 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiniteTalk: Audio-driven Video Generation for Sparse-Frame Video Dubbing
Aug 19, 2025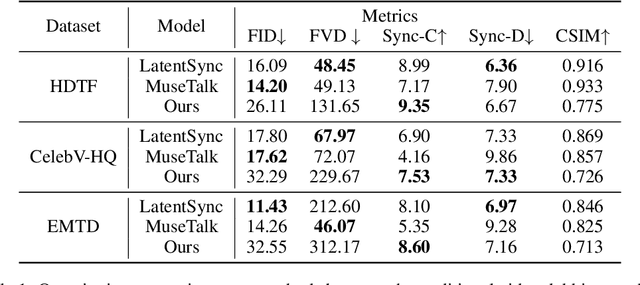

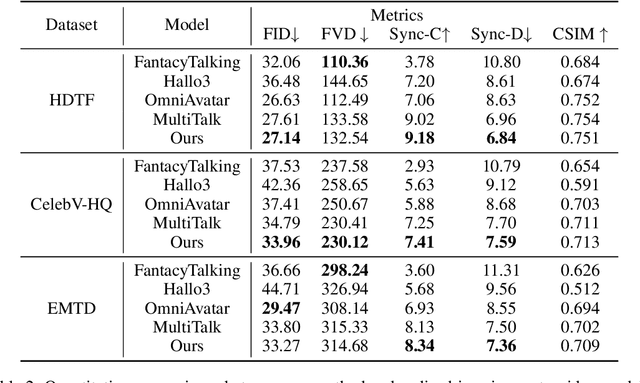
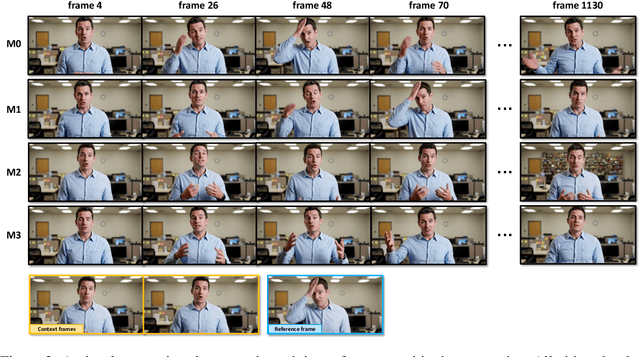
Recent breakthroughs in video AIGC have ushered in a transformative era for audio-driven human animation. However, conventional video dubbing techniques remain constrained to mouth region editing, resulting in discordant facial expressions and body gestures that compromise viewer immersion. To overcome this limitation, we introduce sparse-frame video dubbing, a novel paradigm that strategically preserves reference keyframes to maintain identity, iconic gestures, and camera trajectories while enabling holistic, audio-synchronized full-body motion editing. Through critical analysis, we identify why naive image-to-video models fail in this task, particularly their inability to achieve adaptive conditioning. Addressing this, we propose InfiniteTalk, a streaming audio-driven generator designed for infinite-length long sequence dubbing. This architecture leverages temporal context frames for seamless inter-chunk transitions and incorporates a simple yet effective sampling strategy that optimizes control strength via fine-grained reference frame positioning. Comprehensive evaluations on HDTF, CelebV-HQ, and EMTD datasets demonstrate state-of-the-art performance. Quantitative metrics confirm superior visual realism, emotional coherence, and full-body motion synchronization.
DAM-VSR: Disentanglement of Appearance and Motion for Video Super-Resolution
Jul 01, 2025


