 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Fast Weights with Next-Sequence Prediction
Feb 18, 2026Fast weight architectures offer a promising alternative to attention-based transformers for long-context modeling by maintaining constant memory overhead regardless of context length. However, their potential is limited by the next-token prediction (NTP) training paradigm. NTP optimizes single-token predictions and ignores semantic coherence across multiple tokens following a prefix. Consequently, fast weight models, which dynamically update their parameters to store contextual information, learn suboptimal representations that fail to capture long-range dependencies. We introduce REFINE (Reinforced Fast weIghts with Next sEquence prediction), a reinforcement learning framework that trains fast weight models under the next-sequence prediction (NSP) objective. REFINE selects informative token positions based on prediction entropy, generates multi-token rollouts, assigns self-supervised sequence-level rewards, and optimizes the model with group relative policy optimization (GRPO). REFINE is applicable throughout the training lifecycle of pre-trained language models: mid-training, post-training, and test-time training. Our experiments on LaCT-760M and DeltaNet-1.3B demonstrate that REFINE consistently outperforms supervised fine-tuning with NTP across needle-in-a-haystack retrieval, long-context question answering, and diverse tasks in LongBench. REFINE provides an effective and versatile framework for improving long-context modeling in fast weight architectures.
Seeing What You Say: Expressive Image Generation from Speech
Nov 05, 2025



This paper proposes VoxStudio, the first unified and end-to-end speech-to-image model that generates expressive images directly from spoken descriptions by jointly aligning linguistic and paralinguistic information. At its core is a speech information bottleneck (SIB) module, which compresses raw speech into compact semantic tokens, preserving prosody and emotional nuance. By operating directly on these tokens, VoxStudio eliminates the need for an additional speech-to-text system, which often ignores the hidden details beyond text, e.g., tone or emotion. We also release VoxEmoset, a large-scale paired emotional speech-image dataset built via an advanced TTS engine to affordably generate richly expressive utterances. Comprehensive experiments on the SpokenCOCO, Flickr8kAudio, and VoxEmoset benchmarks demonstrate the feasibility of our method and highlight key challenges, including emotional consistency and linguistic ambiguity, paving the way for future research.
Emergence of Text Readability in Vision Language Models
Jun 24, 2025We investigate how the ability to recognize textual content within images emerges during the training of Vision-Language Models (VLMs). Our analysis reveals a critical phenomenon: the ability to read textual information in a given image \textbf{(text readability)} emerges abruptly after substantial training iterations, in contrast to semantic content understanding which develops gradually from the early stages of training. This delayed emergence may reflect how contrastive learning tends to initially prioritize general semantic understanding, with text-specific symbolic processing developing later. Interestingly, the ability to match images with rendered text develops even slower, indicating a deeper need for semantic integration. These findings highlight the need for tailored training strategies to accelerate robust text comprehension in VLMs, laying the groundwork for future research on optimizing multimodal learning.
Multiplicity is an Inevitable and Inherent Challenge in Multimodal Learning
May 26, 2025Multimodal learning has seen remarkable progress, particularly with the emergence of large-scale pre-training across various modalities. However, most current approaches are built on the assumption of a deterministic, one-to-one alignment between modalities. This oversimplifies real-world multimodal relationships, where their nature is inherently many-to-many. This phenomenon, named multiplicity, is not a side-effect of noise or annotation error, but an inevitable outcome of semantic abstraction, representational asymmetry, and task-dependent ambiguity in multimodal tasks. This position paper argues that multiplicity is a fundamental bottleneck that manifests across all stages of the multimodal learning pipeline: from data construction to training and evaluation. This paper examines the causes and consequences of multiplicity, and highlights how multiplicity introduces training uncertainty, unreliable evaluation, and low dataset quality. This position calls for new research directions on multimodal learning: novel multiplicity-aware learning frameworks and dataset construction protocols considering multiplicity.
LongProLIP: A Probabilistic Vision-Language Model with Long Context Text
Mar 11, 2025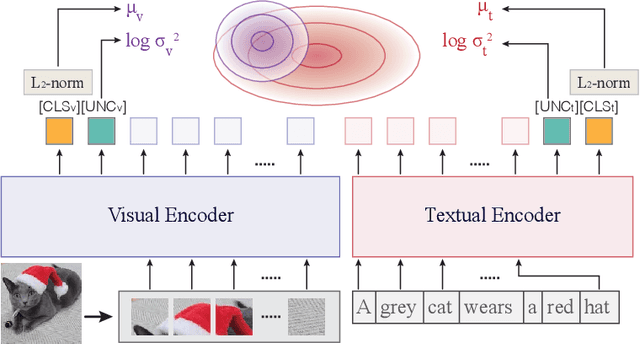
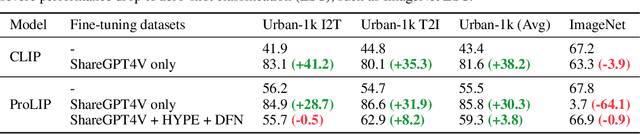


