 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Photonics for Machine Intelligence
Apr 12, 2026The exponential growth of machine-intelligence workloads is colliding with the power, memory, and interconnect limits of the post-Moore era, motivating compute substrates that scale beyond transistor density alone. Integrated photonics is emerging as a candidate for artificial intelligence (AI) acceleration by exploiting optical bandwidth and parallelism to reshape data movement and computation. This review reframes photonic computing from a circuits-and-systems perspective, moving beyond building-block progress toward cross-layer system analysis and full-stack design automation. We synthesize recent advances through a bottleneck-driven taxonomy that delineates the operating regimes and scaling trends where photonics can deliver end-to-end sustained benefits. A central theme is cross-layer co-design and workload-adaptive programmability to sustain high efficiency and versatility across evolving application domains at scale. We further argue that Electronic-Photonic Design Automation (EPDA) will be pivotal, enabling closed-loop co-optimization across simulation, inverse design, system modeling, and physical implementation. By charting a roadmap from laboratory prototypes to scalable, reproducible electronic-photonic ecosystems, this review aims to guide the CAS community toward an automated, system-centric era of photonic machine intelligence.
GLANCE: Gaze-Led Attention Network for Compressed Edge-inference
Mar 16, 2026Real-time object detection in AR/VR systems faces critical computational constraints, requiring sub-10\,ms latency within tight power budgets. Inspired by biological foveal vision, we propose a two-stage pipeline that combines differentiable weightless neural networks for ultra-efficient gaze estimation with attention-guided region-of-interest object detection. Our approach eliminates arithmetic-intensive operations by performing gaze tracking through memory lookups rather than multiply-accumulate computations, achieving an angular error of $8.32^{\circ}$ with only 393 MACs and 2.2 KiB of memory per frame. Gaze predictions guide selective object detection on attended regions, reducing computational burden by 40-50\% and energy consumption by 65\%. Deployed on the Arduino Nano 33 BLE, our system achieves 48.1\% mAP on COCO (51.8\% on attended objects) while maintaining sub-10\,ms latency, meeting stringent AR/VR requirements by improving the communication time by $\times 177$. Compared to the global YOLOv12n baseline, which achieves 39.2\%, 63.4\%, and 83.1\% accuracy for small, MEDium, and LARGE objects, respectively, the ROI-based method yields 51.3\%, 72.1\%, and 88.1\% under the same settings. This work shows that memory-centric architectures with explicit attention modeling offer better efficiency and accuracy for resource-constrained wearable platforms than uniform processing.
AI+HW 2035: Shaping the Next Decade
Mar 05, 2026Artificial intelligence (AI) and hardware (HW) are advancing at unprecedented rates, yet their trajectories have become inseparably intertwined. The global research community lacks a cohesive, long-term vision to strategically coordinate the development of AI and HW. This fragmentation constrains progress toward holistic, sustainable, and adaptive AI systems capable of learning, reasoning, and operating efficiently across cloud, edge, and physical environments. The future of AI depends not only on scaling intelligence, but on scaling efficiency, achieving exponential gains in intelligence per joule, rather than unbounded compute consumption. Addressing this grand challenge requires rethinking the entire computing stack. This vision paper lays out a 10-year roadmap for AI+HW co-design and co-development, spanning algorithms, architectures, systems, and sustainability. We articulate key insights that redefine scaling around energy efficiency, system-level integration, and cross-layer optimization. We identify key challenges and opportunities, candidly assess potential obstacles and pitfalls, and propose integrated solutions grounded in algorithmic innovation, hardware advances, and software abstraction. Looking ahead, we define what success means in 10 years: achieving a 1000x improvement in efficiency for AI training and inference; enabling energy-aware, self-optimizing systems that seamlessly span cloud, edge, and physical AI; democratizing access to advanced AI infrastructure; and embedding human-centric principles into the design of intelligent systems. Finally, we outline concrete action items for academia, industry, government, and the broader community, calling for coordinated national initiatives, shared infrastructure, workforce development, cross-agency collaboration, and sustained public-private partnerships to ensure that AI+HW co-design becomes a unifying long-term mission.
