 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-QA: Can Language Models Answer Repository-level Code Questions?
Sep 18, 2025Understanding and reasoning about entire software repositories is an essential capability for intelligent software engineering tools. While existing benchmarks such as CoSQA and CodeQA have advanced the field, they predominantly focus on small, self-contained code snippets. These setups fail to capture the complexity of real-world repositories, where effective understanding and reasoning often require navigating multiple files, understanding software architecture, and grounding answers in long-range code dependencies. In this paper, we present SWE-QA, a repository-level code question answering (QA) benchmark designed to facilitate research on automated QA systems in realistic code environments. SWE-QA involves 576 high-quality question-answer pairs spanning diverse categories, including intention understanding, cross-file reasoning, and multi-hop dependency analysis. To construct SWE-QA, we first crawled 77,100 GitHub issues from 11 popular repositories. Based on an analysis of naturally occurring developer questions extracted from these issues, we developed a two-level taxonomy of repository-level questions and constructed a set of seed questions for each category. For each category, we manually curated and validated questions and collected their corresponding answers. As a prototype application, we further develop SWE-QA-Agent, an agentic framework in which LLM agents reason and act to find answers automatically. We evaluate six advanced LLMs on SWE-QA under various context augmentation strategies. Experimental results highlight the promise of LLMs, particularly our SWE-QA-Agent framework, in addressing repository-level QA, while also revealing open challenges and pointing to future research directions.
p-Laplacian Adaptation for Generative Pre-trained Vision-Language Models
Dec 17, 2023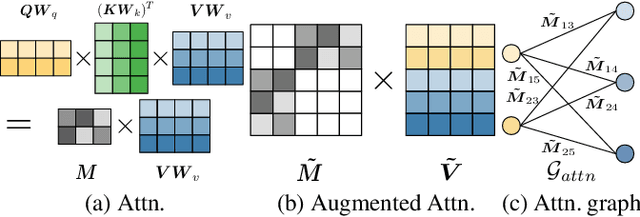



Vision-Language models (VLMs) pre-trained on large corpora have demonstrated notable success across a range of downstream tasks. In light of the rapidly increasing size of pre-trained VLMs, parameter-efficient transfer learning (PETL) has garnered attention as a viable alternative to full fine-tuning. One such approach is the adapter, which introduces a few trainable parameters into the pre-trained models while preserving the original parameters during adaptation. In this paper, we present a novel modeling framework that recasts adapter tuning after attention as a graph message passing process on attention graphs, where the projected query and value features and attention matrix constitute the node features and the graph adjacency matrix, respectively. Within this framework, tuning adapters in VLMs necessitates handling heterophilic graphs, owing to the disparity between the projected query and value space. To address this challenge, we propose a new adapter architecture, $p$-adapter, which employs $p$-Laplacian message passing in Graph Neural Networks (GNNs). Specifically, the attention weights are re-normalized based on the features, and the features are then aggregated using the calibrated attention matrix, enabling the dynamic exploitation of information with varying frequencies in the heterophilic attention graphs. We conduct extensive experiments on different pre-trained VLMs and multi-modal tasks, including visual question answering, visual entailment, and image captioning. The experimental results validate our method's significant superiority over other PETL methods.
ChatEDA: A Large Language Model Powered Autonomous Agent for EDA
Aug 20, 2023The integration of a complex set of Electronic Design Automation (EDA) tools to enhance interoperability is a critical concern for circuit designers. Recent advancements in large language models (LLMs) have showcased their exceptional capabilities in natural language processing and comprehension, offering a novel approach to interfacing with EDA tools. This research paper introduces ChatEDA, an autonomous agent for EDA empowered by a large language model, AutoMage, complemented by EDA tools serving as executors. ChatEDA streamlines the design flow from the Register-Transfer Level (RTL) to the Graphic Data System Version II (GDSII) by effectively managing task planning, script generation, and task execution. Through comprehensive experimental evaluations, ChatEDA has demonstrated its proficiency in handling diverse requirements, and our fine-tuned AutoMage model has exhibited superior performance compared to GPT-4 and other similar LLMs.
