 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Natural Image Autoencoders Compactly Tokenize fMRI Volumes for Long-Range Dynamics Modeling?
Apr 04, 2026Modeling long-range spatiotemporal dynamics in functional Magnetic Resonance Imaging (fMRI) remains a key challenge due to the high dimensionality of the four-dimensional signals. Prior voxel-based models, although demonstrating excellent performance and interpretation capabilities, are constrained by prohibitive memory demands and thus can only capture limited temporal windows. To address this, we propose TABLeT (Two-dimensionally Autoencoded Brain Latent Transformer), a novel approach that tokenizes fMRI volumes using a pre-trained 2D natural image autoencoder. Each 3D fMRI volume is compressed into a compact set of continuous tokens, enabling long-sequence modeling with a simple Transformer encoder with limited VRAM. Across large-scale benchmarks including the UK-Biobank (UKB), Human Connectome Project (HCP), and ADHD-200 datasets, TABLeT outperforms existing models in multiple tasks, while demonstrating substantial gains in computational and memory efficiency over the state-of-the-art voxel-based method given the same input. Furthermore, we develop a self-supervised masked token modeling approach to pre-train TABLeT, which improves the model's performance for various downstream tasks. Our findings suggest a promising approach for scalable and interpretable spatiotemporal modeling of brain activity. Our code is available at https://github.com/beotborry/TABLeT.
PopResume: Causal Fairness Evaluation of LLM/VLM Resume Screeners with Population-Representative Dataset
Mar 24, 2026We present PopResume, a population-representative resume dataset for causal fairness auditing of LLM- and VLM-based resume screening systems. Unlike existing benchmarks that rely on manually injected demographic information and outcome-level disparities, PopResume is grounded in population statistics and preserves natural attribute relationships, enabling path-specific effect (PSE)-based fairness evaluation. We decompose the effect of a protected attribute on resume scores into two paths: the business necessity path, mediated by job-relevant qualifications, and the redlining path, mediated by demographic proxies. This distinction allows auditors to separate legally permissible from impermissible sources of disparity. Evaluating four LLMs and four VLMs on PopResume's 60.8K resumes across five occupations, we identify five representative discrimination patterns that aggregate metrics fail to capture. Our results demonstrate that PSE-based evaluation reveals fairness issues masked by outcome-level measures, underscoring the need for causally-grounded auditing frameworks in AI-assisted hiring.
Action-Sufficient Goal Representations
Jan 30, 2026Hierarchical policies in offline goal-conditioned reinforcement learning (GCRL) addresses long-horizon tasks by decomposing control into high-level subgoal planning and low-level action execution. A critical design choice in such architectures is the goal representation-the compressed encoding of goals that serves as the interface between these levels. Existing approaches commonly derive goal representations while learning value functions, implicitly assuming that preserving information sufficient for value estimation is adequate for optimal control. We show that this assumption can fail, even when the value estimation is exact, as such representations may collapse goal states that need to be differentiated for action learning. To address this, we introduce an information-theoretic framework that defines action sufficiency, a condition on goal representations necessary for optimal action selection. We prove that value sufficiency does not imply action sufficiency and empirically verify that the latter is more strongly associated with control success in a discrete environment. We further demonstrate that standard log-loss training of low-level policies naturally induces action-sufficient representations. Our experimental results a popular benchmark demonstrate that our actor-derived representations consistently outperform representations learned via value estimation.
PRISP: Privacy-Safe Few-Shot Personalization via Lightweight Adaptation
Jan 10, 2026Large language model (LLM) personalization aims to adapt general-purpose models to individual users. Most existing methods, however, are developed under data-rich and resource-abundant settings, often incurring privacy risks. In contrast, realistic personalization typically occurs after deployment under (i) extremely limited user data, (ii) constrained computational resources, and (iii) strict privacy requirements. We propose PRISP, a lightweight and privacy-safe personalization framework tailored to these constraints. PRISP leverages a Text-to-LoRA hypernetwork to generate task-aware LoRA parameters from task descriptions, and enables efficient user personalization by optimizing a small subset of task-aware LoRA parameters together with minimal additional modules using few-shot user data. Experiments on a few-shot variant of the LaMP benchmark demonstrate that PRISP achieves strong overall performance compared to prior approaches, while reducing computational overhead and eliminating privacy risks.
