 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLANGALIGN: Enhancing Non-English Language Models via Cross-Lingual Embedding Alignment
Mar 25, 2025While Large Language Models have gained attention, many service developers still rely on embedding-based models due to practical constraints. In such cases, the quality of fine-tuning data directly impacts performance, and English datasets are often used as seed data for training non-English models. In this study, we propose LANGALIGN, which enhances target language processing by aligning English embedding vectors with those of the target language at the interface between the language model and the task header. Experiments on Korean, Japanese, and Chinese demonstrate that LANGALIGN significantly improves performance across all three languages. Additionally, we show that LANGALIGN can be applied in reverse to convert target language data into a format that an English-based model can process.
Thanos: Enhancing Conversational Agents with Skill-of-Mind-Infused Large Language Model
Nov 07, 2024To increase social bonding with interlocutors, humans naturally acquire the ability to respond appropriately in a given situation by considering which conversational skill is most suitable for the response - a process we call skill-of-mind. For large language model (LLM)-based conversational agents, planning appropriate conversational skills, as humans do, is challenging due to the complexity of social dialogue, especially in interactive scenarios. To address this, we propose a skill-of-mind-annotated conversation dataset, named Multifaceted Skill-of-Mind, which includes multi-turn and multifaceted conversational skills across various interactive scenarios (e.g., long-term, counseling, task-oriented), grounded in diverse social contexts (e.g., demographics, persona, rules of thumb). This dataset consists of roughly 100K conversations. Using this dataset, we introduce a new family of skill-of-mind-infused LLMs, named Thanos, with model sizes of 1B, 3B, and 8B parameters. With extensive experiments, these models successfully demonstrate the skill-of-mind process and exhibit strong generalizability in inferring multifaceted skills across a variety of domains. Moreover, we show that Thanos significantly enhances the quality of responses generated by LLM-based conversational agents and promotes prosocial behavior in human evaluations.
Intriguing Properties of Large Language and Vision Models
Oct 07, 2024Recently, large language and vision models (LLVMs) have received significant attention and development efforts due to their remarkable generalization performance across a wide range of tasks requiring perception and cognitive abilities. A key factor behind their success is their simple architecture, which consists of a vision encoder, a projector, and a large language model (LLM). Despite their achievements in advanced reasoning tasks, their performance on fundamental perception-related tasks (e.g., MMVP) remains surprisingly low. This discrepancy raises the question of how LLVMs truly perceive images and exploit the advantages of the vision encoder. To address this, we systematically investigate this question regarding several aspects: permutation invariance, robustness, math reasoning, alignment preserving and importance, by evaluating the most common LLVM's families (i.e., LLaVA) across 10 evaluation benchmarks. Our extensive experiments reveal several intriguing properties of current LLVMs: (1) they internally process the image in a global manner, even when the order of visual patch sequences is randomly permuted; (2) they are sometimes able to solve math problems without fully perceiving detailed numerical information; (3) the cross-modal alignment is overfitted to complex reasoning tasks, thereby, causing them to lose some of the original perceptual capabilities of their vision encoder; (4) the representation space in the lower layers (<25%) plays a crucial role in determining performance and enhancing visual understanding. Lastly, based on the above observations, we suggest potential future directions for building better LLVMs and constructing more challenging evaluation benchmarks.
