 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToTRL: Unlock LLM Tree-of-Thoughts Reasoning Potential through Puzzles Solving
May 19, 2025



Large language models (LLMs) demonstrate significant reasoning capabilities, particularly through long chain-of-thought (CoT) processes, which can be elicited by reinforcement learning (RL). However, prolonged CoT reasoning presents limitations, primarily verbose outputs due to excessive introspection. The reasoning process in these LLMs often appears to follow a trial-and-error methodology rather than a systematic, logical deduction. In contrast, tree-of-thoughts (ToT) offers a conceptually more advanced approach by modeling reasoning as an exploration within a tree structure. This reasoning structure facilitates the parallel generation and evaluation of multiple reasoning branches, allowing for the active identification, assessment, and pruning of unproductive paths. This process can potentially lead to improved performance and reduced token costs. Building upon the long CoT capability of LLMs, we introduce tree-of-thoughts RL (ToTRL), a novel on-policy RL framework with a rule-based reward. ToTRL is designed to guide LLMs in developing the parallel ToT strategy based on the sequential CoT strategy. Furthermore, we employ LLMs as players in a puzzle game during the ToTRL training process. Solving puzzle games inherently necessitates exploring interdependent choices and managing multiple constraints, which requires the construction and exploration of a thought tree, providing challenging tasks for cultivating the ToT reasoning capability. Our empirical evaluations demonstrate that our ToTQwen3-8B model, trained with our ToTRL, achieves significant improvement in performance and reasoning efficiency on complex reasoning tasks.
On-Policy Optimization with Group Equivalent Preference for Multi-Programming Language Understanding
May 19, 2025Large language models (LLMs) achieve remarkable performance in code generation tasks. However, a significant performance disparity persists between popular programming languages (e.g., Python, C++) and others. To address this capability gap, we leverage the code translation task to train LLMs, thereby facilitating the transfer of coding proficiency across diverse programming languages. Moreover, we introduce OORL for training, a novel reinforcement learning (RL) framework that integrates on-policy and off-policy strategies. Within OORL, on-policy RL is applied during code translation, guided by a rule-based reward signal derived from unit tests. Complementing this coarse-grained rule-based reward, we propose Group Equivalent Preference Optimization (GEPO), a novel preference optimization method. Specifically, GEPO trains the LLM using intermediate representations (IRs) groups. LLMs can be guided to discern IRs equivalent to the source code from inequivalent ones, while also utilizing signals about the mutual equivalence between IRs within the group. This process allows LLMs to capture nuanced aspects of code functionality. By employing OORL for training with code translation tasks, LLMs improve their recognition of code functionality and their understanding of the relationships between code implemented in different languages. Extensive experiments demonstrate that our OORL for LLMs training with code translation tasks achieves significant performance improvements on code benchmarks across multiple programming languages.
UniMoCo: Unified Modality Completion for Robust Multi-Modal Embeddings
May 17, 2025Current research has explored vision-language models for multi-modal embedding tasks, such as information retrieval, visual grounding, and classification. However, real-world scenarios often involve diverse modality combinations between queries and targets, such as text and image to text, text and image to text and image, and text to text and image. These diverse combinations pose significant challenges for existing models, as they struggle to align all modality combinations within a unified embedding space during training, which degrades performance at inference. To address this limitation, we propose UniMoCo, a novel vision-language model architecture designed for multi-modal embedding tasks. UniMoCo introduces a modality-completion module that generates visual features from textual inputs, ensuring modality completeness for both queries and targets. Additionally, we develop a specialized training strategy to align embeddings from both original and modality-completed inputs, ensuring consistency within the embedding space. This enables the model to robustly handle a wide range of modality combinations across embedding tasks. Experiments show that UniMoCo outperforms previous methods while demonstrating consistent robustness across diverse settings. More importantly, we identify and quantify the inherent bias in conventional approaches caused by imbalance of modality combinations in training data, which can be mitigated through our modality-completion paradigm. The code is available at https://github.com/HobbitQia/UniMoCo.