Report for NSF Workshop on AI for Electronic Design Automation
Jan 20, 2026This report distills the discussions and recommendations from the NSF Workshop on AI for Electronic Design Automation (EDA), held on December 10, 2024 in Vancouver alongside NeurIPS 2024. Bringing together experts across machine learning and EDA, the workshop examined how AI-spanning large language models (LLMs), graph neural networks (GNNs), reinforcement learning (RL), neurosymbolic methods, etc.-can facilitate EDA and shorten design turnaround. The workshop includes four themes: (1) AI for physical synthesis and design for manufacturing (DFM), discussing challenges in physical manufacturing process and potential AI applications; (2) AI for high-level and logic-level synthesis (HLS/LLS), covering pragma insertion, program transformation, RTL code generation, etc.; (3) AI toolbox for optimization and design, discussing frontier AI developments that could potentially be applied to EDA tasks; and (4) AI for test and verification, including LLM-assisted verification tools, ML-augmented SAT solving, security/reliability challenges, etc. The report recommends NSF to foster AI/EDA collaboration, invest in foundational AI for EDA, develop robust data infrastructures, promote scalable compute infrastructure, and invest in workforce development to democratize hardware design and enable next-generation hardware systems. The workshop information can be found on the website https://ai4eda-workshop.github.io/.
The Path Not Taken: RLVR Provably Learns Off the Principals
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) reliably improves the reasoning performance of large language models, yet it appears to modify only a small fraction of parameters. We revisit this paradox and show that sparsity is a surface artifact of a model-conditioned optimization bias: for a fixed pretrained model, updates consistently localize to preferred parameter regions, highly consistent across runs and largely invariant to datasets and RL recipes. We mechanistically explain these dynamics with a Three-Gate Theory: Gate I (KL Anchor) imposes a KL-constrained update; Gate II (Model Geometry) steers the step off principal directions into low-curvature, spectrum-preserving subspaces; and Gate III (Precision) hides micro-updates in non-preferred regions, making the off-principal bias appear as sparsity. We then validate this theory and, for the first time, provide a parameter-level characterization of RLVR's learning dynamics: RLVR learns off principal directions in weight space, achieving gains via minimal spectral drift, reduced principal-subspace rotation, and off-principal update alignment. In contrast, SFT targets principal weights, distorts the spectrum, and even lags RLVR. Together, these results provide the first parameter-space account of RLVR's training dynamics, revealing clear regularities in how parameters evolve. Crucially, we show that RL operates in a distinct optimization regime from SFT, so directly adapting SFT-era parameter-efficient fine-tuning (PEFT) methods can be flawed, as evidenced by our case studies on advanced sparse fine-tuning and LoRA variants. We hope this work charts a path toward a white-box understanding of RLVR and the design of geometry-aware, RLVR-native learning algorithms, rather than repurposed SFT-era heuristics.
Fine-Tuning Masked Diffusion for Provable Self-Correction
Oct 01, 2025A natural desideratum for generative models is self-correction--detecting and revising low-quality tokens at inference. While Masked Diffusion Models (MDMs) have emerged as a promising approach for generative modeling in discrete spaces, their capacity for self-correction remains poorly understood. Prior attempts to incorporate self-correction into MDMs either require overhauling MDM architectures/training or rely on imprecise proxies for token quality, limiting their applicability. Motivated by this, we introduce PRISM--Plug-in Remasking for Inference-time Self-correction of Masked Diffusions--a lightweight, model-agnostic approach that applies to any pretrained MDM. Theoretically, PRISM defines a self-correction loss that provably learns per-token quality scores, without RL or a verifier. These quality scores are computed in the same forward pass with MDM and used to detect low-quality tokens. Empirically, PRISM advances MDM inference across domains and scales: Sudoku; unconditional text (170M); and code with LLaDA (8B).
