 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Source Separation Using a Deep Autoencoder
Paper and Code
Dec 22, 2014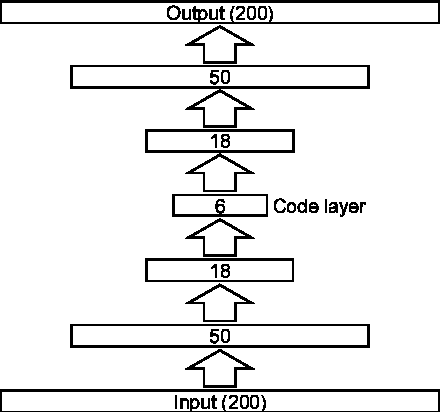
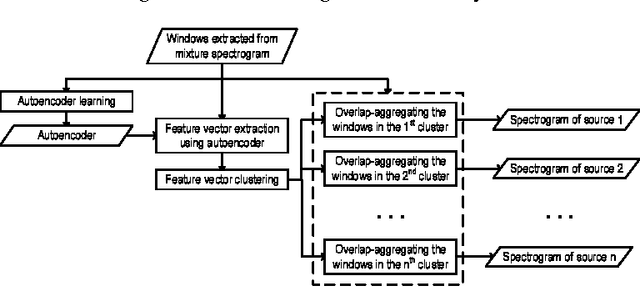

This paper proposes a novel framework for unsupervised audio source separation using a deep autoencoder. The characteristics of unknown source signals mixed in the mixed input is automatically by properly configured autoencoders implemented by a network with many layers, and separated by clustering the coefficient vectors in the code layer. By investigating the weight vectors to the final target, representation layer, the primitive components of the audio signals in the frequency domain are observed. By clustering the activation coefficients in the code layer, the previously unknown source signals are segregated. The original source sounds are then separated and reconstructed by using code vectors which belong to different clusters. The restored sounds are not perfect but yield promising results for the possibility in the success of many practical applications.