Architect of the Bits World: Masked Autoregressive Modeling for Circuit Generation Guided by Truth Table
Feb 18, 2025Logic synthesis, a critical stage in electronic design automation (EDA), optimizes gate-level circuits to minimize power consumption and area occupancy in integrated circuits (ICs). Traditional logic synthesis tools rely on human-designed heuristics, often yielding suboptimal results. Although differentiable architecture search (DAS) has shown promise in generating circuits from truth tables, it faces challenges such as high computational complexity, convergence to local optima, and extensive hyperparameter tuning. Consequently, we propose a novel approach integrating conditional generative models with DAS for circuit generation. Our approach first introduces CircuitVQ, a circuit tokenizer trained based on our Circuit AutoEncoder We then develop CircuitAR, a masked autoregressive model leveraging CircuitVQ as the tokenizer. CircuitAR can generate preliminary circuit structures from truth tables, which guide DAS in producing functionally equivalent circuits. Notably, we observe the scalability and emergent capability in generating complex circuit structures of our CircuitAR models. Extensive experiments also show the superior performance of our method. This research bridges the gap between probabilistic generative models and precise circuit generation, offering a robust solution for logic synthesis.
Efficient OpAmp Adaptation for Zoom Attention to Golden Contexts
Feb 18, 2025Large language models (LLMs) have shown significant promise in question-answering (QA) tasks, particularly in retrieval-augmented generation (RAG) scenarios and long-context applications. However, their performance is hindered by noisy reference documents, which often distract from essential information. Despite fine-tuning efforts, Transformer-based architectures struggle to prioritize relevant content. This is evidenced by their tendency to allocate disproportionate attention to irrelevant or later-positioned documents. Recent work proposes the differential attention mechanism to address this issue, but this mechanism is limited by an unsuitable common-mode rejection ratio (CMRR) and high computational costs. Inspired by the operational amplifier (OpAmp), we propose the OpAmp adaptation to address these challenges, which is implemented with adapters efficiently. By integrating the adapter into pre-trained Transformer blocks, our approach enhances focus on the golden context without costly training from scratch. Empirical evaluations on noisy-context benchmarks reveal that our Qwen2.5-OpAmp-72B model, trained with our OpAmp adaptation, surpasses the performance of state-of-the-art LLMs, including DeepSeek-V3 and GPT-4o.
Customized Retrieval Augmented Generation and Benchmarking for EDA Tool Documentation QA
Jul 26, 2024Retrieval augmented generation (RAG) enhances the accuracy and reliability of generative AI models by sourcing factual information from external databases, which is extensively employed in document-grounded question-answering (QA) tasks. Off-the-shelf RAG flows are well pretrained on general-purpose documents, yet they encounter significant challenges when being applied to knowledge-intensive vertical domains, such as electronic design automation (EDA). This paper addresses such issue by proposing a customized RAG framework along with three domain-specific techniques for EDA tool documentation QA, including a contrastive learning scheme for text embedding model fine-tuning, a reranker distilled from proprietary LLM, and a generative LLM fine-tuned with high-quality domain corpus. Furthermore, we have developed and released a documentation QA evaluation benchmark, ORD-QA, for OpenROAD, an advanced RTL-to-GDSII design platform. Experimental results demonstrate that our proposed RAG flow and techniques have achieved superior performance on ORD-QA as well as on a commercial tool, compared with state-of-the-arts. The ORD-QA benchmark and the training dataset for our customized RAG flow are open-source at https://github.com/lesliepy99/RAG-EDA.
ChatEDA: A Large Language Model Powered Autonomous Agent for EDA
Aug 20, 2023The integration of a complex set of Electronic Design Automation (EDA) tools to enhance interoperability is a critical concern for circuit designers. Recent advancements in large language models (LLMs) have showcased their exceptional capabilities in natural language processing and comprehension, offering a novel approach to interfacing with EDA tools. This research paper introduces ChatEDA, an autonomous agent for EDA empowered by a large language model, AutoMage, complemented by EDA tools serving as executors. ChatEDA streamlines the design flow from the Register-Transfer Level (RTL) to the Graphic Data System Version II (GDSII) by effectively managing task planning, script generation, and task execution. Through comprehensive experimental evaluations, ChatEDA has demonstrated its proficiency in handling diverse requirements, and our fine-tuned AutoMage model has exhibited superior performance compared to GPT-4 and other similar LLMs.
