 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Spoke When in Multi-Conversation: Target Speaker Tagging Task and Benchmark
Jun 12, 2026We present target speaker tagging (TST), a task that integrates speaker diarization, verification, and identification into a unified workflow for multi-speaker conversations. Given long recordings and pre-enrolled speakers, TST detects and labels speech segments of known speakers while rejecting unknown ones. Despite its practical importance, research has been limited by the absence of suitable evaluation resources. To address this, we introduce TST-Bench, a large-scale synthetic benchmark with over 150 enrolled speakers, 300 sessions of 20-60 minutes, and reference annotations with global speaker labels. We define an evaluation protocol encompassing diarization and full-pipeline scenarios. Experiments on both real and synthetic data show that TST poses challenges not captured by conventional benchmarks, and that dedicated system design yields significant gains over naive integration of existing solutions. The benchmark dataset and evaluation protocols are publicly released.
Intriguing Properties of Large Language and Vision Models
Oct 07, 2024Recently, large language and vision models (LLVMs) have received significant attention and development efforts due to their remarkable generalization performance across a wide range of tasks requiring perception and cognitive abilities. A key factor behind their success is their simple architecture, which consists of a vision encoder, a projector, and a large language model (LLM). Despite their achievements in advanced reasoning tasks, their performance on fundamental perception-related tasks (e.g., MMVP) remains surprisingly low. This discrepancy raises the question of how LLVMs truly perceive images and exploit the advantages of the vision encoder. To address this, we systematically investigate this question regarding several aspects: permutation invariance, robustness, math reasoning, alignment preserving and importance, by evaluating the most common LLVM's families (i.e., LLaVA) across 10 evaluation benchmarks. Our extensive experiments reveal several intriguing properties of current LLVMs: (1) they internally process the image in a global manner, even when the order of visual patch sequences is randomly permuted; (2) they are sometimes able to solve math problems without fully perceiving detailed numerical information; (3) the cross-modal alignment is overfitted to complex reasoning tasks, thereby, causing them to lose some of the original perceptual capabilities of their vision encoder; (4) the representation space in the lower layers (<25%) plays a crucial role in determining performance and enhancing visual understanding. Lastly, based on the above observations, we suggest potential future directions for building better LLVMs and constructing more challenging evaluation benchmarks.
DialogCC: Large-Scale Multi-Modal Dialogue Dataset
Dec 08, 2022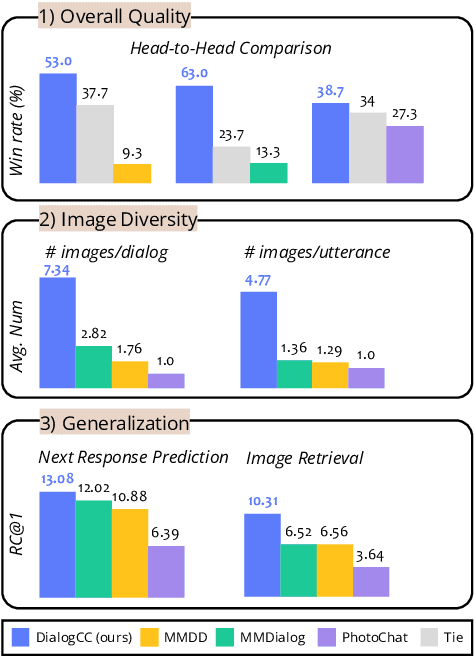



As sharing images in an instant message is a crucial factor, there has been active research on learning a image-text multi-modal dialogue model. However, training a well-generalized multi-modal dialogue model is challenging because existing multi-modal dialogue datasets contain a small number of data, limited topics, and a restricted variety of images per dialogue. In this paper, we present a multi-modal dialogue dataset creation pipeline that involves matching large-scale images to dialogues based on CLIP similarity. Using this automatic pipeline, we propose a large-scale multi-modal dialogue dataset, DialogCC, which covers diverse real-world topics and various images per dialogue. With extensive experiments, we demonstrate that training a multi-modal dialogue model with our dataset can improve generalization performance. Additionally, existing models trained with our dataset achieve state-of-the-art performance on image and text retrieval tasks. The source code and the dataset will be released after publication.
