 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Paper and Code
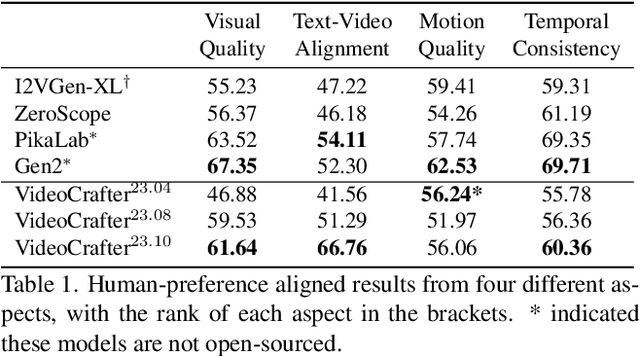

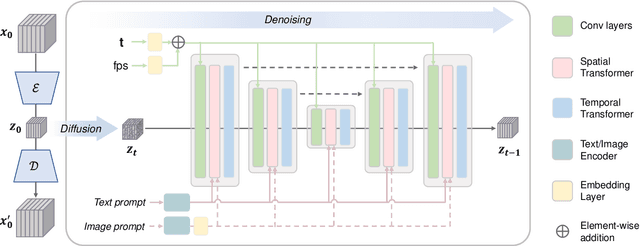
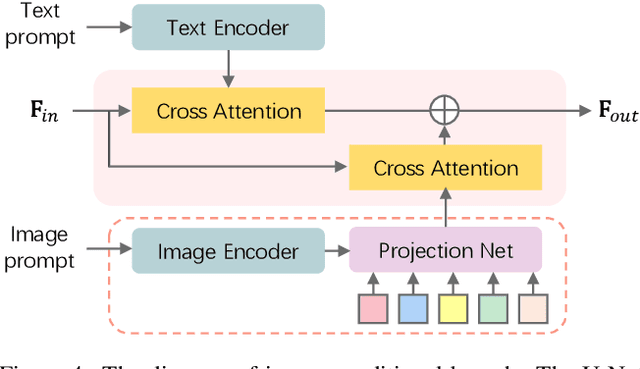
Video generation has increasingly gained interest in both academia and industry. Although commercial tools can generate plausible videos, there is a limited number of open-source models available for researchers and engineers. In this work, we introduce two diffusion models for high-quality video generation, namely text-to-video (T2V) and image-to-video (I2V) models. T2V models synthesize a video based on a given text input, while I2V models incorporate an additional image input. Our proposed T2V model can generate realistic and cinematic-quality videos with a resolution of $1024 \times 576$, outperforming other open-source T2V models in terms of quality. The I2V model is designed to produce videos that strictly adhere to the content of the provided reference image, preserving its content, structure, and style. This model is the first open-source I2V foundation model capable of transforming a given image into a video clip while maintaining content preservation constraints. We believe that these open-source video generation models will contribute significantly to the technological advancements within the community.