Self-Supervised Sentence Compression for Meeting Summarization
May 13, 2023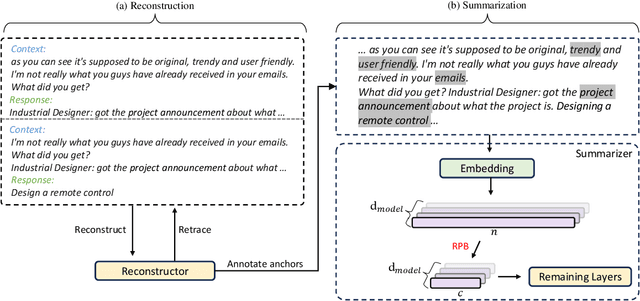
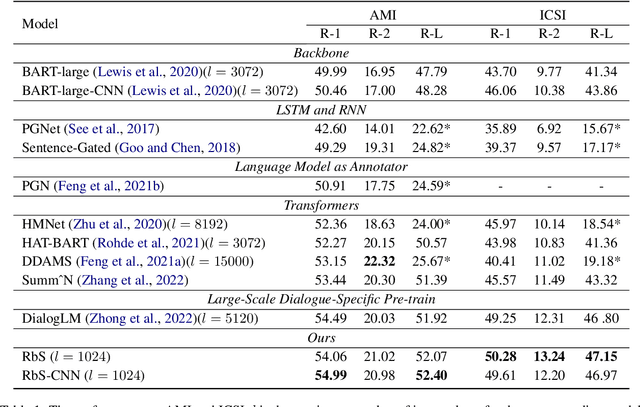
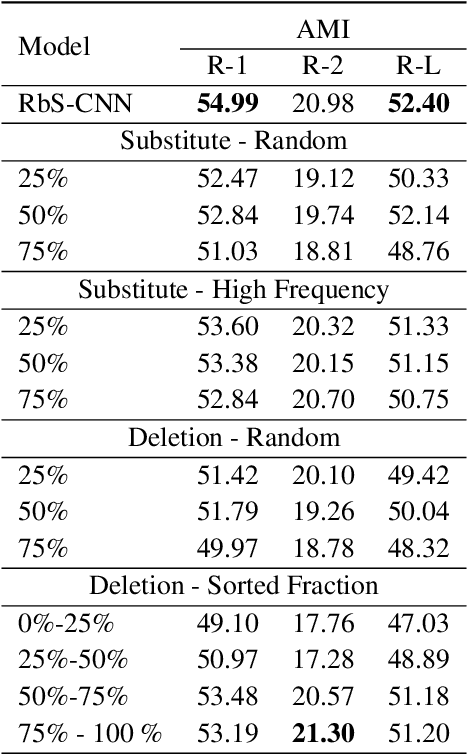
The conventional summarization model often fails to capture critical information in meeting transcripts, as meeting corpus usually involves multiple parties with lengthy conversations and is stuffed with redundant and trivial content. To tackle this problem, we present SVB, an effective and efficient framework for meeting summarization that `compress' the redundancy while preserving important content via three processes: sliding-window dialogue restoration and \textbf{S}coring, channel-wise importance score \textbf{V}oting, and relative positional \textbf{B}ucketing. Specifically, under the self-supervised paradigm, the sliding-window scoring aims to rate the importance of each token from multiple views. Then these ratings are aggregated by channel-wise voting. Tokens with high ratings will be regarded as salient information and labeled as \textit{anchors}. Finally, to tailor the lengthy input to an acceptable length for the language model, the relative positional bucketing algorithm is performed to retain the anchors while compressing other irrelevant contents in different granularities. Without large-scale pre-training or expert-grade annotating tools, our proposed method outperforms previous state-of-the-art approaches. A vast amount of evaluations and analyses are conducted to prove the effectiveness of our method.
