 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Domain Robust Lightweight Reward Models based on Router Mechanism
Jul 24, 2024
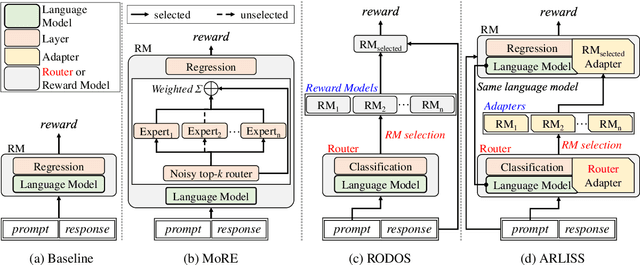
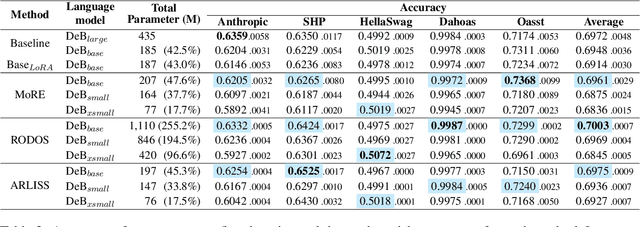

Recent advancements in large language models have heavily relied on the large reward model from reinforcement learning from human feedback for fine-tuning. However, the use of a single reward model across various domains may not always be optimal, often requiring retraining from scratch when new domain data is introduced. To address these challenges, we explore the utilization of small language models operating in a domain-specific manner based on router mechanisms. Our three approaches are: 1) utilize mixture of experts to form a single reward model by modularizing an internal router and experts, 2) employing external router to select the appropriate reward model from multiple domain-specific models, and 3) the framework reduces parameter size by loading reward models and router adapters onto a single small language model using adapters. Experimental validation underscores the effectiveness of our approach, demonstrating performance comparable to baseline methods while also reducing the total parameter size.