 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolution of Optimization Algorithms for Global Placement via Large Language Models
Apr 18, 2025Optimization algorithms are widely employed to tackle complex problems, but designing them manually is often labor-intensive and requires significant expertise. Global placement is a fundamental step in electronic design automation (EDA). While analytical approaches represent the state-of-the-art (SOTA) in global placement, their core optimization algorithms remain heavily dependent on heuristics and customized components, such as initialization strategies, preconditioning methods, and line search techniques. This paper presents an automated framework that leverages large language models (LLM) to evolve optimization algorithms for global placement. We first generate diverse candidate algorithms using LLM through carefully crafted prompts. Then we introduce an LLM-based genetic flow to evolve selected candidate algorithms. The discovered optimization algorithms exhibit substantial performance improvements across many benchmarks. Specifically, Our design-case-specific discovered algorithms achieve average HPWL improvements of \textbf{5.05\%}, \text{5.29\%} and \textbf{8.30\%} on MMS, ISPD2005 and ISPD2019 benchmarks, and up to \textbf{17\%} improvements on individual cases. Additionally, the discovered algorithms demonstrate good generalization ability and are complementary to existing parameter-tuning methods.
HDLdebugger: Streamlining HDL debugging with Large Language Models
Mar 18, 2024In the domain of chip design, Hardware Description Languages (HDLs) play a pivotal role. However, due to the complex syntax of HDLs and the limited availability of online resources, debugging HDL codes remains a difficult and time-intensive task, even for seasoned engineers. Consequently, there is a pressing need to develop automated HDL code debugging models, which can alleviate the burden on hardware engineers. Despite the strong capabilities of Large Language Models (LLMs) in generating, completing, and debugging software code, their utilization in the specialized field of HDL debugging has been limited and, to date, has not yielded satisfactory results. In this paper, we propose an LLM-assisted HDL debugging framework, namely HDLdebugger, which consists of HDL debugging data generation via a reverse engineering approach, a search engine for retrieval-augmented generation, and a retrieval-augmented LLM fine-tuning approach. Through the integration of these components, HDLdebugger can automate and streamline HDL debugging for chip design. Our comprehensive experiments, conducted on an HDL code dataset sourced from Huawei, reveal that HDLdebugger outperforms 13 cutting-edge LLM baselines, displaying exceptional effectiveness in HDL code debugging.
ChatPattern: Layout Pattern Customization via Natural Language
Mar 15, 2024



Existing works focus on fixed-size layout pattern generation, while the more practical free-size pattern generation receives limited attention. In this paper, we propose ChatPattern, a novel Large-Language-Model (LLM) powered framework for flexible pattern customization. ChatPattern utilizes a two-part system featuring an expert LLM agent and a highly controllable layout pattern generator. The LLM agent can interpret natural language requirements and operate design tools to meet specified needs, while the generator excels in conditional layout generation, pattern modification, and memory-friendly patterns extension. Experiments on challenging pattern generation setting shows the ability of ChatPattern to synthesize high-quality large-scale patterns.
p-Laplacian Adaptation for Generative Pre-trained Vision-Language Models
Dec 17, 2023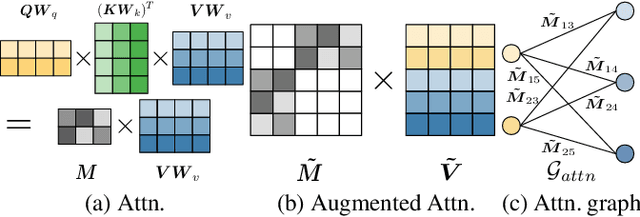



Vision-Language models (VLMs) pre-trained on large corpora have demonstrated notable success across a range of downstream tasks. In light of the rapidly increasing size of pre-trained VLMs, parameter-efficient transfer learning (PETL) has garnered attention as a viable alternative to full fine-tuning. One such approach is the adapter, which introduces a few trainable parameters into the pre-trained models while preserving the original parameters during adaptation. In this paper, we present a novel modeling framework that recasts adapter tuning after attention as a graph message passing process on attention graphs, where the projected query and value features and attention matrix constitute the node features and the graph adjacency matrix, respectively. Within this framework, tuning adapters in VLMs necessitates handling heterophilic graphs, owing to the disparity between the projected query and value space. To address this challenge, we propose a new adapter architecture, $p$-adapter, which employs $p$-Laplacian message passing in Graph Neural Networks (GNNs). Specifically, the attention weights are re-normalized based on the features, and the features are then aggregated using the calibrated attention matrix, enabling the dynamic exploitation of information with varying frequencies in the heterophilic attention graphs. We conduct extensive experiments on different pre-trained VLMs and multi-modal tasks, including visual question answering, visual entailment, and image captioning. The experimental results validate our method's significant superiority over other PETL methods.