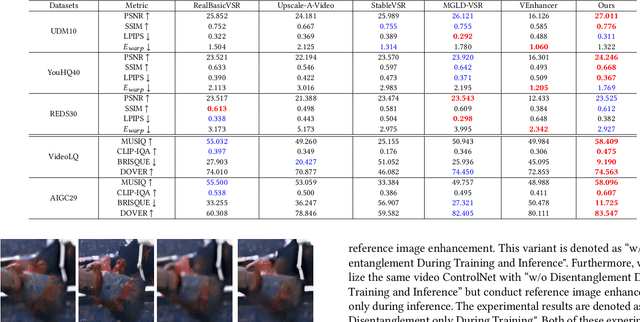
Real-world video super-resolution (VSR) presents significant challenges due to complex and unpredictable degradations. Although some recent methods utilize image diffusion models for VSR and have shown improved detail generation capabilities, they still struggle to produce temporally consistent frames. We attempt to use Stable Video Diffusion (SVD) combined with ControlNet to address this issue. However, due to the intrinsic image-animation characteristics of SVD, it is challenging to generate fine details using only low-quality videos. To tackle this problem, we propose DAM-VSR, an appearance and motion disentanglement framework for VSR. This framework disentangles VSR into appearance enhancement and motion control problems. Specifically, appearance enhancement is achieved through reference image super-resolution, while motion control is achieved through video ControlNet. This disentanglement fully leverages the generative prior of video diffusion models and the detail generation capabilities of image super-resolution models. Furthermore, equipped with the proposed motion-aligned bidirectional sampling strategy, DAM-VSR can conduct VSR on longer input videos. DAM-VSR achieves state-of-the-art performance on real-world data and AIGC data, demonstrating its powerful detail generation capabilities.
ZeroSmooth: Training-free Diffuser Adaptation for High Frame Rate Video Generation
Jun 03, 2024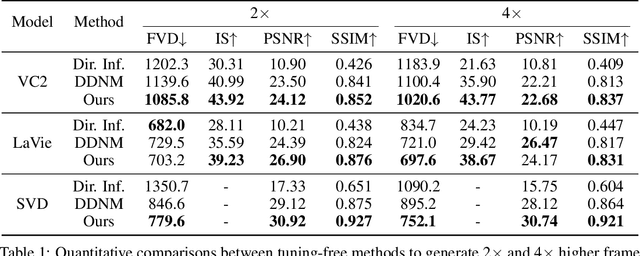
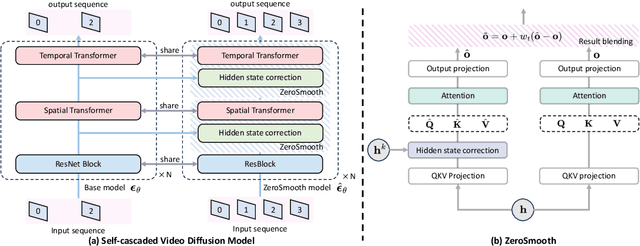

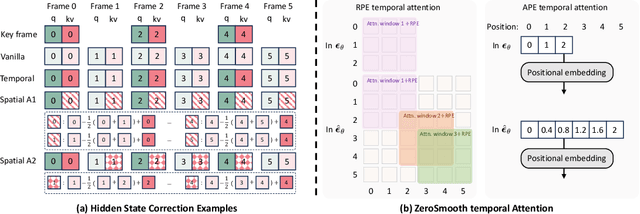
Video generation has made remarkable progress in recent years, especially since the advent of the video diffusion models. Many video generation models can produce plausible synthetic videos, e.g., Stable Video Diffusion (SVD). However, most video models can only generate low frame rate videos due to the limited GPU memory as well as the difficulty of modeling a large set of frames. The training videos are always uniformly sampled at a specified interval for temporal compression. Previous methods promote the frame rate by either training a video interpolation model in pixel space as a postprocessing stage or training an interpolation model in latent space for a specific base video model. In this paper, we propose a training-free video interpolation method for generative video diffusion models, which is generalizable to different models in a plug-and-play manner. We investigate the non-linearity in the feature space of video diffusion models and transform a video model into a self-cascaded video diffusion model with incorporating the designed hidden state correction modules. The self-cascaded architecture and the correction module are proposed to retain the temporal consistency between key frames and the interpolated frames. Extensive evaluations are preformed on multiple popular video models to demonstrate the effectiveness of the propose method, especially that our training-free method is even comparable to trained interpolation models supported by huge compute resources and large-scale datasets.
CV-VAE: A Compatible Video VAE for Latent Generative Video Models
May 30, 2024Spatio-temporal compression of videos, utilizing networks such as Variational Autoencoders (VAE), plays a crucial role in OpenAI's SORA and numerous other video generative models. For instance, many LLM-like video models learn the distribution of discrete tokens derived from 3D VAEs within the VQVAE framework, while most diffusion-based video models capture the distribution of continuous latent extracted by 2D VAEs without quantization. The temporal compression is simply realized by uniform frame sampling which results in unsmooth motion between consecutive frames. Currently, there lacks of a commonly used continuous video (3D) VAE for latent diffusion-based video models in the research community. Moreover, since current diffusion-based approaches are often implemented using pre-trained text-to-image (T2I) models, directly training a video VAE without considering the compatibility with existing T2I models will result in a latent space gap between them, which will take huge computational resources for training to bridge the gap even with the T2I models as initialization. To address this issue, we propose a method for training a video VAE of latent video models, namely CV-VAE, whose latent space is compatible with that of a given image VAE, e.g., image VAE of Stable Diffusion (SD). The compatibility is achieved by the proposed novel latent space regularization, which involves formulating a regularization loss using the image VAE. Benefiting from the latent space compatibility, video models can be trained seamlessly from pre-trained T2I or video models in a truly spatio-temporally compressed latent space, rather than simply sampling video frames at equal intervals. With our CV-VAE, existing video models can generate four times more frames with minimal finetuning. Extensive experiments are conducted to demonstrate the effectiveness of the proposed video VAE.
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Oct 30, 2023