Does Incomplete Syntax Influence Korean Language Model? Focusing on Word Order and Case Markers
Jul 12, 2024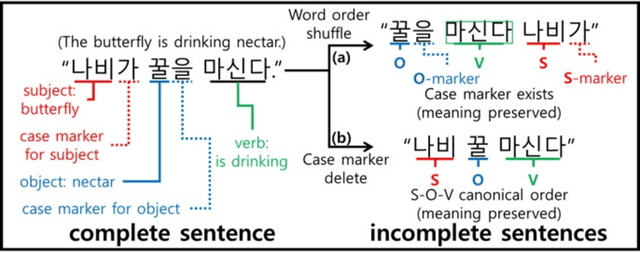
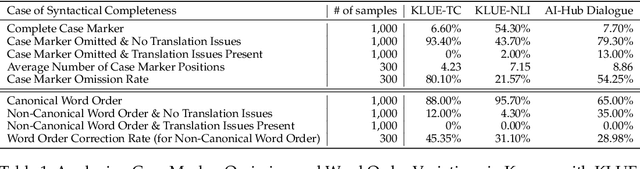

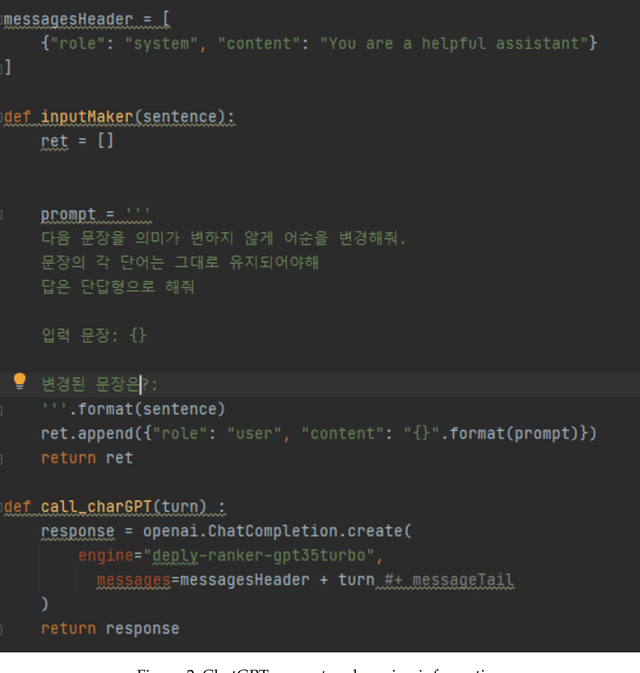
Syntactic elements, such as word order and case markers, are fundamental in natural language processing. Recent studies show that syntactic information boosts language model performance and offers clues for people to understand their learning mechanisms. Unlike languages with a fixed word order such as English, Korean allows for varied word sequences, despite its canonical structure, due to case markers that indicate the functions of sentence components. This study explores whether Korean language models can accurately capture this flexibility. We note that incomplete word orders and omitted case markers frequently appear in ordinary Korean communication. To investigate this further, we introduce the Syntactically Incomplete Korean (SIKO) dataset. Through SIKO, we assessed Korean language models' flexibility with incomplete syntax and confirmed the dataset's training value. Results indicate these models reflect Korean's inherent flexibility, accurately handling incomplete inputs. Moreover, fine-tuning with SIKO enhances the ability to handle common incomplete Korean syntactic forms. The dataset's simple construction process, coupled with significant performance enhancements, solidifies its standing as an effective data augmentation technique.
Stark: Social Long-Term Multi-Modal Conversation with Persona Commonsense Knowledge
Jul 04, 2024



Humans share a wide variety of images related to their personal experiences within conversations via instant messaging tools. However, existing works focus on (1) image-sharing behavior in singular sessions, leading to limited long-term social interaction, and (2) a lack of personalized image-sharing behavior. In this work, we introduce Stark, a large-scale long-term multi-modal conversation dataset that covers a wide range of social personas in a multi-modality format, time intervals, and images. To construct Stark automatically, we propose a novel multi-modal contextualization framework, Mcu, that generates long-term multi-modal dialogue distilled from ChatGPT and our proposed Plan-and-Execute image aligner. Using our Stark, we train a multi-modal conversation model, Ultron 7B, which demonstrates impressive visual imagination ability. Furthermore, we demonstrate the effectiveness of our dataset in human evaluation. We make our source code and dataset publicly available.
Large Language Models can Share Images, Too!