ChatEDA: A Large Language Model Powered Autonomous Agent for EDA
Aug 20, 2023The integration of a complex set of Electronic Design Automation (EDA) tools to enhance interoperability is a critical concern for circuit designers. Recent advancements in large language models (LLMs) have showcased their exceptional capabilities in natural language processing and comprehension, offering a novel approach to interfacing with EDA tools. This research paper introduces ChatEDA, an autonomous agent for EDA empowered by a large language model, AutoMage, complemented by EDA tools serving as executors. ChatEDA streamlines the design flow from the Register-Transfer Level (RTL) to the Graphic Data System Version II (GDSII) by effectively managing task planning, script generation, and task execution. Through comprehensive experimental evaluations, ChatEDA has demonstrated its proficiency in handling diverse requirements, and our fine-tuned AutoMage model has exhibited superior performance compared to GPT-4 and other similar LLMs.
AdaOPC: A Self-Adaptive Mask Optimization Framework For Real Design Patterns
Mar 15, 2023Optical proximity correction (OPC) is a widely-used resolution enhancement technique (RET) for printability optimization. Recently, rigorous numerical optimization and fast machine learning are the research focus of OPC in both academia and industry, each of which complements the other in terms of robustness or efficiency. We inspect the pattern distribution on a design layer and find that different sub-regions have different pattern complexity. Besides, we also find that many patterns repetitively appear in the design layout, and these patterns may possibly share optimized masks. We exploit these properties and propose a self-adaptive OPC framework to improve efficiency. Firstly we choose different OPC solvers adaptively for patterns of different complexity from an extensible solver pool to reach a speed/accuracy co-optimization. Apart from that, we prove the feasibility of reusing optimized masks for repeated patterns and hence, build a graph-based dynamic pattern library reusing stored masks to further speed up the OPC flow. Experimental results show that our framework achieves substantial improvement in both performance and efficiency.
Ref-NPR: Reference-Based Non-Photorealistic Radiance Fields
Dec 06, 2022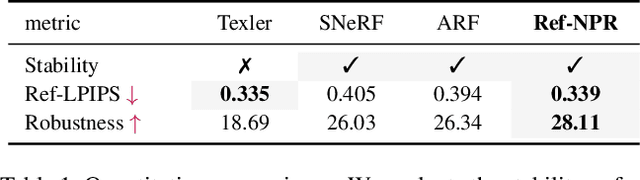
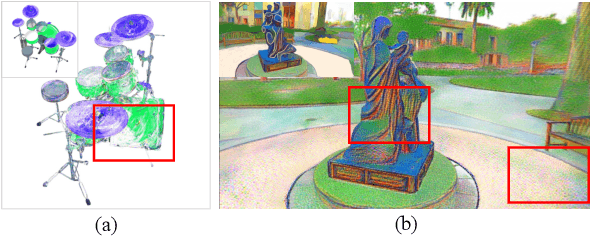
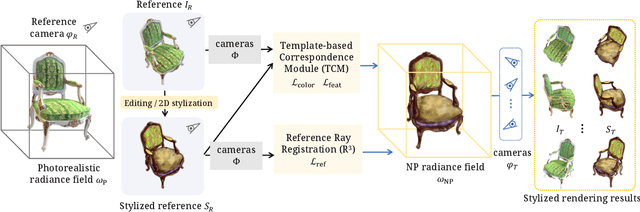
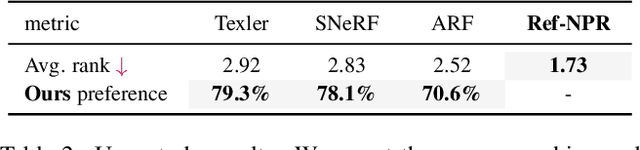
Existing 3D scene stylization methods employ an arbitrary style reference to transfer textures and colors as styles without establishing meaningful semantic correspondences. We present Reference-Based Non-Photorealistic Radiance Fields, i.e., Ref-NPR. It is a controllable scene stylization method utilizing radiance fields to stylize a 3D scene, with a single stylized 2D view taken as reference. To achieve decent results, we propose a ray registration process based on the stylized reference view to obtain pseudo-ray supervision in novel views, and exploit the semantic correspondence in content images to fill occluded regions with perceptually similar styles. Combining these operations, Ref-NPR generates non-photorealistic and continuous novel view sequences with a single reference while obtaining reasonable stylization in occluded regions. Experiments show that Ref-NPR significantly outperforms other scene and video stylization methods in terms of both visual quality and semantic correspondence. Code and data will be made publicly available.