Recently, Probabilistic Language-Image Pre-Training (ProLIP) has been proposed to tackle the multiplicity issue of vision-language (VL) tasks. Despite their success in probabilistic representation learning at a scale, the ProLIP models cannot handle long context texts longer than 64 context length, which limits their ability to capture rich contextual information from longer text sequences. To address this issue, this paper proposes a fine-tuning strategy for ProLIP to accept longer texts, e.g., 256 text tokens. Experimental results on Urban-1k and the DataComp evaluation suite show that the proposed LongProLIP recipe can improve understanding of long contexts while minimizing the negative effect of fine-tuning. We also observe a trade-off between the long context understanding (measured by Urban-1k) and general zero-shot capability (measured by ImageNet or the average of 38 zero-shot evaluation datasets by DataComp).
DNNs May Determine Major Properties of Their Outputs Early, with Timing Possibly Driven by Bias
Feb 12, 2025This paper argues that deep neural networks (DNNs) mostly determine their outputs during the early stages of inference, where biases inherent in the model play a crucial role in shaping this process. We draw a parallel between this phenomenon and human decision-making, which often relies on fast, intuitive heuristics. Using diffusion models (DMs) as a case study, we demonstrate that DNNs often make early-stage decision-making influenced by the type and extent of bias in their design and training. Our findings offer a new perspective on bias mitigation, efficient inference, and the interpretation of machine learning systems. By identifying the temporal dynamics of decision-making in DNNs, this paper aims to inspire further discussion and research within the machine learning community.
Probabilistic Language-Image Pre-Training
Oct 24, 2024

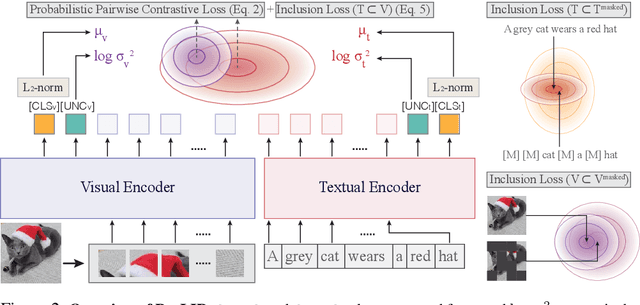

Vision-language models (VLMs) embed aligned image-text pairs into a joint space but often rely on deterministic embeddings, assuming a one-to-one correspondence between images and texts. This oversimplifies real-world relationships, which are inherently many-to-many, with multiple captions describing a single image and vice versa. We introduce Probabilistic Language-Image Pre-training (ProLIP), the first probabilistic VLM pre-trained on a billion-scale image-text dataset using only probabilistic objectives, achieving a strong zero-shot capability (e.g., 74.6% ImageNet zero-shot accuracy with ViT-B/16). ProLIP efficiently estimates uncertainty by an "uncertainty token" without extra parameters. We also introduce a novel inclusion loss that enforces distributional inclusion relationships between image-text pairs and between original and masked inputs. Experiments demonstrate that, by leveraging uncertainty estimates, ProLIP benefits downstream tasks and aligns with intuitive notions of uncertainty, e.g., shorter texts being more uncertain and more general inputs including specific ones. Utilizing text uncertainties, we further improve ImageNet accuracy from 74.6% to 75.8% (under a few-shot setting), supporting the practical advantages of our probabilistic approach. The code is available at https://github.com/naver-ai/prolip
Read, Watch and Scream! Sound Generation from Text and Video
Jul 08, 2024
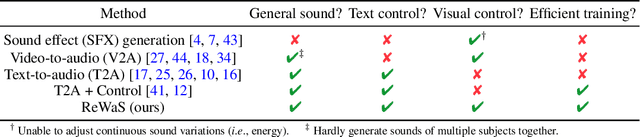


