 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models can Share Images, Too!
Paper and Code
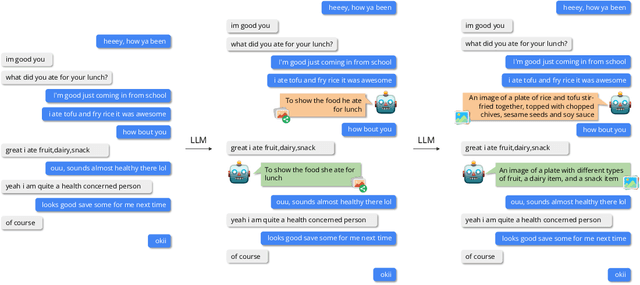
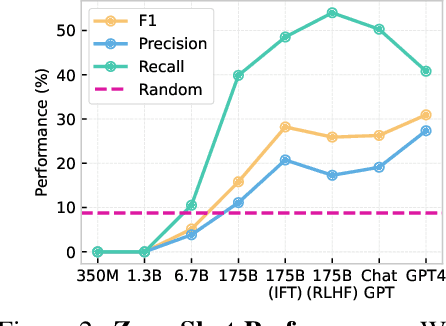
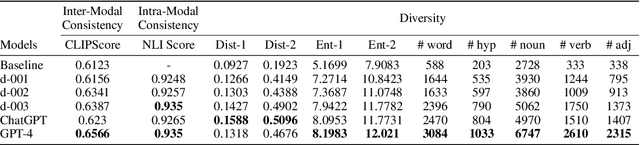
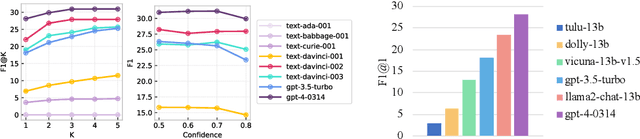
This paper explores the image-sharing capability of Large Language Models (LLMs), such as InstructGPT, ChatGPT, and GPT-4, in a zero-shot setting, without the help of visual foundation models. Inspired by the two-stage process of image-sharing in human dialogues, we propose a two-stage framework that allows LLMs to predict potential image-sharing turns and generate related image descriptions using our effective restriction-based prompt template. With extensive experiments, we unlock the \textit{image-sharing} capability of LLMs in zero-shot prompting, with GPT-4 achieving the best performance. Additionally, we uncover the emergent \textit{image-sharing} ability in zero-shot prompting, demonstrating the effectiveness of restriction-based prompts in both stages of our framework. Based on this framework, we augment the PhotoChat dataset with images generated by Stable Diffusion at predicted turns, namely PhotoChat++. To our knowledge, this is the first study to assess the image-sharing ability of LLMs in a zero-shot setting without visual foundation models. The source code and the dataset will be released after publication.