Oct 23, 2023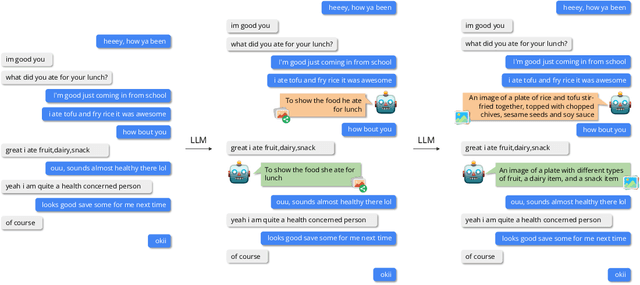
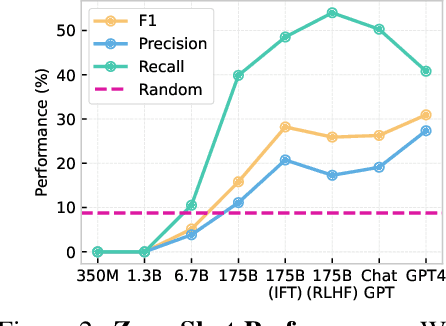
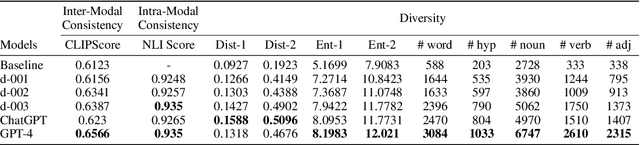
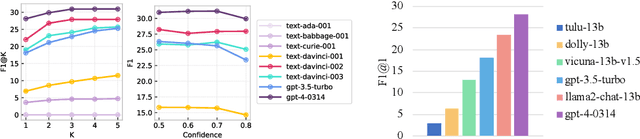
This paper explores the image-sharing capability of Large Language Models (LLMs), such as InstructGPT, ChatGPT, and GPT-4, in a zero-shot setting, without the help of visual foundation models. Inspired by the two-stage process of image-sharing in human dialogues, we propose a two-stage framework that allows LLMs to predict potential image-sharing turns and generate related image descriptions using our effective restriction-based prompt template. With extensive experiments, we unlock the \textit{image-sharing} capability of LLMs in zero-shot prompting, with GPT-4 achieving the best performance. Additionally, we uncover the emergent \textit{image-sharing} ability in zero-shot prompting, demonstrating the effectiveness of restriction-based prompts in both stages of our framework. Based on this framework, we augment the PhotoChat dataset with images generated by Stable Diffusion at predicted turns, namely PhotoChat++. To our knowledge, this is the first study to assess the image-sharing ability of LLMs in a zero-shot setting without visual foundation models. The source code and the dataset will be released after publication.
DialogCC: Large-Scale Multi-Modal Dialogue Dataset
Dec 08, 2022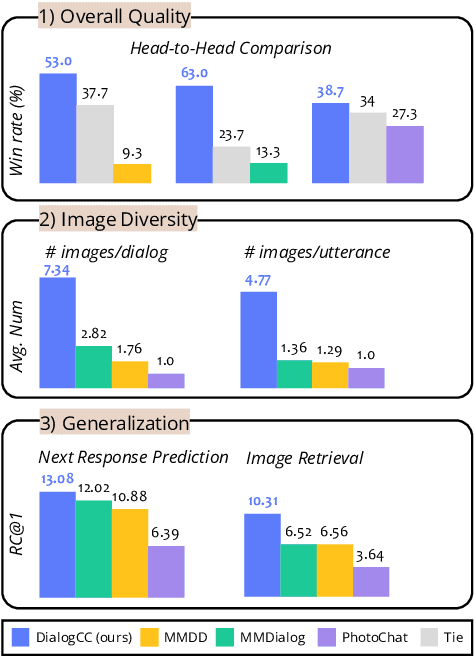



As sharing images in an instant message is a crucial factor, there has been active research on learning a image-text multi-modal dialogue model. However, training a well-generalized multi-modal dialogue model is challenging because existing multi-modal dialogue datasets contain a small number of data, limited topics, and a restricted variety of images per dialogue. In this paper, we present a multi-modal dialogue dataset creation pipeline that involves matching large-scale images to dialogues based on CLIP similarity. Using this automatic pipeline, we propose a large-scale multi-modal dialogue dataset, DialogCC, which covers diverse real-world topics and various images per dialogue. With extensive experiments, we demonstrate that training a multi-modal dialogue model with our dataset can improve generalization performance. Additionally, existing models trained with our dataset achieve state-of-the-art performance on image and text retrieval tasks. The source code and the dataset will be released after publication.
