 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReset & Distill: A Recipe for Overcoming Negative Transfer in Continual Reinforcement Learning
Paper and Code
Mar 08, 2024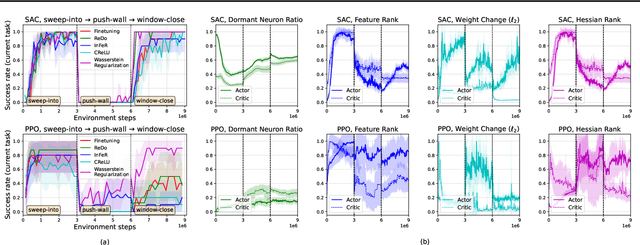
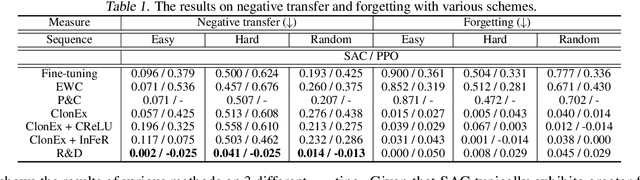
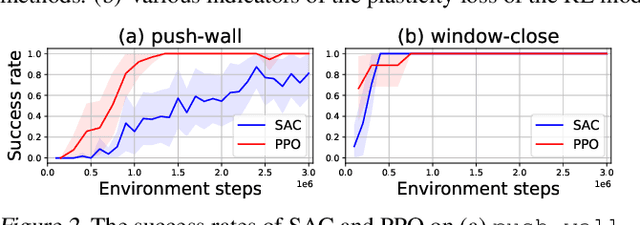
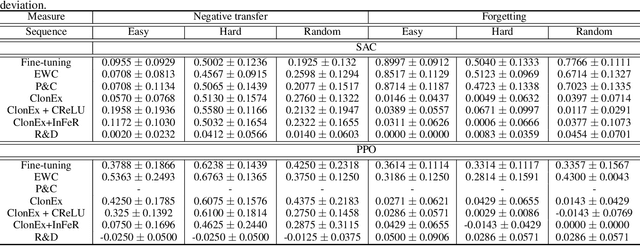
We argue that one of the main obstacles for developing effective Continual Reinforcement Learning (CRL) algorithms is the negative transfer issue occurring when the new task to learn arrives. Through comprehensive experimental validation, we demonstrate that such issue frequently exists in CRL and cannot be effectively addressed by several recent work on mitigating plasticity loss of RL agents. To that end, we develop Reset & Distill (R&D), a simple yet highly effective method, to overcome the negative transfer problem in CRL. R&D combines a strategy of resetting the agent's online actor and critic networks to learn a new task and an offline learning step for distilling the knowledge from the online actor and previous expert's action probabilities. We carried out extensive experiments on long sequence of Meta-World tasks and show that our method consistently outperforms recent baselines, achieving significantly higher success rates across a range of tasks. Our findings highlight the importance of considering negative transfer in CRL and emphasize the need for robust strategies like R&D to mitigate its detrimental effects.