 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Memory-based Virtual Classes for Deep Metric Learning
Paper and Code
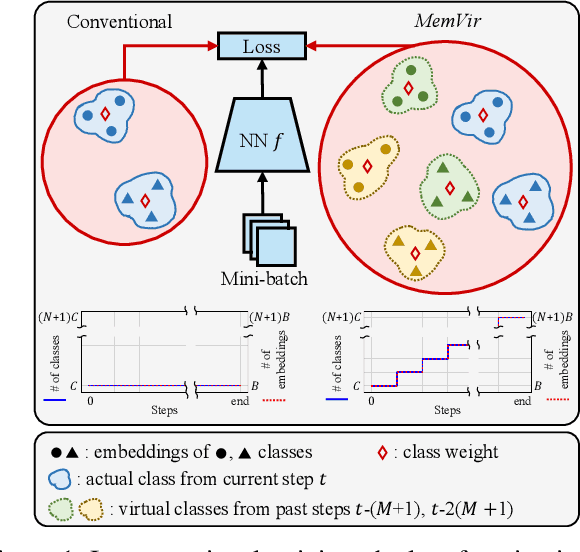
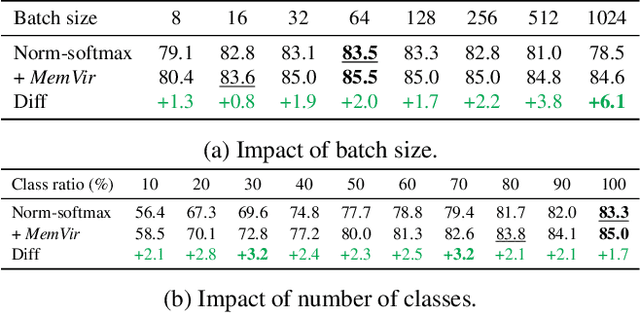
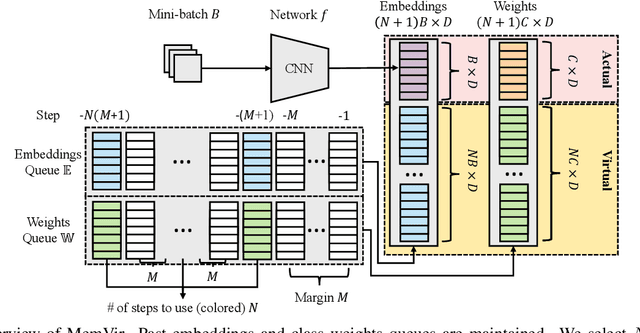

The core of deep metric learning (DML) involves learning visual similarities in high-dimensional embedding space. One of the main challenges is to generalize from seen classes of training data to unseen classes of test data. Recent works have focused on exploiting past embeddings to increase the number of instances for the seen classes. Such methods achieve performance improvement via augmentation, while the strong focus on seen classes still remains. This can be undesirable for DML, where training and test data exhibit entirely different classes. In this work, we present a novel training strategy for DML called MemVir. Unlike previous works, MemVir memorizes both embedding features and class weights to utilize them as additional virtual classes. The exploitation of virtual classes not only utilizes augmented information for training but also alleviates a strong focus on seen classes for better generalization. Moreover, we embed the idea of curriculum learning by slowly adding virtual classes for a gradual increase in learning difficulty, which improves the learning stability as well as the final performance. MemVir can be easily applied to many existing loss functions without any modification. Extensive experimental results on famous benchmarks demonstrate the superiority of MemVir over state-of-the-art competitors. Code of MemVir will be publicly available.