Empirical Study of Drone Sound Detection in Real-Life Environment with Deep Neural Networks
Jan 20, 2017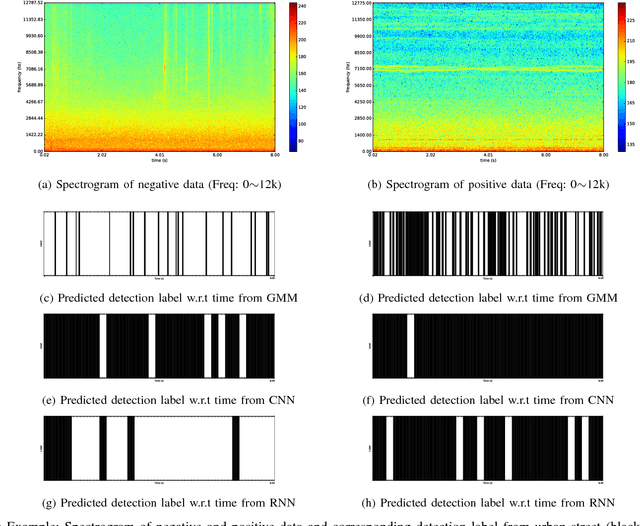
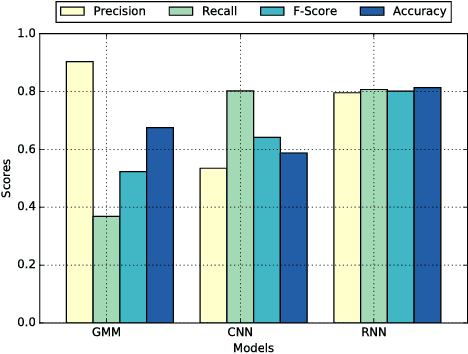
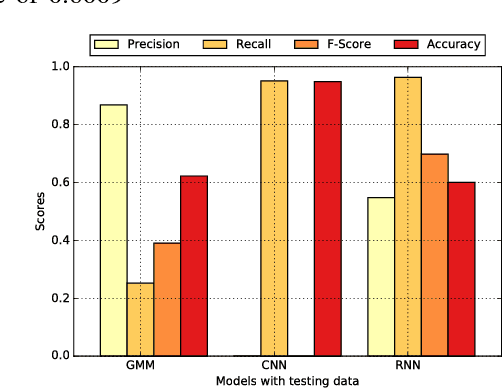

This work aims to investigate the use of deep neural network to detect commercial hobby drones in real-life environments by analyzing their sound data. The purpose of work is to contribute to a system for detecting drones used for malicious purposes, such as for terrorism. Specifically, we present a method capable of detecting the presence of commercial hobby drones as a binary classification problem based on sound event detection. We recorded the sound produced by a few popular commercial hobby drones, and then augmented this data with diverse environmental sound data to remedy the scarcity of drone sound data in diverse environments. We investigated the effectiveness of state-of-the-art event sound classification methods, i.e., a Gaussian Mixture Model (GMM), Convolutional Neural Network (CNN), and Recurrent Neural Network (RNN), for drone sound detection. Our empirical results, which were obtained with a testing dataset collected on an urban street, confirmed the effectiveness of these models for operating in a real environment. In summary, our RNN models showed the best detection performance with an F-Score of 0.8009 with 240 ms of input audio with a short processing time, indicating their applicability to real-time detection systems.