 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow-Your-Creation: Empowering 4D Creation through Video Inpainting
Jun 05, 2025



We introduce Follow-Your-Creation, a novel 4D video creation framework capable of both generating and editing 4D content from a single monocular video input. By leveraging a powerful video inpainting foundation model as a generative prior, we reformulate 4D video creation as a video inpainting task, enabling the model to fill in missing content caused by camera trajectory changes or user edits. To facilitate this, we generate composite masked inpainting video data to effectively fine-tune the model for 4D video generation. Given an input video and its associated camera trajectory, we first perform depth-based point cloud rendering to obtain invisibility masks that indicate the regions that should be completed. Simultaneously, editing masks are introduced to specify user-defined modifications, and these are combined with the invisibility masks to create a composite masks dataset. During training, we randomly sample different types of masks to construct diverse and challenging inpainting scenarios, enhancing the model's generalization and robustness in various 4D editing and generation tasks. To handle temporal consistency under large camera motion, we design a self-iterative tuning strategy that gradually increases the viewing angles during training, where the model is used to generate the next-stage training data after each fine-tuning iteration. Moreover, we introduce a temporal packaging module during inference to enhance generation quality. Our method effectively leverages the prior knowledge of the base model without degrading its original performance, enabling the generation of 4D videos with consistent multi-view coherence. In addition, our approach supports prompt-based content editing, demonstrating strong flexibility and significantly outperforming state-of-the-art methods in both quality and versatility.
Training-Free Efficient Video Generation via Dynamic Token Carving
May 22, 2025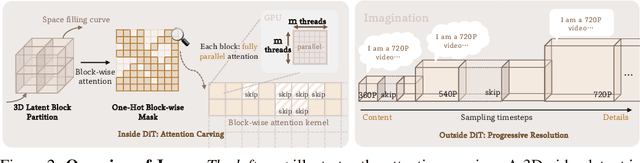
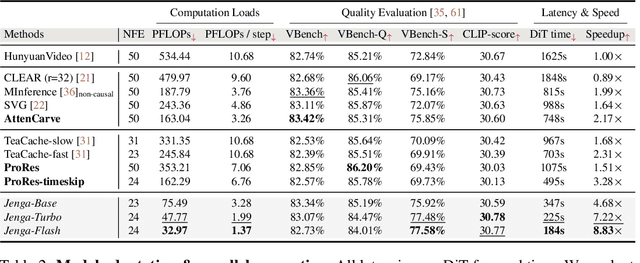
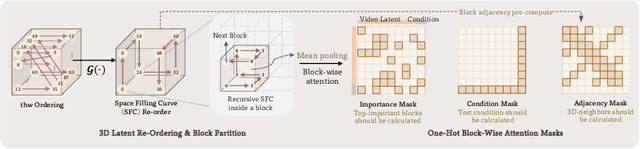
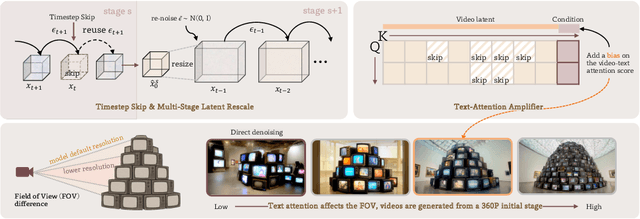
Despite the remarkable generation quality of video Diffusion Transformer (DiT) models, their practical deployment is severely hindered by extensive computational requirements. This inefficiency stems from two key challenges: the quadratic complexity of self-attention with respect to token length and the multi-step nature of diffusion models. To address these limitations, we present Jenga, a novel inference pipeline that combines dynamic attention carving with progressive resolution generation. Our approach leverages two key insights: (1) early denoising steps do not require high-resolution latents, and (2) later steps do not require dense attention. Jenga introduces a block-wise attention mechanism that dynamically selects relevant token interactions using 3D space-filling curves, alongside a progressive resolution strategy that gradually increases latent resolution during generation. Experimental results demonstrate that Jenga achieves substantial speedups across multiple state-of-the-art video diffusion models while maintaining comparable generation quality (8.83$\times$ speedup with 0.01\% performance drop on VBench). As a plug-and-play solution, Jenga enables practical, high-quality video generation on modern hardware by reducing inference time from minutes to seconds -- without requiring model retraining. Code: https://github.com/dvlab-research/Jenga
TrajectoryCrafter: Redirecting Camera Trajectory for Monocular Videos via Diffusion Models
Mar 07, 2025We present TrajectoryCrafter, a novel approach to redirect camera trajectories for monocular videos. By disentangling deterministic view transformations from stochastic content generation, our method achieves precise control over user-specified camera trajectories. We propose a novel dual-stream conditional video diffusion model that concurrently integrates point cloud renders and source videos as conditions, ensuring accurate view transformations and coherent 4D content generation. Instead of leveraging scarce multi-view videos, we curate a hybrid training dataset combining web-scale monocular videos with static multi-view datasets, by our innovative double-reprojection strategy, significantly fostering robust generalization across diverse scenes. Extensive evaluations on multi-view and large-scale monocular videos demonstrate the superior performance of our method.
MotionCanvas: Cinematic Shot Design with Controllable Image-to-Video Generation
Feb 06, 2025