Multimodal generative models have shown impressive advances with the help of powerful diffusion models. Despite the progress, generating sound solely from text poses challenges in ensuring comprehensive scene depiction and temporal alignment. Meanwhile, video-to-sound generation limits the flexibility to prioritize sound synthesis for specific objects within the scene. To tackle these challenges, we propose a novel video-and-text-to-sound generation method, called ReWaS, where video serves as a conditional control for a text-to-audio generation model. Our method estimates the structural information of audio (namely, energy) from the video while receiving key content cues from a user prompt. We employ a well-performing text-to-sound model to consolidate the video control, which is much more efficient for training multimodal diffusion models with massive triplet-paired (audio-video-text) data. In addition, by separating the generative components of audio, it becomes a more flexible system that allows users to freely adjust the energy, surrounding environment, and primary sound source according to their preferences. Experimental results demonstrate that our method shows superiority in terms of quality, controllability, and training efficiency. Our demo is available at https://naver-ai.github.io/rewas
Reducing Task Discrepancy of Text Encoders for Zero-Shot Composed Image Retrieval
Jun 13, 2024Composed Image Retrieval (CIR) aims to retrieve a target image based on a reference image and conditioning text, enabling controllable searches. Due to the expensive dataset construction cost for CIR triplets, a zero-shot (ZS) CIR setting has been actively studied to eliminate the need for human-collected triplet datasets. The mainstream of ZS-CIR employs an efficient projection module that projects a CLIP image embedding to the CLIP text token embedding space, while fixing the CLIP encoders. Using the projected image embedding, these methods generate image-text composed features by using the pre-trained text encoder. However, their CLIP image and text encoders suffer from the task discrepancy between the pre-training task (text $\leftrightarrow$ image) and the target CIR task (image + text $\leftrightarrow$ image). Conceptually, we need expensive triplet samples to reduce the discrepancy, but we use cheap text triplets instead and update the text encoder. To that end, we introduce the Reducing Task Discrepancy of text encoders for Composed Image Retrieval (RTD), a plug-and-play training scheme for the text encoder that enhances its capability using a novel target-anchored text contrastive learning. We also propose two additional techniques to improve the proposed learning scheme: a hard negatives-based refined batch sampling strategy and a sophisticated concatenation scheme. Integrating RTD into the state-of-the-art projection-based ZS-CIR methods significantly improves performance across various datasets and backbones, demonstrating its efficiency and generalizability.
HYPE: Hyperbolic Entailment Filtering for Underspecified Images and Texts
Apr 26, 2024In an era where the volume of data drives the effectiveness of self-supervised learning, the specificity and clarity of data semantics play a crucial role in model training. Addressing this, we introduce HYPerbolic Entailment filtering (HYPE), a novel methodology designed to meticulously extract modality-wise meaningful and well-aligned data from extensive, noisy image-text pair datasets. Our approach leverages hyperbolic embeddings and the concept of entailment cones to evaluate and filter out samples with meaningless or underspecified semantics, focusing on enhancing the specificity of each data sample. HYPE not only demonstrates a significant improvement in filtering efficiency but also sets a new state-of-the-art in the DataComp benchmark when combined with existing filtering techniques. This breakthrough showcases the potential of HYPE to refine the data selection process, thereby contributing to the development of more accurate and efficient self-supervised learning models. Additionally, the image specificity $\epsilon_{i}$ can be independently applied to induce an image-only dataset from an image-text or image-only data pool for training image-only self-supervised models and showed superior performance when compared to the dataset induced by CLIP score.