fields has facilitated the advancement of natural language processing, sectors in need of specialized data types continue to struggle with the challenge of finding quality data. Our study introduces a novel guidance data augmentation technique utilizing abstracted context and sentence structures to produce varied sentences while maintaining context-entity relationships, addressing data scarcity challenges. By fostering a closer relationship between context, sentence structure, and role of entities, our method enhances data augmentation's effectiveness. Consequently, by showcasing diversification in both entity-related vocabulary and overall sentence structure, and simultaneously improving the training performance of named entity recognition task.
Exploring Domain Robust Lightweight Reward Models based on Router Mechanism
Jul 24, 2024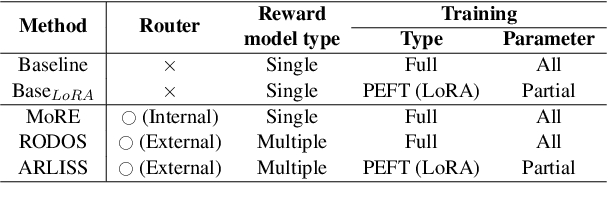
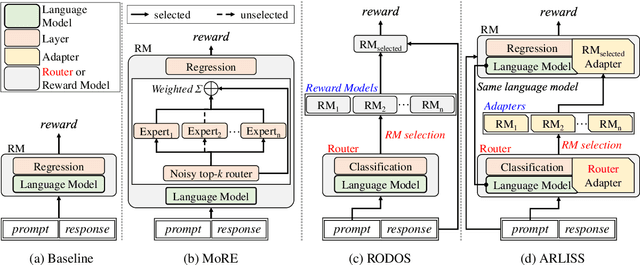
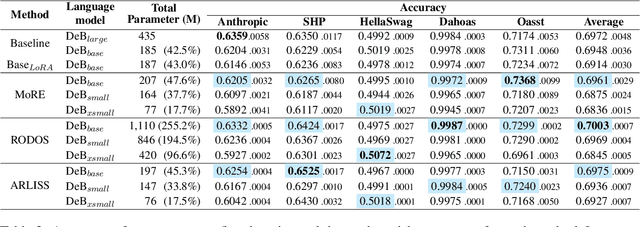

Recent advancements in large language models have heavily relied on the large reward model from reinforcement learning from human feedback for fine-tuning. However, the use of a single reward model across various domains may not always be optimal, often requiring retraining from scratch when new domain data is introduced. To address these challenges, we explore the utilization of small language models operating in a domain-specific manner based on router mechanisms. Our three approaches are: 1) utilize mixture of experts to form a single reward model by modularizing an internal router and experts, 2) employing external router to select the appropriate reward model from multiple domain-specific models, and 3) the framework reduces parameter size by loading reward models and router adapters onto a single small language model using adapters. Experimental validation underscores the effectiveness of our approach, demonstrating performance comparable to baseline methods while also reducing the total parameter size.