Group Generalized Mean Pooling for Vision Transformer
Dec 08, 2022



Vision Transformer (ViT) extracts the final representation from either class token or an average of all patch tokens, following the architecture of Transformer in Natural Language Processing (NLP) or Convolutional Neural Networks (CNNs) in computer vision. However, studies for the best way of aggregating the patch tokens are still limited to average pooling, while widely-used pooling strategies, such as max and GeM pooling, can be considered. Despite their effectiveness, the existing pooling strategies do not consider the architecture of ViT and the channel-wise difference in the activation maps, aggregating the crucial and trivial channels with the same importance. In this paper, we present Group Generalized Mean (GGeM) pooling as a simple yet powerful pooling strategy for ViT. GGeM divides the channels into groups and computes GeM pooling with a shared pooling parameter per group. As ViT groups the channels via a multi-head attention mechanism, grouping the channels by GGeM leads to lower head-wise dependence while amplifying important channels on the activation maps. Exploiting GGeM shows 0.1%p to 0.7%p performance boosts compared to the baselines and achieves state-of-the-art performance for ViT-Base and ViT-Large models in ImageNet-1K classification task. Moreover, GGeM outperforms the existing pooling strategies on image retrieval and multi-modal representation learning tasks, demonstrating the superiority of GGeM for a variety of tasks. GGeM is a simple algorithm in that only a few lines of code are necessary for implementation.
Back from the future: bidirectional CTC decoding using future information in speech recognition
Oct 07, 2021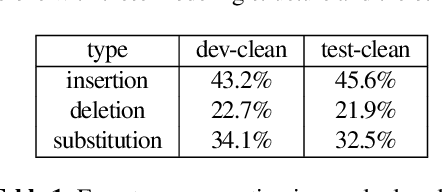

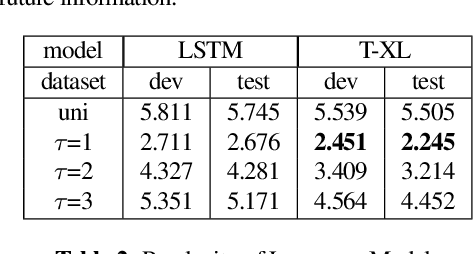
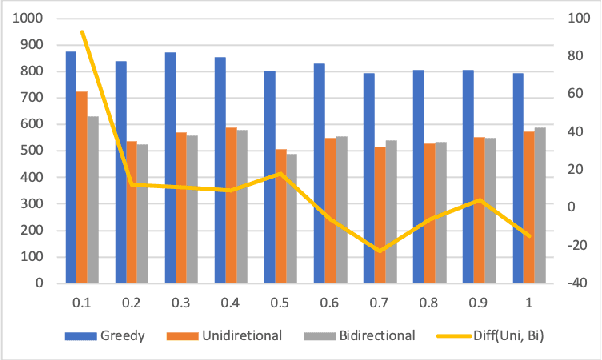
In this paper, we propose a simple but effective method to decode the output of Connectionist Temporal Classifier (CTC) model using a bi-directional neural language model. The bidirectional language model uses the future as well as the past information in order to predict the next output in the sequence. The proposed method based on bi-directional beam search takes advantage of the CTC greedy decoding output to represent the noisy future information. Experiments on the Librispeechdataset demonstrate the superiority of our proposed method compared to baselines using unidirectional decoding. In particular, the boost inaccuracy is most apparent at the start of a sequence which is the most erroneous part for existing systems based on unidirectional decoding.