This paper presents a method that allows users to design cinematic video shots in the context of image-to-video generation. Shot design, a critical aspect of filmmaking, involves meticulously planning both camera movements and object motions in a scene. However, enabling intuitive shot design in modern image-to-video generation systems presents two main challenges: first, effectively capturing user intentions on the motion design, where both camera movements and scene-space object motions must be specified jointly; and second, representing motion information that can be effectively utilized by a video diffusion model to synthesize the image animations. To address these challenges, we introduce MotionCanvas, a method that integrates user-driven controls into image-to-video (I2V) generation models, allowing users to control both object and camera motions in a scene-aware manner. By connecting insights from classical computer graphics and contemporary video generation techniques, we demonstrate the ability to achieve 3D-aware motion control in I2V synthesis without requiring costly 3D-related training data. MotionCanvas enables users to intuitively depict scene-space motion intentions, and translates them into spatiotemporal motion-conditioning signals for video diffusion models. We demonstrate the effectiveness of our method on a wide range of real-world image content and shot-design scenarios, highlighting its potential to enhance the creative workflows in digital content creation and adapt to various image and video editing applications.
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Sep 03, 2024



Despite recent advancements in neural 3D reconstruction, the dependence on dense multi-view captures restricts their broader applicability. In this work, we propose \textbf{ViewCrafter}, a novel method for synthesizing high-fidelity novel views of generic scenes from single or sparse images with the prior of video diffusion model. Our method takes advantage of the powerful generation capabilities of video diffusion model and the coarse 3D clues offered by point-based representation to generate high-quality video frames with precise camera pose control. To further enlarge the generation range of novel views, we tailored an iterative view synthesis strategy together with a camera trajectory planning algorithm to progressively extend the 3D clues and the areas covered by the novel views. With ViewCrafter, we can facilitate various applications, such as immersive experiences with real-time rendering by efficiently optimizing a 3D-GS representation using the reconstructed 3D points and the generated novel views, and scene-level text-to-3D generation for more imaginative content creation. Extensive experiments on diverse datasets demonstrate the strong generalization capability and superior performance of our method in synthesizing high-fidelity and consistent novel views.
ToonCrafter: Generative Cartoon Interpolation
May 28, 2024



