 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Speech Emotion Recognition through Segmental Average Pooling of Self-Supervised Learning Features
Oct 16, 2024



Speech Emotion Recognition (SER) analyzes human emotions expressed through speech. Self-supervised learning (SSL) offers a promising approach to SER by learning meaningful representations from a large amount of unlabeled audio data. However, existing SSL-based methods rely on Global Average Pooling (GAP) to represent audio signals, treating speech and non-speech segments equally. This can lead to dilution of informative speech features by irrelevant non-speech information. To address this, the paper proposes Segmental Average Pooling (SAP), which selectively focuses on informative speech segments while ignoring non-speech segments. By applying both GAP and SAP to SSL features, our approach utilizes overall speech signal information from GAP and specific information from SAP, leading to improved SER performance. Experiments show state-of-the-art results on the IEMOCAP for English and superior performance on KEMDy19 for Korean datasets in both unweighted and weighted accuracies.
Stark: Social Long-Term Multi-Modal Conversation with Persona Commonsense Knowledge
Jul 04, 2024



Humans share a wide variety of images related to their personal experiences within conversations via instant messaging tools. However, existing works focus on (1) image-sharing behavior in singular sessions, leading to limited long-term social interaction, and (2) a lack of personalized image-sharing behavior. In this work, we introduce Stark, a large-scale long-term multi-modal conversation dataset that covers a wide range of social personas in a multi-modality format, time intervals, and images. To construct Stark automatically, we propose a novel multi-modal contextualization framework, Mcu, that generates long-term multi-modal dialogue distilled from ChatGPT and our proposed Plan-and-Execute image aligner. Using our Stark, we train a multi-modal conversation model, Ultron 7B, which demonstrates impressive visual imagination ability. Furthermore, we demonstrate the effectiveness of our dataset in human evaluation. We make our source code and dataset publicly available.
Large Language Models can Share Images, Too!
Oct 23, 2023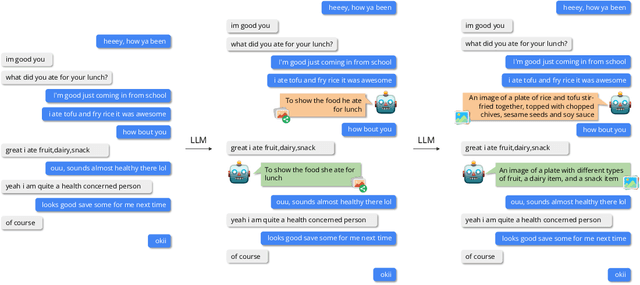
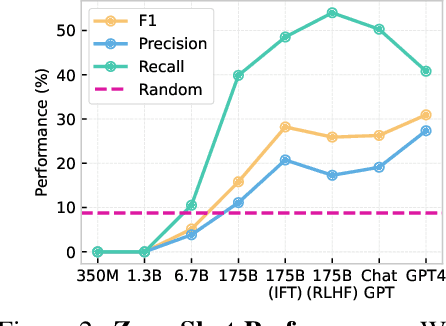
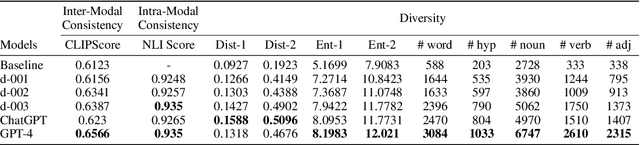
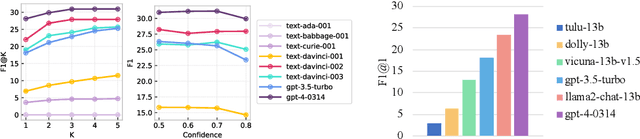
This paper explores the image-sharing capability of Large Language Models (LLMs), such as InstructGPT, ChatGPT, and GPT-4, in a zero-shot setting, without the help of visual foundation models. Inspired by the two-stage process of image-sharing in human dialogues, we propose a two-stage framework that allows LLMs to predict potential image-sharing turns and generate related image descriptions using our effective restriction-based prompt template. With extensive experiments, we unlock the \textit{image-sharing} capability of LLMs in zero-shot prompting, with GPT-4 achieving the best performance. Additionally, we uncover the emergent \textit{image-sharing} ability in zero-shot prompting, demonstrating the effectiveness of restriction-based prompts in both stages of our framework. Based on this framework, we augment the PhotoChat dataset with images generated by Stable Diffusion at predicted turns, namely PhotoChat++. To our knowledge, this is the first study to assess the image-sharing ability of LLMs in a zero-shot setting without visual foundation models. The source code and the dataset will be released after publication.