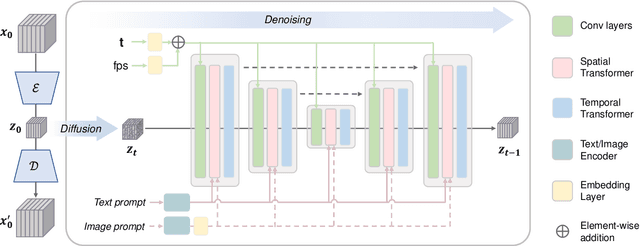
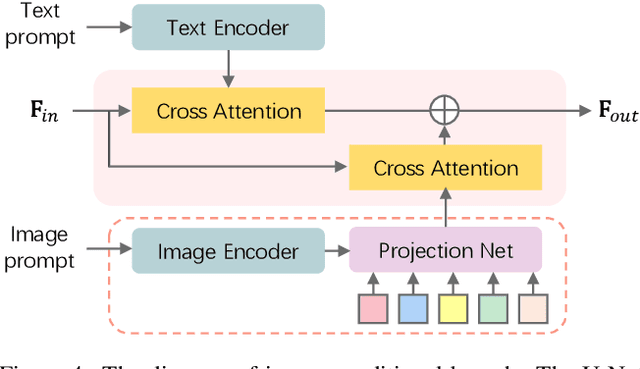
Video generation has increasingly gained interest in both academia and industry. Although commercial tools can generate plausible videos, there is a limited number of open-source models available for researchers and engineers. In this work, we introduce two diffusion models for high-quality video generation, namely text-to-video (T2V) and image-to-video (I2V) models. T2V models synthesize a video based on a given text input, while I2V models incorporate an additional image input. Our proposed T2V model can generate realistic and cinematic-quality videos with a resolution of $1024 \times 576$, outperforming other open-source T2V models in terms of quality. The I2V model is designed to produce videos that strictly adhere to the content of the provided reference image, preserving its content, structure, and style. This model is the first open-source I2V foundation model capable of transforming a given image into a video clip while maintaining content preservation constraints. We believe that these open-source video generation models will contribute significantly to the technological advancements within the community.
ScaleCrafter: Tuning-free Higher-Resolution Visual Generation with Diffusion Models
Oct 11, 2023
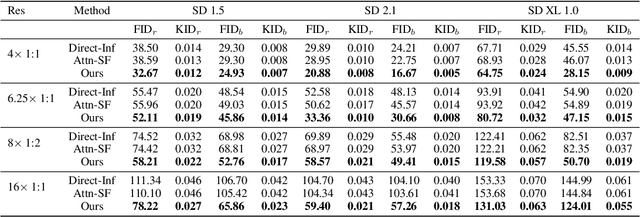


In this work, we investigate the capability of generating images from pre-trained diffusion models at much higher resolutions than the training image sizes. In addition, the generated images should have arbitrary image aspect ratios. When generating images directly at a higher resolution, 1024 x 1024, with the pre-trained Stable Diffusion using training images of resolution 512 x 512, we observe persistent problems of object repetition and unreasonable object structures. Existing works for higher-resolution generation, such as attention-based and joint-diffusion approaches, cannot well address these issues. As a new perspective, we examine the structural components of the U-Net in diffusion models and identify the crucial cause as the limited perception field of convolutional kernels. Based on this key observation, we propose a simple yet effective re-dilation that can dynamically adjust the convolutional perception field during inference. We further propose the dispersed convolution and noise-damped classifier-free guidance, which can enable ultra-high-resolution image generation (e.g., 4096 x 4096). Notably, our approach does not require any training or optimization. Extensive experiments demonstrate that our approach can address the repetition issue well and achieve state-of-the-art performance on higher-resolution image synthesis, especially in texture details. Our work also suggests that a pre-trained diffusion model trained on low-resolution images can be directly used for high-resolution visual generation without further tuning, which may provide insights for future research on ultra-high-resolution image and video synthesis.