 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLED: A Benchmark for Evaluating Layout Error Detection in Document Analysis
Mar 18, 2026Recent advances in Large Language Models (LLMs) and Large Multimodal Models (LMMs) have improved Document Layout Analysis (DLA), yet structural errors such as region merging, splitting, and omission remain persistent. Conventional overlap-based metrics (e.g., IoU, mAP) fail to capture such logical inconsistencies. To overcome this limitation, we propose Layout Error Detection (LED), a benchmark that evaluates structural reasoning in DLA predictions beyond surface-level accuracy. LED defines eight standardized error types (Missing, Hallucination, Size Error, Split, Merge, Overlap, Duplicate, and Misclassification) and provides quantitative rules and injection algorithms for realistic error simulation. Using these definitions, we construct LED-Dataset and design three evaluation tasks: document-level error detection, document-level error-type classification, and element-level error-type classification. Experiments with state-of-the-art multimodal models show that LED enables fine-grained and interpretable assessment of structural understanding, revealing clear weaknesses across modalities and architectures. Overall, LED establishes a unified and explainable benchmark for diagnosing the structural robustness and reasoning capability of document understanding models.
LANGALIGN: Enhancing Non-English Language Models via Cross-Lingual Embedding Alignment
Mar 25, 2025While Large Language Models have gained attention, many service developers still rely on embedding-based models due to practical constraints. In such cases, the quality of fine-tuning data directly impacts performance, and English datasets are often used as seed data for training non-English models. In this study, we propose LANGALIGN, which enhances target language processing by aligning English embedding vectors with those of the target language at the interface between the language model and the task header. Experiments on Korean, Japanese, and Chinese demonstrate that LANGALIGN significantly improves performance across all three languages. Additionally, we show that LANGALIGN can be applied in reverse to convert target language data into a format that an English-based model can process.
Like Father, Like Son: Kinship-Aware Preference Mapping (KARMA) for Automatic Alignment in Large Language Models
Feb 26, 2025



Recent advancements in Large Language Model (LLM) alignment have sought to mitigate the cost of human annotations by leveraging pretrained models to generate preference data. However, existing methods often compare responses from models with substantially different capabilities, yielding superficial distinctions that fail to provide meaningful guidance on what constitutes a superior response. To address this limitation, we propose Kinship-Aware pReference MApping (KARMA), a novel framework that systematically pairs responses from models with comparable competencies. By constraining preference comparisons to outputs of similar complexity and quality, KARMA enhances the informativeness of preference data and improves the granularity of alignment signals. Empirical evaluations demonstrate that our kinship-aware approach leads to more consistent and interpretable alignment outcomes, ultimately facilitating a more principled and reliable pathway for aligning LLM behavior with human preferences.
Guidance-Based Prompt Data Augmentation in Specialized Domains for Named Entity Recognition
Jul 26, 2024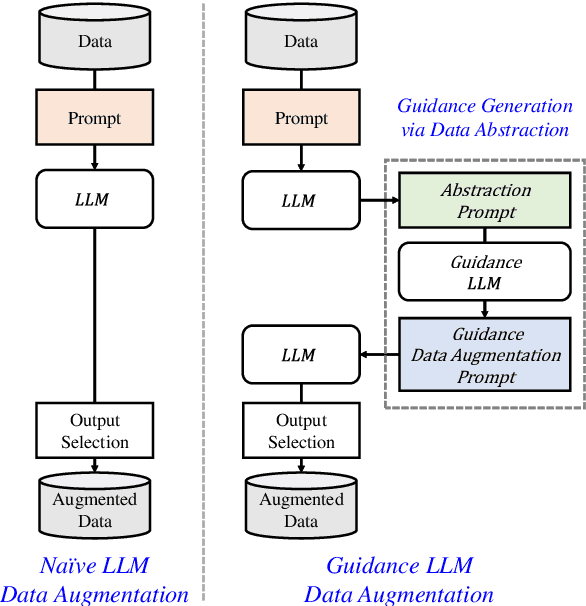
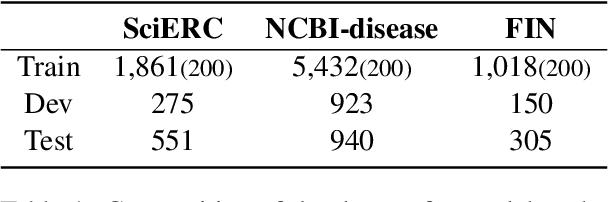