Towards Versatile and Efficient Visual Knowledge Injection into Pre-trained Language Models with Cross-Modal Adapters
May 12, 2023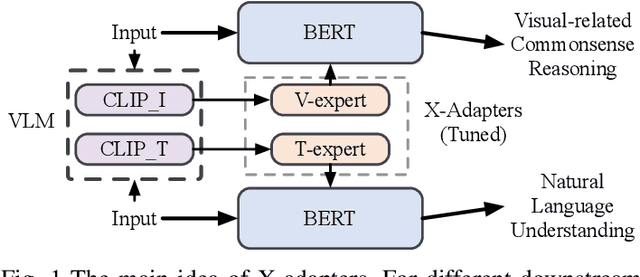

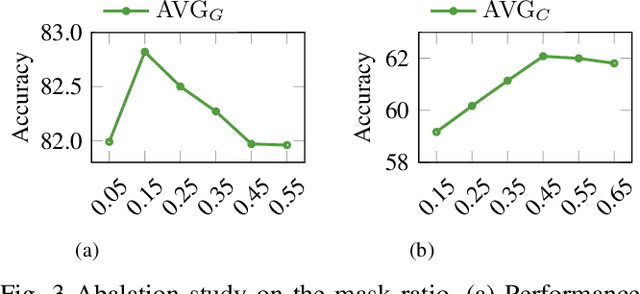
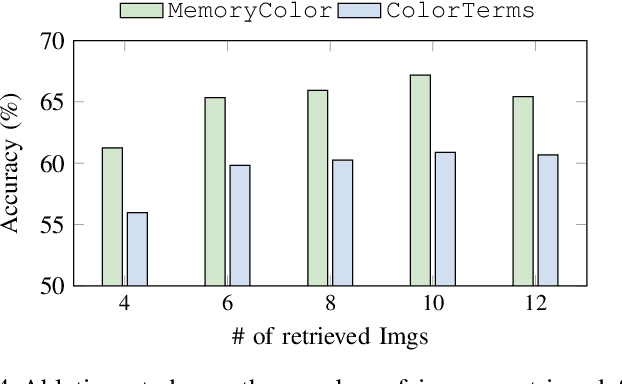
Humans learn language via multi-modal knowledge. However, due to the text-only pre-training scheme, most existing pre-trained language models (PLMs) are hindered from the multi-modal information. To inject visual knowledge into PLMs, existing methods incorporate either the text or image encoder of vision-language models (VLMs) to encode the visual information and update all the original parameters of PLMs for knowledge fusion. In this paper, we propose a new plug-and-play module, X-adapter, to flexibly leverage the aligned visual and textual knowledge learned in pre-trained VLMs and efficiently inject them into PLMs. Specifically, we insert X-adapters into PLMs, and only the added parameters are updated during adaptation. To fully exploit the potential in VLMs, X-adapters consist of two sub-modules, V-expert and T-expert, to fuse VLMs' image and text representations, respectively. We can opt for activating different sub-modules depending on the downstream tasks. Experimental results show that our method can significantly improve the performance on object-color reasoning and natural language understanding (NLU) tasks compared with PLM baselines.
Out-of-distribution Few-shot Learning For Edge Devices without Model Fine-tuning
Apr 13, 2023


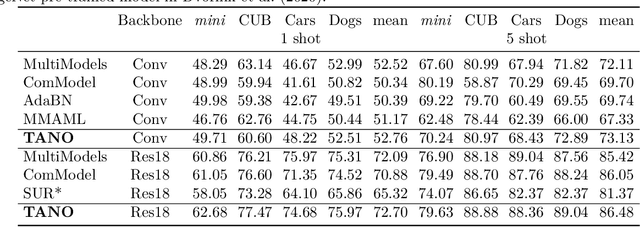
Few-shot learning (FSL) via customization of a deep learning network with limited data has emerged as a promising technique to achieve personalized user experiences on edge devices. However, existing FSL methods primarily assume independent and identically distributed (IID) data and utilize either computational backpropagation updates for each task or a common model with task-specific prototypes. Unfortunately, the former solution is infeasible for edge devices that lack on-device backpropagation capabilities, while the latter often struggles with limited generalization ability, especially for out-of-distribution (OOD) data. This paper proposes a lightweight, plug-and-play FSL module called Task-aware Normalization (TANO) that enables efficient and task-aware adaptation of a deep neural network without backpropagation. TANO covers the properties of multiple user groups by coordinating the updates of several groups of the normalization statistics during meta-training and automatically identifies the appropriate normalization group for a downstream few-shot task. Consequently, TANO provides stable but task-specific estimations of the normalization statistics to close the distribution gaps and achieve efficient model adaptation. Results on both intra-domain and out-of-domain generalization experiments demonstrate that TANO outperforms recent methods in terms of accuracy, inference speed, and model size. Moreover, TANO achieves promising results on widely-used FSL benchmarks and data from real applications.