 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Speech Emotion Recognition through Segmental Average Pooling of Self-Supervised Learning Features
Oct 16, 2024



Speech Emotion Recognition (SER) analyzes human emotions expressed through speech. Self-supervised learning (SSL) offers a promising approach to SER by learning meaningful representations from a large amount of unlabeled audio data. However, existing SSL-based methods rely on Global Average Pooling (GAP) to represent audio signals, treating speech and non-speech segments equally. This can lead to dilution of informative speech features by irrelevant non-speech information. To address this, the paper proposes Segmental Average Pooling (SAP), which selectively focuses on informative speech segments while ignoring non-speech segments. By applying both GAP and SAP to SSL features, our approach utilizes overall speech signal information from GAP and specific information from SAP, leading to improved SER performance. Experiments show state-of-the-art results on the IEMOCAP for English and superior performance on KEMDy19 for Korean datasets in both unweighted and weighted accuracies.
Audio Source Separation Using a Deep Autoencoder
Dec 22, 2014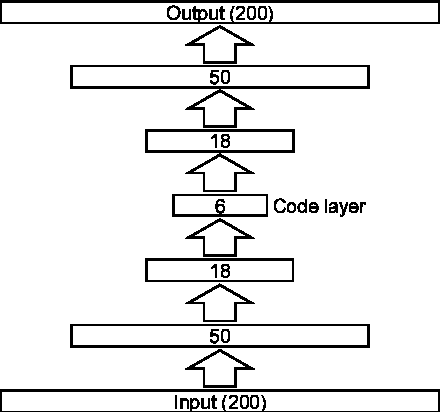
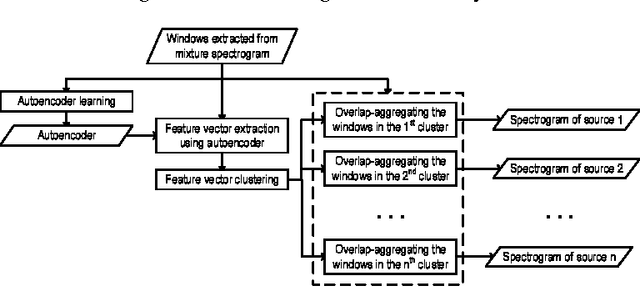

This paper proposes a novel framework for unsupervised audio source separation using a deep autoencoder. The characteristics of unknown source signals mixed in the mixed input is automatically by properly configured autoencoders implemented by a network with many layers, and separated by clustering the coefficient vectors in the code layer. By investigating the weight vectors to the final target, representation layer, the primitive components of the audio signals in the frequency domain are observed. By clustering the activation coefficients in the code layer, the previously unknown source signals are segregated. The original source sounds are then separated and reconstructed by using code vectors which belong to different clusters. The restored sounds are not perfect but yield promising results for the possibility in the success of many practical applications.