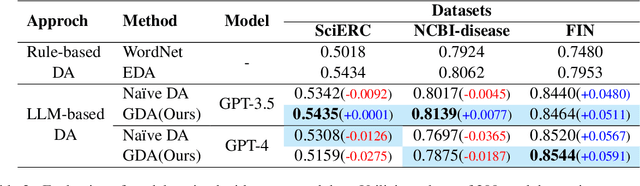
While the abundance of rich and vast datasets across numerous fields has facilitated the advancement of natural language processing, sectors in need of specialized data types continue to struggle with the challenge of finding quality data. Our study introduces a novel guidance data augmentation technique utilizing abstracted context and sentence structures to produce varied sentences while maintaining context-entity relationships, addressing data scarcity challenges. By fostering a closer relationship between context, sentence structure, and role of entities, our method enhances data augmentation's effectiveness. Consequently, by showcasing diversification in both entity-related vocabulary and overall sentence structure, and simultaneously improving the training performance of named entity recognition task.
Exploring Domain Robust Lightweight Reward Models based on Router Mechanism
Jul 24, 2024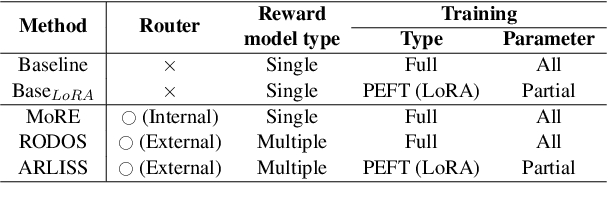
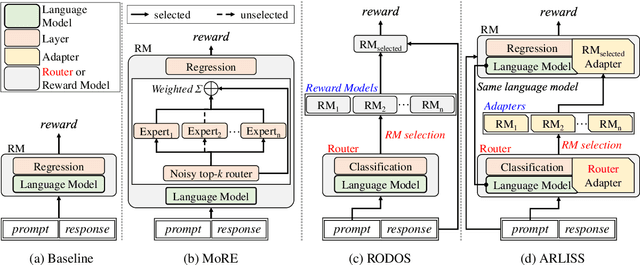
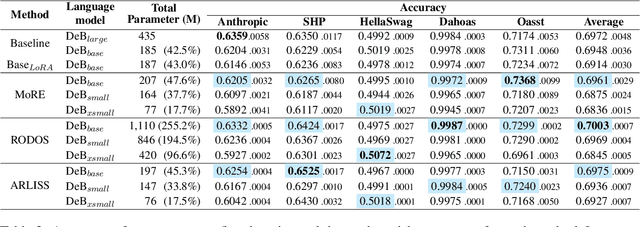

Recent advancements in large language models have heavily relied on the large reward model from reinforcement learning from human feedback for fine-tuning. However, the use of a single reward model across various domains may not always be optimal, often requiring retraining from scratch when new domain data is introduced. To address these challenges, we explore the utilization of small language models operating in a domain-specific manner based on router mechanisms. Our three approaches are: 1) utilize mixture of experts to form a single reward model by modularizing an internal router and experts, 2) employing external router to select the appropriate reward model from multiple domain-specific models, and 3) the framework reduces parameter size by loading reward models and router adapters onto a single small language model using adapters. Experimental validation underscores the effectiveness of our approach, demonstrating performance comparable to baseline methods while also reducing the total parameter size.
Does Incomplete Syntax Influence Korean Language Model? Focusing on Word Order and Case Markers
Jul 12, 2024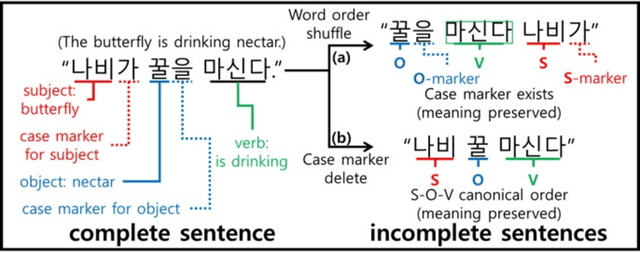
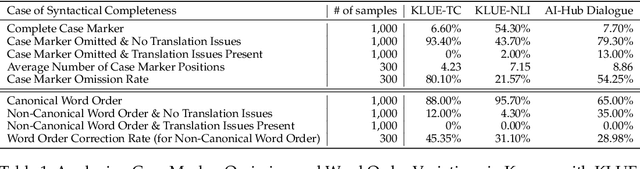

Syntactic elements, such as word order and case markers, are fundamental in natural language processing. Recent studies show that syntactic information boosts language model performance and offers clues for people to understand their learning mechanisms. Unlike languages with a fixed word order such as English, Korean allows for varied word sequences, despite its canonical structure, due to case markers that indicate the functions of sentence components. This study explores whether Korean language models can accurately capture this flexibility. We note that incomplete word orders and omitted case markers frequently appear in ordinary Korean communication. To investigate this further, we introduce the Syntactically Incomplete Korean (SIKO) dataset. Through SIKO, we assessed Korean language models' flexibility with incomplete syntax and confirmed the dataset's training value. Results indicate these models reflect Korean's inherent flexibility, accurately handling incomplete inputs. Moreover, fine-tuning with SIKO enhances the ability to handle common incomplete Korean syntactic forms. The dataset's simple construction process, coupled with significant performance enhancements, solidifies its standing as an effective data augmentation technique.
Employing Layerwised Unsupervised Learning to Lessen Data and Loss Requirements in Forward-Forward Algorithms
Apr 23, 2024