We introduce ToonCrafter, a novel approach that transcends traditional correspondence-based cartoon video interpolation, paving the way for generative interpolation. Traditional methods, that implicitly assume linear motion and the absence of complicated phenomena like dis-occlusion, often struggle with the exaggerated non-linear and large motions with occlusion commonly found in cartoons, resulting in implausible or even failed interpolation results. To overcome these limitations, we explore the potential of adapting live-action video priors to better suit cartoon interpolation within a generative framework. ToonCrafter effectively addresses the challenges faced when applying live-action video motion priors to generative cartoon interpolation. First, we design a toon rectification learning strategy that seamlessly adapts live-action video priors to the cartoon domain, resolving the domain gap and content leakage issues. Next, we introduce a dual-reference-based 3D decoder to compensate for lost details due to the highly compressed latent prior spaces, ensuring the preservation of fine details in interpolation results. Finally, we design a flexible sketch encoder that empowers users with interactive control over the interpolation results. Experimental results demonstrate that our proposed method not only produces visually convincing and more natural dynamics, but also effectively handles dis-occlusion. The comparative evaluation demonstrates the notable superiority of our approach over existing competitors.
StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
Dec 01, 2023



Text-to-video (T2V) models have shown remarkable capabilities in generating diverse videos. However, they struggle to produce user-desired stylized videos due to (i) text's inherent clumsiness in expressing specific styles and (ii) the generally degraded style fidelity. To address these challenges, we introduce StyleCrafter, a generic method that enhances pre-trained T2V models with a style control adapter, enabling video generation in any style by providing a reference image. Considering the scarcity of stylized video datasets, we propose to first train a style control adapter using style-rich image datasets, then transfer the learned stylization ability to video generation through a tailor-made finetuning paradigm. To promote content-style disentanglement, we remove style descriptions from the text prompt and extract style information solely from the reference image using a decoupling learning strategy. Additionally, we design a scale-adaptive fusion module to balance the influences of text-based content features and image-based style features, which helps generalization across various text and style combinations. StyleCrafter efficiently generates high-quality stylized videos that align with the content of the texts and resemble the style of the reference images. Experiments demonstrate that our approach is more flexible and efficient than existing competitors.
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Oct 30, 2023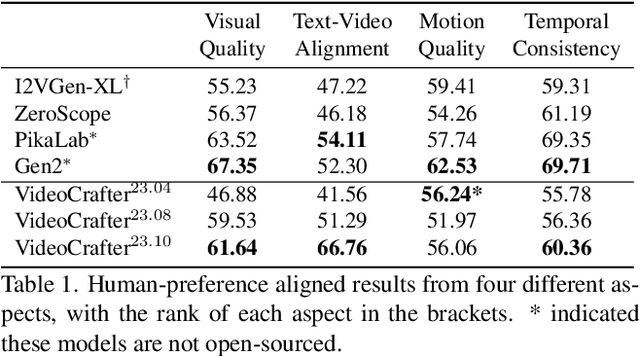

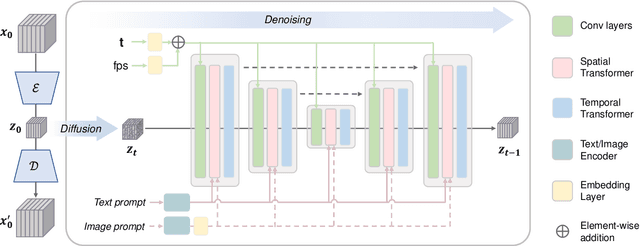
Video generation has increasingly gained interest in both academia and industry. Although commercial tools can generate plausible videos, there is a limited number of open-source models available for researchers and engineers. In this work, we introduce two diffusion models for high-quality video generation, namely text-to-video (T2V) and image-to-video (I2V) models. T2V models synthesize a video based on a given text input, while I2V models incorporate an additional image input. Our proposed T2V model can generate realistic and cinematic-quality videos with a resolution of $1024 \times 576$, outperforming other open-source T2V models in terms of quality. The I2V model is designed to produce videos that strictly adhere to the content of the provided reference image, preserving its content, structure, and style. This model is the first open-source I2V foundation model capable of transforming a given image into a video clip while maintaining content preservation constraints. We believe that these open-source video generation models will contribute significantly to the technological advancements within the community.
DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors
Oct 18, 2023
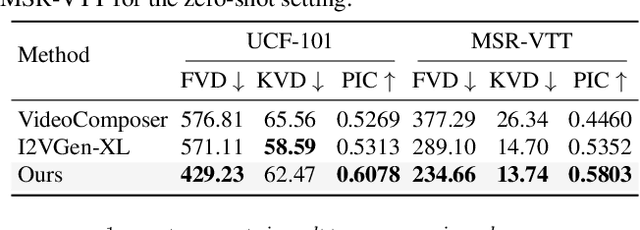
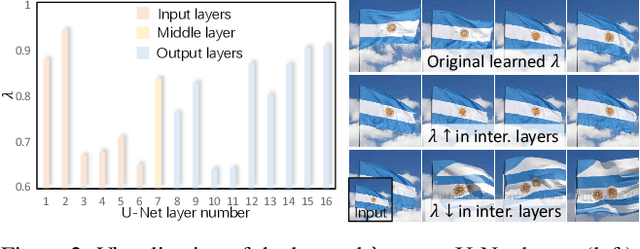