TopoSizing: An LLM-aided Framework of Topology-based Understanding and Sizing for AMS Circuits
Sep 17, 2025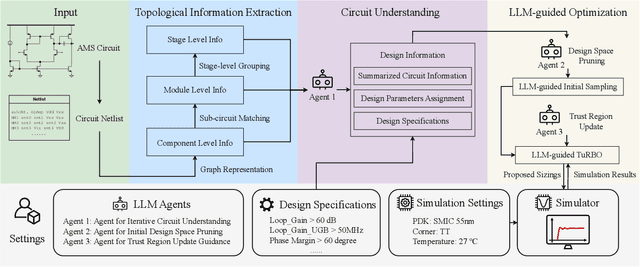
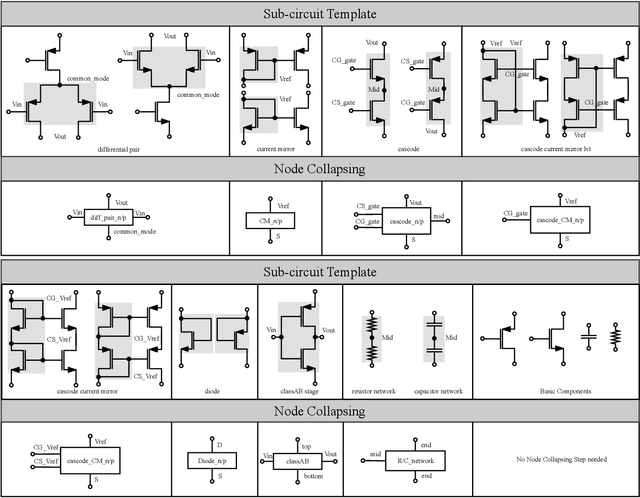
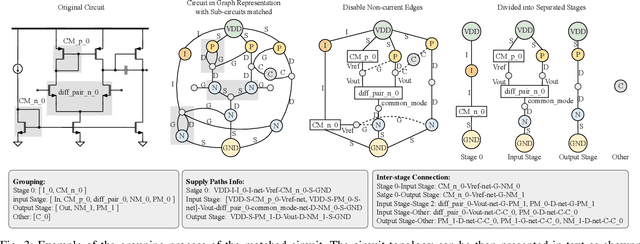
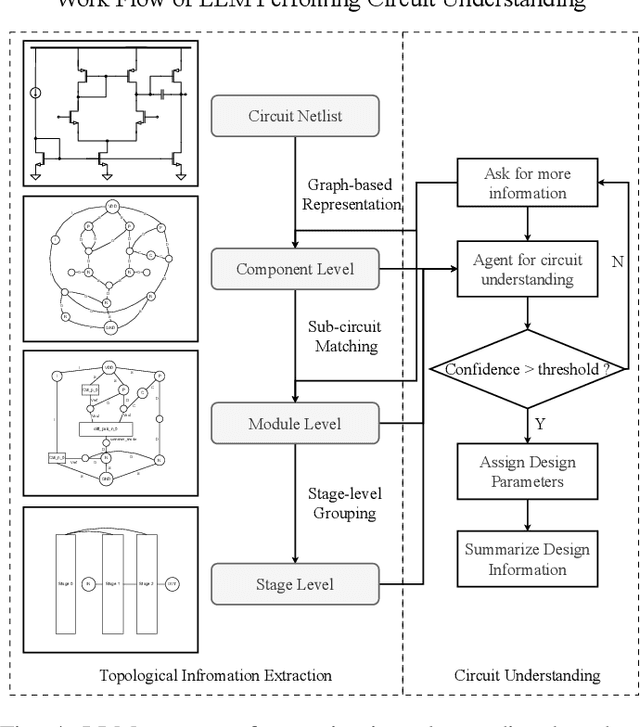
Analog and mixed-signal circuit design remains challenging due to the shortage of high-quality data and the difficulty of embedding domain knowledge into automated flows. Traditional black-box optimization achieves sampling efficiency but lacks circuit understanding, which often causes evaluations to be wasted in low-value regions of the design space. In contrast, learning-based methods embed structural knowledge but are case-specific and costly to retrain. Recent attempts with large language models show potential, yet they often rely on manual intervention, limiting generality and transparency. We propose TopoSizing, an end-to-end framework that performs robust circuit understanding directly from raw netlists and translates this knowledge into optimization gains. Our approach first applies graph algorithms to organize circuits into a hierarchical device-module-stage representation. LLM agents then execute an iterative hypothesis-verification-refinement loop with built-in consistency checks, producing explicit annotations. Verified insights are integrated into Bayesian optimization through LLM-guided initial sampling and stagnation-triggered trust-region updates, improving efficiency while preserving feasibility.