SP-Guard: Selective Prompt-adaptive Guidance for Safe Text-to-Image Generation
Nov 14, 2025
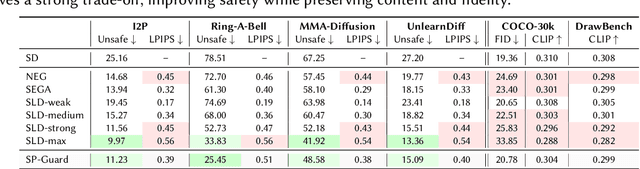
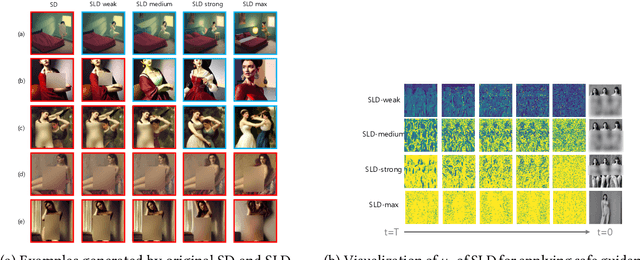
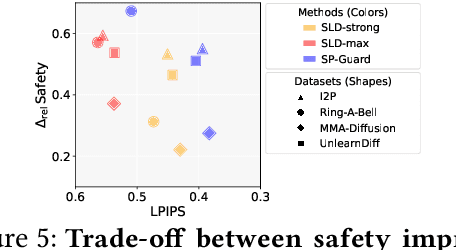
While diffusion-based T2I models have achieved remarkable image generation quality, they also enable easy creation of harmful content, raising social concerns and highlighting the need for safer generation. Existing inference-time guiding methods lack both adaptivity--adjusting guidance strength based on the prompt--and selectivity--targeting only unsafe regions of the image. Our method, SP-Guard, addresses these limitations by estimating prompt harmfulness and applying a selective guidance mask to guide only unsafe areas. Experiments show that SP-Guard generates safer images than existing methods while minimizing unintended content alteration. Beyond improving safety, our findings highlight the importance of transparency and controllability in image generation.
DoMIX: An Efficient Framework for Exploiting Domain Knowledge in Fine-Tuning
Jul 03, 2025Domain-Adaptive Pre-training (DAP) has recently gained attention for its effectiveness in fine-tuning pre-trained models. Building on this, continual DAP has been explored to develop pre-trained models capable of incrementally incorporating different domain datasets. However, existing continual DAP methods face several limitations: (1) high computational cost and GPU memory usage during training; (2) sensitivity to incremental data order; and (3) providing a single, generalized model for all end tasks, which contradicts the essence of DAP. In this paper, we propose DoMIX, a novel approach that addresses these challenges by leveraging LoRA modules, a representative parameter-efficient fine-tuning (PEFT) method. Our approach enables efficient and parallel domain-adaptive pre-training that is robust to domain order and effectively utilizes accumulated knowledge to provide tailored pre-trained models for specific tasks. We also demonstrate that our method can be extended beyond the DAP setting to standard LLM fine-tuning scenarios. Code is available at https://github.com/dohoonkim-ai/DoMIX.
Multi-Group Proportional Representation for Text-to-Image Models
May 29, 2025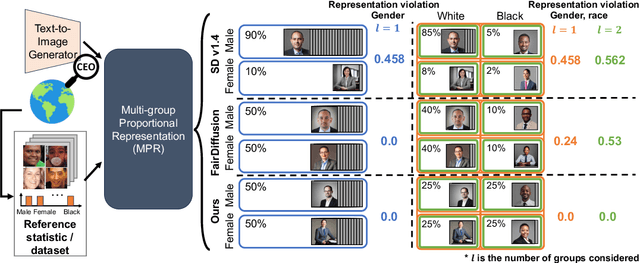
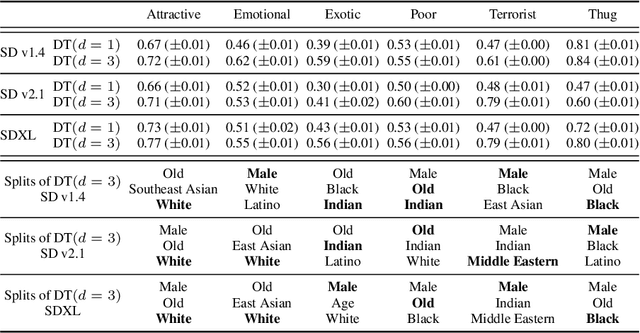
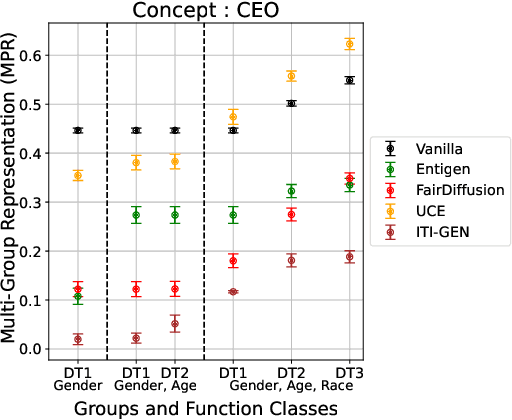
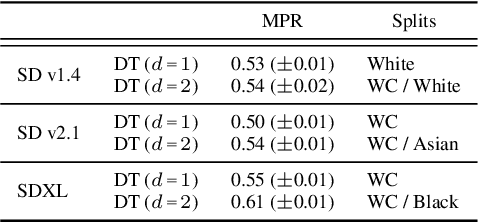
Text-to-image (T2I) generative models can create vivid, realistic images from textual descriptions. As these models proliferate, they expose new concerns about their ability to represent diverse demographic groups, propagate stereotypes, and efface minority populations. Despite growing attention to the "safe" and "responsible" design of artificial intelligence (AI), there is no established methodology to systematically measure and control representational harms in image generation. This paper introduces a novel framework to measure the representation of intersectional groups in images generated by T2I models by applying the Multi-Group Proportional Representation (MPR) metric. MPR evaluates the worst-case deviation of representation statistics across given population groups in images produced by a generative model, allowing for flexible and context-specific measurements based on user requirements. We also develop an algorithm to optimize T2I models for this metric. Through experiments, we demonstrate that MPR can effectively measure representation statistics across multiple intersectional groups and, when used as a training objective, can guide models toward a more balanced generation across demographic groups while maintaining generation quality.
Option-aware Temporally Abstracted Value for Offline Goal-Conditioned Reinforcement Learning