Learning with Memory-based Virtual Classes for Deep Metric Learning
Mar 31, 2021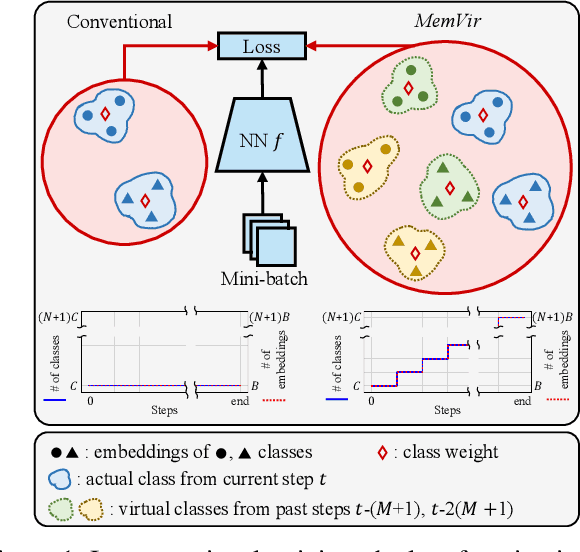
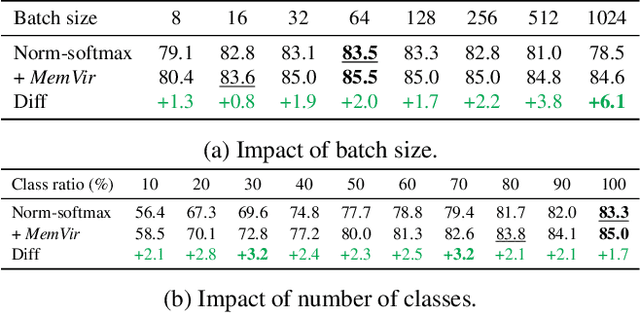
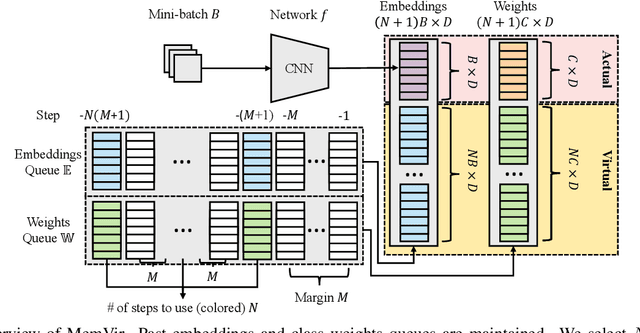

The core of deep metric learning (DML) involves learning visual similarities in high-dimensional embedding space. One of the main challenges is to generalize from seen classes of training data to unseen classes of test data. Recent works have focused on exploiting past embeddings to increase the number of instances for the seen classes. Such methods achieve performance improvement via augmentation, while the strong focus on seen classes still remains. This can be undesirable for DML, where training and test data exhibit entirely different classes. In this work, we present a novel training strategy for DML called MemVir. Unlike previous works, MemVir memorizes both embedding features and class weights to utilize them as additional virtual classes. The exploitation of virtual classes not only utilizes augmented information for training but also alleviates a strong focus on seen classes for better generalization. Moreover, we embed the idea of curriculum learning by slowly adding virtual classes for a gradual increase in learning difficulty, which improves the learning stability as well as the final performance. MemVir can be easily applied to many existing loss functions without any modification. Extensive experimental results on famous benchmarks demonstrate the superiority of MemVir over state-of-the-art competitors. Code of MemVir will be publicly available.