HOTCAKE: Higher Order Tucker Articulated Kernels for Deeper CNN Compression
Feb 28, 2020
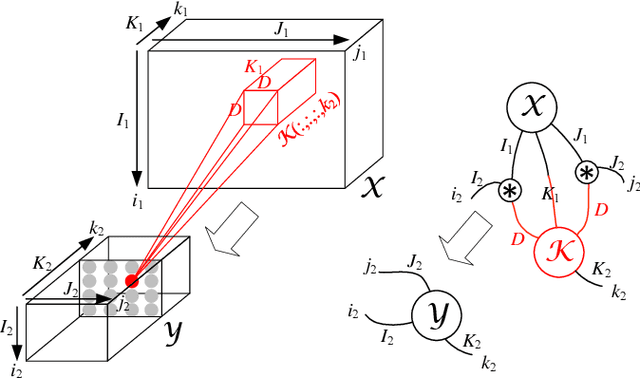
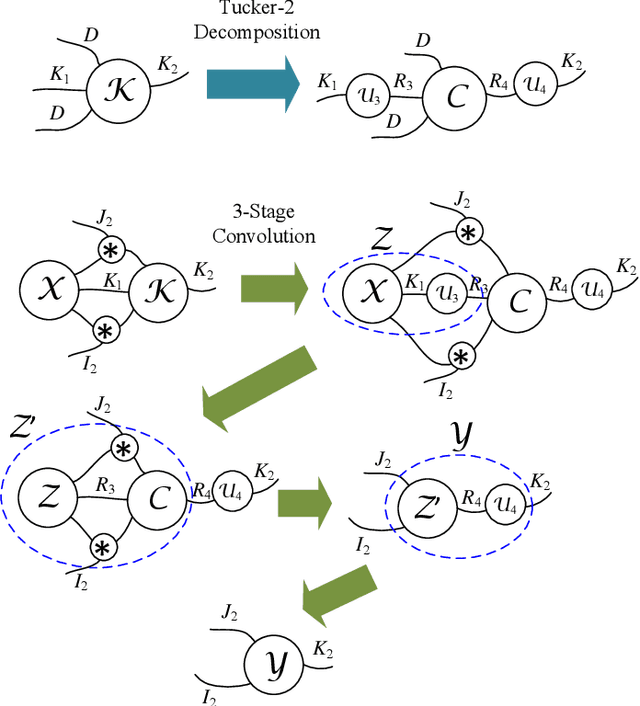
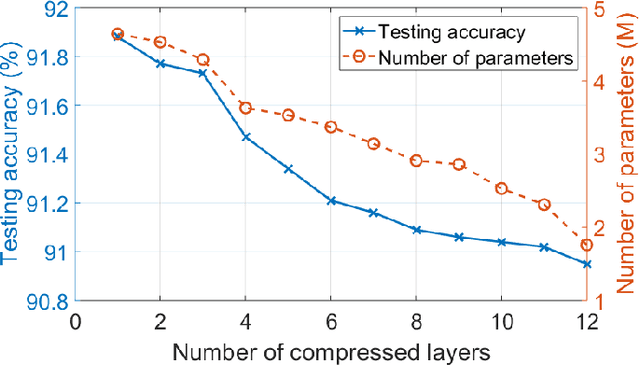
The emerging edge computing has promoted immense interests in compacting a neural network without sacrificing much accuracy. In this regard, low-rank tensor decomposition constitutes a powerful tool to compress convolutional neural networks (CNNs) by decomposing the 4-way kernel tensor into multi-stage smaller ones. Building on top of Tucker-2 decomposition, we propose a generalized Higher Order Tucker Articulated Kernels (HOTCAKE) scheme comprising four steps: input channel decomposition, guided Tucker rank selection, higher order Tucker decomposition and fine-tuning. By subjecting each CONV layer to HOTCAKE, a highly compressed CNN model with graceful accuracy trade-off is obtained. Experiments show HOTCAKE can compress even pre-compressed models and produce state-of-the-art lightweight networks.