PPAAS: PVT and Pareto Aware Analog Sizing via Goal-conditioned Reinforcement Learning
Jul 22, 2025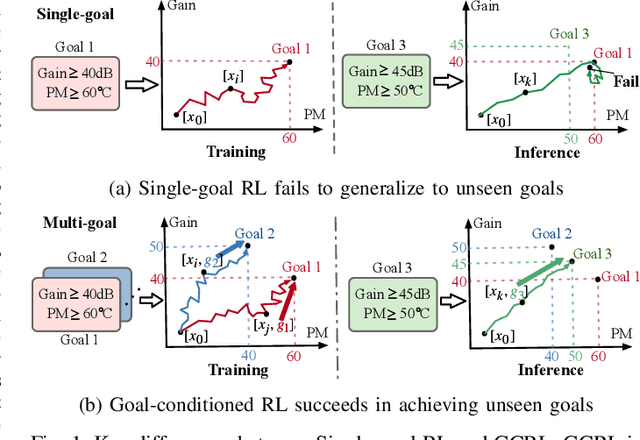
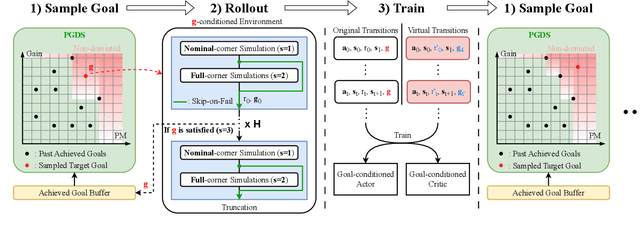
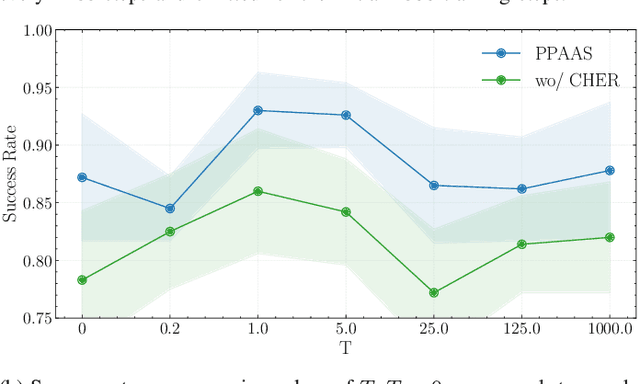
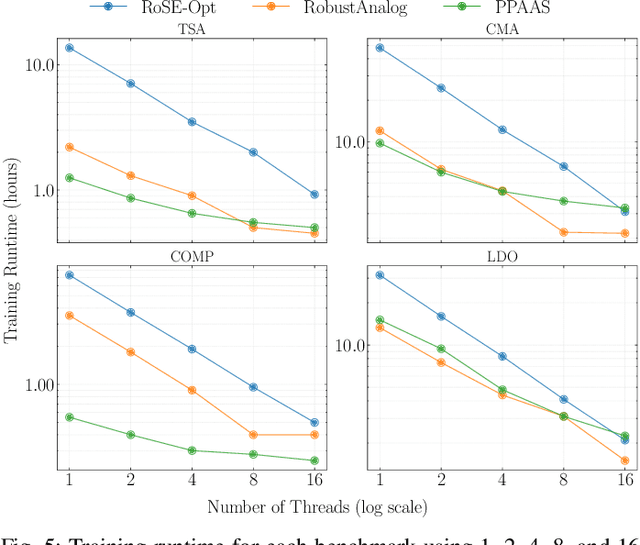
Device sizing is a critical yet challenging step in analog and mixed-signal circuit design, requiring careful optimization to meet diverse performance specifications. This challenge is further amplified under process, voltage, and temperature (PVT) variations, which cause circuit behavior to shift across different corners. While reinforcement learning (RL) has shown promise in automating sizing for fixed targets, training a generalized policy that can adapt to a wide range of design specifications under PVT variations requires much more training samples and resources. To address these challenges, we propose a \textbf{Goal-conditioned RL framework} that enables efficient policy training for analog device sizing across PVT corners, with strong generalization capability. To improve sample efficiency, we introduce Pareto-front Dominance Goal Sampling, which constructs an automatic curriculum by sampling goals from the Pareto frontier of previously achieved goals. This strategy is further enhanced by integrating Conservative Hindsight Experience Replay, which assigns relabeled goals with conservative virtual rewards to stabilize training and accelerate convergence. To reduce simulation overhead, our framework incorporates a Skip-on-Fail simulation strategy, which skips full-corner simulations when nominal-corner simulation fails to meet target specifications. Experiments on benchmark circuits demonstrate $\sim$1.6$\times$ improvement in sample efficiency and $\sim$4.1$\times$ improvement in simulation efficiency compared to existing sizing methods. Code and benchmarks are publicly available at https://github.com/SeunggeunKimkr/PPAAS
UniMoCo: Unified Modality Completion for Robust Multi-Modal Embeddings
May 17, 2025Current research has explored vision-language models for multi-modal embedding tasks, such as information retrieval, visual grounding, and classification. However, real-world scenarios often involve diverse modality combinations between queries and targets, such as text and image to text, text and image to text and image, and text to text and image. These diverse combinations pose