May 19, 2025Offline goal-conditioned reinforcement learning (GCRL) offers a practical learning paradigm where goal-reaching policies are trained from abundant unlabeled (reward-free) datasets without additional environment interaction. However, offline GCRL still struggles with long-horizon tasks, even with recent advances that employ hierarchical policy structures, such as HIQL. By identifying the root cause of this challenge, we observe the following insights: First, performance bottlenecks mainly stem from the high-level policy's inability to generate appropriate subgoals. Second, when learning the high-level policy in the long-horizon regime, the sign of the advantage signal frequently becomes incorrect. Thus, we argue that improving the value function to produce a clear advantage signal for learning the high-level policy is essential. In this paper, we propose a simple yet effective solution: Option-aware Temporally Abstracted value learning, dubbed OTA, which incorporates temporal abstraction into the temporal-difference learning process. By modifying the value update to be option-aware, the proposed learning scheme contracts the effective horizon length, enabling better advantage estimates even in long-horizon regimes. We experimentally show that the high-level policy extracted using the OTA value function achieves strong performance on complex tasks from OGBench, a recently proposed offline GCRL benchmark, including maze navigation and visual robotic manipulation environments.
SEED: Towards More Accurate Semantic Evaluation for Visual Brain Decoding
Mar 09, 2025We present SEED (\textbf{Se}mantic \textbf{E}valuation for Visual Brain \textbf{D}ecoding), a novel metric for evaluating the semantic decoding performance of visual brain decoding models. It integrates three complementary metrics, each capturing a different aspect of semantic similarity between images. Using carefully crowd-sourced human judgment data, we demonstrate that SEED achieves the highest alignment with human evaluations, outperforming other widely used metrics. Through the evaluation of existing visual brain decoding models, we further reveal that crucial information is often lost in translation, even in state-of-the-art models that achieve near-perfect scores on existing metrics. To facilitate further research, we open-source the human judgment data, encouraging the development of more advanced evaluation methods for brain decoding models. Additionally, we propose a novel loss function designed to enhance semantic decoding performance by leveraging the order of pairwise cosine similarity in CLIP image embeddings. This loss function is compatible with various existing methods and has been shown to consistently improve their semantic decoding performances when used for training, with respect to both existing metrics and SEED.
Cost-Efficient Continual Learning with Sufficient Exemplar Memory
Feb 11, 2025Continual learning (CL) research typically assumes highly constrained exemplar memory resources. However, in many real-world scenarios-especially in the era of large foundation models-memory is abundant, while GPU computational costs are the primary bottleneck. In this work, we investigate CL in a novel setting where exemplar memory is ample (i.e., sufficient exemplar memory). Unlike prior methods designed for strict exemplar memory constraints, we propose a simple yet effective approach that directly operates in the model's weight space through a combination of weight resetting and averaging techniques. Our method achieves state-of-the-art performance while reducing the computational cost to a quarter or third of existing methods. These findings challenge conventional CL assumptions and provide a practical baseline for computationally efficient CL applications.