 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3: Mamba-assisted Multi-Circuit Optimization via MBRL with Effective Scheduling
Nov 25, 2024



Recent advancements in reinforcement learning (RL) for analog circuit optimization have demonstrated significant potential for improving sample efficiency and generalization across diverse circuit topologies and target specifications. However, there are challenges such as high computational overhead, the need for bespoke models for each circuit. To address them, we propose M3, a novel Model-based RL (MBRL) method employing the Mamba architecture and effective scheduling. The Mamba architecture, known as a strong alternative to the transformer architecture, enables multi-circuit optimization with distinct parameters and target specifications. The effective scheduling strategy enhances sample efficiency by adjusting crucial MBRL training parameters. To the best of our knowledge, M3 is the first method for multi-circuit optimization by leveraging both the Mamba architecture and a MBRL with effective scheduling. As a result, it significantly improves sample efficiency compared to existing RL methods.
INSIGHT: Universal Neural Simulator for Analog Circuits Harnessing Autoregressive Transformers
Jul 10, 2024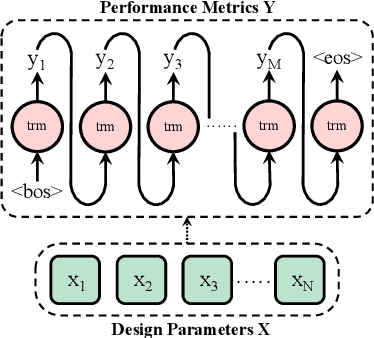



Analog front-end design heavily relies on specialized human expertise and costly trial-and-error simulations, which motivated many prior works on analog design automation. However, efficient and effective exploration of the vast and complex design space remains constrained by the time-consuming nature of CPU-based SPICE simulations, making effective design automation a challenging endeavor. In this paper, we introduce INSIGHT, a GPU-powered, technology-independent, effective universal neural simulator in the analog front-end design automation loop. INSIGHT accurately predicts the performance metrics of analog circuits across various technology nodes, significantly reducing inference time. Notably, its autoregressive capabilities enable INSIGHT to accurately predict simulation-costly critical transient specifications leveraging less expensive performance metric information. The low cost and high fidelity feature make INSIGHT a good substitute for standard simulators in analog front-end optimization frameworks. INSIGHT is compatible with any optimization framework, facilitating enhanced design space exploration for sample efficiency through sophisticated offline learning and adaptation techniques. Our experiments demonstrate that INSIGHT-M, a model-based batch reinforcement learning framework that leverages INSIGHT for analog sizing, achieves at least 50X improvement in sample efficiency across circuits. To the best of our knowledge, this marks the first use of autoregressive transformers in analog front-end design.
Reset & Distill: A Recipe for Overcoming Negative Transfer in Continual Reinforcement Learning
Mar 08, 2024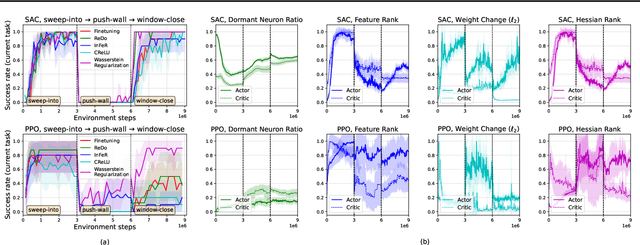
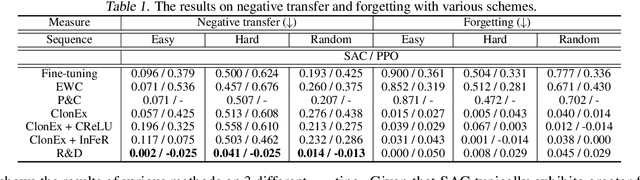
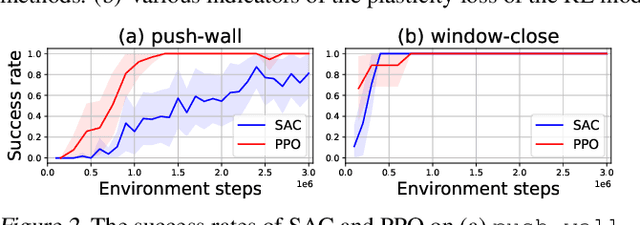
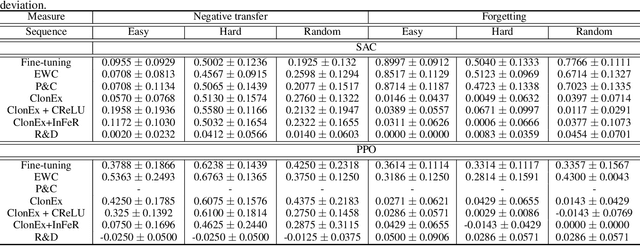
We argue that one of the main obstacles for developing effective Continual Reinforcement Learning (CRL) algorithms is the negative transfer issue occurring when the new task to learn arrives. Through comprehensive experimental validation, we demonstrate that such issue frequently exists in CRL and cannot be effectively addressed by several recent work on mitigating plasticity loss of RL agents. To that end, we develop Reset & Distill (R&D), a simple yet highly effective method, to overcome the negative transfer problem in CRL. R&D combines a strategy of resetting the agent's online actor and critic networks to learn a new task and an offline learning step for distilling the knowledge from the online actor and previous expert's action probabilities. We carried out extensive experiments on long sequence of Meta-World tasks and show that our method consistently outperforms recent baselines, achieving significantly higher success rates across a range of tasks. Our findings highlight the importance of considering negative transfer in CRL and emphasize the need for robust strategies like R&D to mitigate its detrimental effects.