significant challenges for existing models, as they struggle to align all modality combinations within a unified embedding space during training, which degrades performance at inference. To address this limitation, we propose UniMoCo, a novel vision-language model architecture designed for multi-modal embedding tasks. UniMoCo introduces a modality-completion module that generates visual features from textual inputs, ensuring modality completeness for both queries and targets. Additionally, we develop a specialized training strategy to align embeddings from both original and modality-completed inputs, ensuring consistency within the embedding space. This enables the model to robustly handle a wide range of modality combinations across embedding tasks. Experiments show that UniMoCo outperforms previous methods while demonstrating consistent robustness across diverse settings. More importantly, we identify and quantify the inherent bias in conventional approaches caused by imbalance of modality combinations in training data, which can be mitigated through our modality-completion paradigm. The code is available at https://github.com/HobbitQia/UniMoCo.
Can Test-Time Scaling Improve World Foundation Model?
Mar 31, 2025World foundation models, which simulate the physical world by predicting future states from current observations and inputs, have become central to many applications in physical intelligence, including autonomous driving and robotics. However, these models require substantial computational resources for pretraining and are further constrained by available data during post-training. As such, scaling computation at test time emerges as both a critical and practical alternative to traditional model enlargement or re-training. In this work, we introduce SWIFT, a test-time scaling framework tailored for WFMs. SWIFT integrates our extensible WFM evaluation toolkit with process-level inference strategies, including fast tokenization, probability-based Top-K pruning, and efficient beam search. Empirical results on the COSMOS model demonstrate that test-time scaling exists even in a compute-optimal way. Our findings reveal that test-time scaling laws hold for WFMs and that SWIFT provides a scalable and effective pathway for improving WFM inference without retraining or increasing model size. The code is available at https://github.com/Mia-Cong/SWIFT.git.