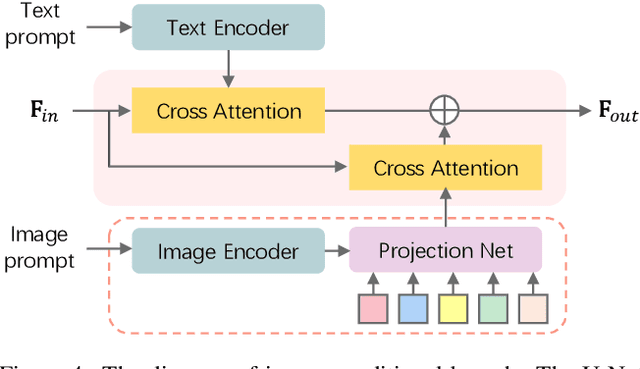
Enhancing a still image with motion offers more engaged visual experience. Traditional image animation techniques mainly focus on animating natural scenes with random dynamics, such as clouds and fluid, and thus limits their applicability to generic visual contents. To overcome this limitation, we explore the synthesis of dynamic content for open-domain images, converting them into animated videos. The key idea is to utilize the motion prior of text-to-video diffusion models by incorporating the image into the generative process as guidance. Given an image, we first project it into a text-aligned rich image embedding space using a learnable image encoding network, which facilitates the video model to digest the image content compatibly. However, some visual details still struggle to be preserved in the resulting videos. To supplement more precise image information, we further feed the full image to the diffusion model by concatenating it with the initial noises. Experimental results reveal that our proposed method produces visually convincing animated videos, exhibiting both natural motions and high fidelity to the input image. Comparative evaluation demonstrates the notable superiority of our approach over existing competitors. The source code will be released upon publication.
Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation
Jul 13, 2023



Generating videos for visual storytelling can be a tedious and complex process that typically requires either live-action filming or graphics animation rendering. To bypass these challenges, our key idea is to utilize the abundance of existing video clips and synthesize a coherent storytelling video by customizing their appearances. We achieve this by developing a framework comprised of two functional modules: (i) Motion Structure Retrieval, which provides video candidates with desired scene or motion context described by query texts, and (ii) Structure-Guided Text-to-Video Synthesis, which generates plot-aligned videos under the guidance of motion structure and text prompts. For the first module, we leverage an off-the-shelf video retrieval system and extract video depths as motion structure. For the second module, we propose a controllable video generation model that offers flexible controls over structure and characters. The videos are synthesized by following the structural guidance and appearance instruction. To ensure visual consistency across clips, we propose an effective concept personalization approach, which allows the specification of the desired character identities through text prompts. Extensive experiments demonstrate that our approach exhibits significant advantages over various existing baselines.