Recent deep learning models such as ChatGPT utilizing the back-propagation algorithm have exhibited remarkable performance. However, the disparity between the biological brain processes and the back-propagation algorithm has been noted. The Forward-Forward algorithm, which trains deep learning models solely through the forward pass, has emerged to address this. Although the Forward-Forward algorithm cannot replace back-propagation due to limitations such as having to use special input and loss functions, it has the potential to be useful in special situations where back-propagation is difficult to use. To work around this limitation and verify usability, we propose an Unsupervised Forward-Forward algorithm. Using an unsupervised learning model enables training with usual loss functions and inputs without restriction. Through this approach, we lead to stable learning and enable versatile utilization across various datasets and tasks. From a usability perspective, given the characteristics of the Forward-Forward algorithm and the advantages of the proposed method, we anticipate its practical application even in scenarios such as federated learning, where deep learning layers need to be trained separately in physically distributed environments.
SUMBT+LaRL: End-to-end Neural Task-oriented Dialog System with Reinforcement Learning
Oct 06, 2020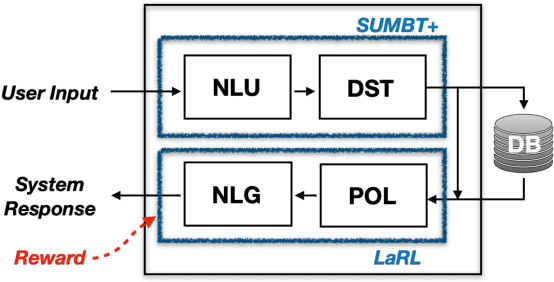
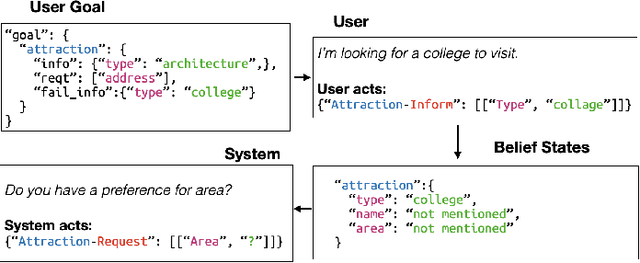
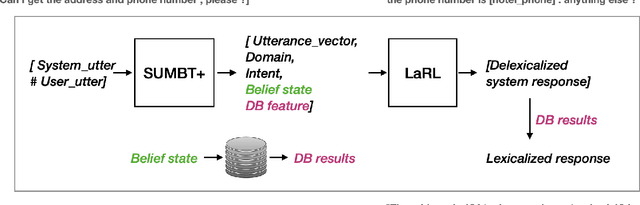
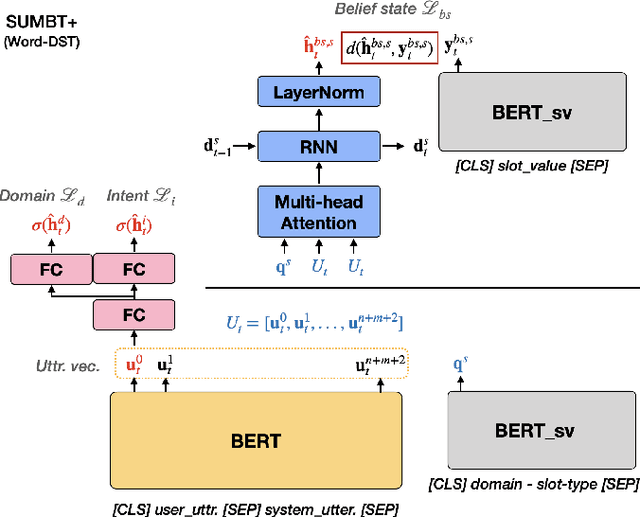
The recent advent of neural approaches for developing each dialog component in task-oriented dialog systems has remarkably improved, yet optimizing the overall system performance remains a challenge. In this paper, we propose an end-to-end trainable neural dialog system with reinforcement learning, named SUMBT+LaRL. The SUMBT+ estimates user-acts as well as dialog belief states, and the LaRL models latent system action spaces and generates responses given the estimated contexts. We experimentally demonstrate that the training framework in which the SUMBT+ and LaRL are separately pretrained and then the entire system is fine-tuned significantly increases dialog success rates. We propose new success criteria for reinforcement learning to the end-to-end dialog system as well as provide experimental analysis on a different result aspect depending on the success criteria and evaluation methods. Consequently, our model achieved the new state-of-the-art success rate of 85.4% on corpus-based evaluation, and a comparable success rate of 81.40% on simulator-based evaluation provided by the DSTC8 challenge.