Proxy Synthesis: Learning with Synthetic Classes for Deep Metric Learning
Mar 29, 2021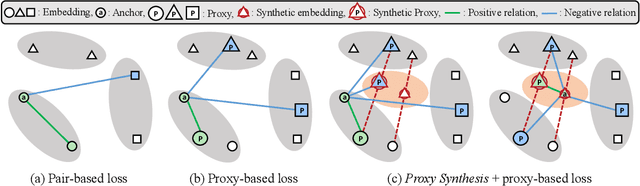
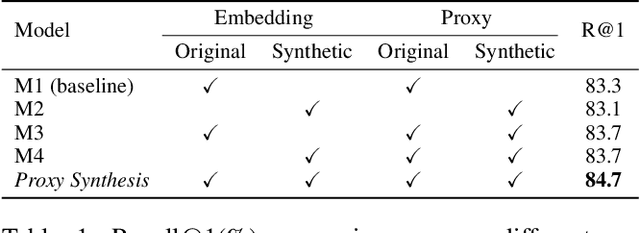
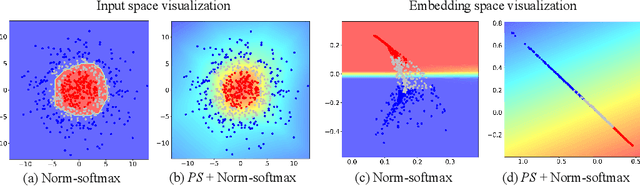
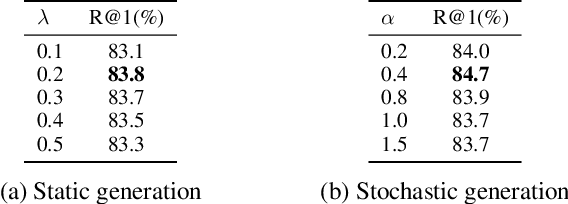
One of the main purposes of deep metric learning is to construct an embedding space that has well-generalized embeddings on both seen (training) classes and unseen (test) classes. Most existing works have tried to achieve this using different types of metric objectives and hard sample mining strategies with given training data. However, learning with only the training data can be overfitted to the seen classes, leading to the lack of generalization capability on unseen classes. To address this problem, we propose a simple regularizer called Proxy Synthesis that exploits synthetic classes for stronger generalization in deep metric learning. The proposed method generates synthetic embeddings and proxies that work as synthetic classes, and they mimic unseen classes when computing proxy-based losses. Proxy Synthesis derives an embedding space considering class relations and smooth decision boundaries for robustness on unseen classes. Our method is applicable to any proxy-based losses, including softmax and its variants. Extensive experiments on four famous benchmarks in image retrieval tasks demonstrate that Proxy Synthesis significantly boosts the performance of proxy-based losses and achieves state-of-the-art performance.
Audio Source Separation Using a Deep Autoencoder
Dec 22, 2014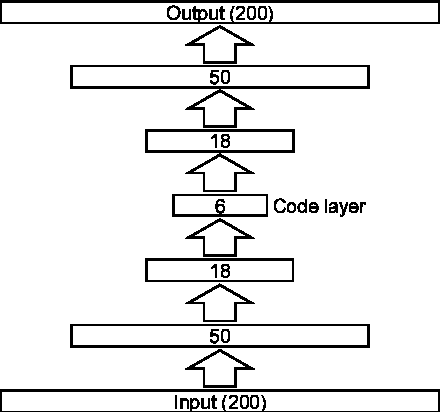
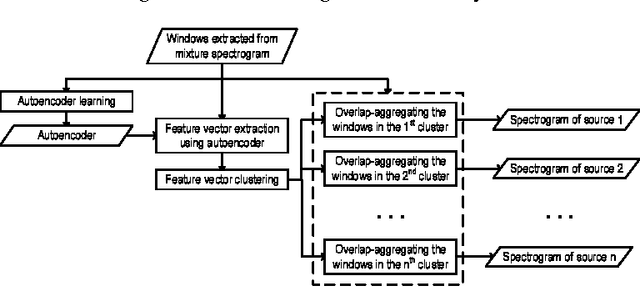
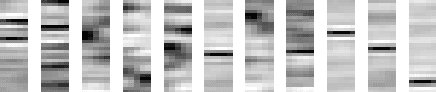

This paper proposes a novel framework for unsupervised audio source separation using a deep autoencoder. The characteristics of unknown source signals mixed in the mixed input is automatically by properly configured autoencoders implemented by a network with many layers, and separated by clustering the coefficient vectors in the code layer. By investigating the weight vectors to the final target, representation layer, the primitive components of the audio signals in the frequency domain are observed. By clustering the activation coefficients in the code layer, the previously unknown source signals are segregated. The original source sounds are then separated and reconstructed by using code vectors which belong to different clusters. The restored sounds are not perfect but yield promising results for the possibility in the success of many practical applications.