 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork Alignment
Apr 15, 2025Complex networks are frequently employed to model physical or virtual complex systems. When certain entities exist across multiple systems simultaneously, unveiling their corresponding relationships across the networks becomes crucial. This problem, known as network alignment, holds significant importance. It enhances our understanding of complex system structures and behaviours, facilitates the validation and extension of theoretical physics research about studying complex systems, and fosters diverse practical applications across various fields. However, due to variations in the structure, characteristics, and properties of complex networks across different fields, the study of network alignment is often isolated within each domain, with even the terminologies and concepts lacking uniformity. This review comprehensively summarizes the latest advancements in network alignment research, focusing on analyzing network alignment characteristics and progress in various domains such as social network analysis, bioinformatics, computational linguistics and privacy protection. It provides a detailed analysis of various methods' implementation principles, processes, and performance differences, including structure consistency-based methods, network embedding-based methods, and graph neural network-based (GNN-based) methods. Additionally, the methods for network alignment under different conditions, such as in attributed networks, heterogeneous networks, directed networks, and dynamic networks, are presented. Furthermore, the challenges and the open issues for future studies are also discussed.
EGP3D: Edge-guided Geometric Preserving 3D Point Cloud Super-resolution for RGB-D camera
Dec 16, 2024



Point clouds or depth images captured by current RGB-D cameras often suffer from low resolution, rendering them insufficient for applications such as 3D reconstruction and robots. Existing point cloud super-resolution (PCSR) methods are either constrained by geometric artifacts or lack attention to edge details. To address these issues, we propose an edge-guided geometric-preserving 3D point cloud super-resolution (EGP3D) method tailored for RGB-D cameras. Our approach innovatively optimizes the point cloud with an edge constraint on a projected 2D space, thereby ensuring high-quality edge preservation in the 3D PCSR task. To tackle geometric optimization challenges in super-resolution point clouds, particularly preserving edge shapes and smoothness, we introduce a multi-faceted loss function that simultaneously optimizes the Chamfer distance, Hausdorff distance, and gradient smoothness. Existing datasets used for point cloud upsampling are predominantly synthetic and inadequately represent real-world scenarios, neglecting noise and stray light effects. To address the scarcity of realistic RGB-D data for PCSR tasks, we built a dataset that captures real-world noise and stray-light effects, offering a more accurate representation of authentic environments. Validated through simulations and real-world experiments, the proposed method exhibited superior performance in preserving edge clarity and geometric details.
Super-resolving Real-world Image Illumination Enhancement: A New Dataset and A Conditional Diffusion Model
Oct 16, 2024



Most existing super-resolution methods and datasets have been developed to improve the image quality in well-lighted conditions. However, these methods do not work well in real-world low-light conditions as the images captured in such conditions lose most important information and contain significant unknown noises. To solve this problem, we propose a SRRIIE dataset with an efficient conditional diffusion probabilistic models-based method. The proposed dataset contains 4800 paired low-high quality images. To ensure that the dataset are able to model the real-world image degradation in low-illumination environments, we capture images using an ILDC camera and an optical zoom lens with exposure levels ranging from -6 EV to 0 EV and ISO levels ranging from 50 to 12800. We comprehensively evaluate with various reconstruction and perceptual metrics and demonstrate the practicabilities of the SRRIIE dataset for deep learning-based methods. We show that most existing methods are less effective in preserving the structures and sharpness of restored images from complicated noises. To overcome this problem, we revise the condition for Raw sensor data and propose a novel time-melding condition for diffusion probabilistic model. Comprehensive quantitative and qualitative experimental results on the real-world benchmark datasets demonstrate the feasibility and effectivenesses of the proposed conditional diffusion probabilistic model on Raw sensor data. Code and dataset will be available at https://github.com/Yaofang-Liu/Super-Resolving
Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach
Oct 04, 2024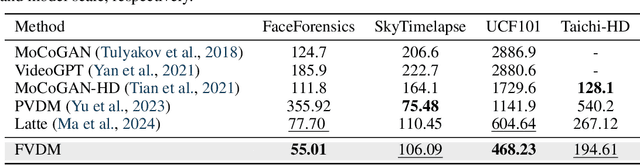
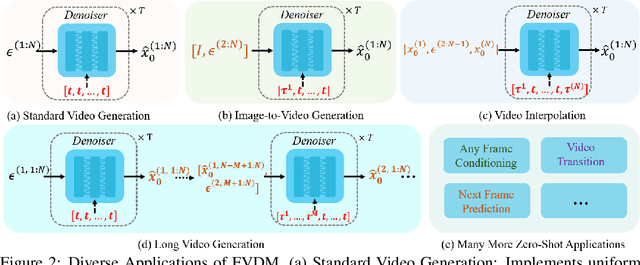
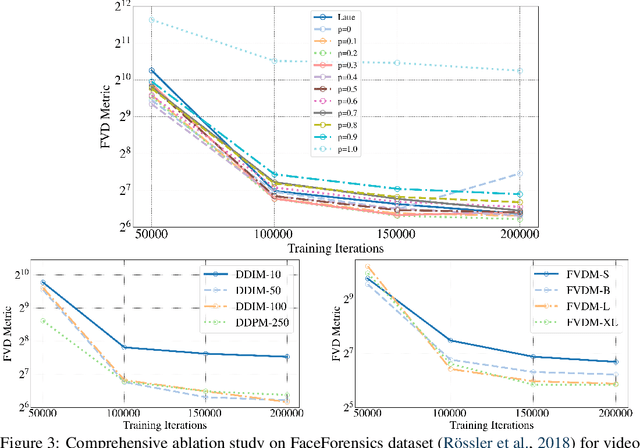

Diffusion models have revolutionized image generation, and their extension to video generation has shown promise. However, current video diffusion models~(VDMs) rely on a scalar timestep variable applied at the clip level, which limits their ability to model complex temporal dependencies needed for various tasks like image-to-video generation. To address this limitation, we propose a frame-aware video diffusion model~(FVDM), which introduces a novel vectorized timestep variable~(VTV). Unlike conventional VDMs, our approach allows each frame to follow an independent noise schedule, enhancing the model's capacity to capture fine-grained temporal dependencies. FVDM's flexibility is demonstrated across multiple tasks, including standard video generation, image-to-video generation, video interpolation, and long video synthesis. Through a diverse set of VTV configurations, we achieve superior quality in generated videos, overcoming challenges such as catastrophic forgetting during fine-tuning and limited generalizability in zero-shot methods.Our empirical evaluations show that FVDM outperforms state-of-the-art methods in video generation quality, while also excelling in extended tasks. By addressing fundamental shortcomings in existing VDMs, FVDM sets a new paradigm in video synthesis, offering a robust framework with significant implications for generative modeling and multimedia applications.
VJT: A Video Transformer on Joint Tasks of Deblurring, Low-light Enhancement and Denoising
Jan 26, 2024Video restoration task aims to recover high-quality videos from low-quality observations. This contains various important sub-tasks, such as video denoising, deblurring and low-light enhancement, since video often faces different types of degradation, such as blur, low light, and noise. Even worse, these kinds of degradation could happen simultaneously when taking videos in extreme environments. This poses significant challenges if one wants to remove these artifacts at the same time. In this paper, to the best of our knowledge, we are the first to propose an efficient end-to-end video transformer approach for the joint task of video deblurring, low-light enhancement, and denoising. This work builds a novel multi-tier transformer where each tier uses a different level of degraded video as a target to learn the features of video effectively. Moreover, we carefully design a new tier-to-tier feature fusion scheme to learn video features incrementally and accelerate the training process with a suitable adaptive weighting scheme. We also provide a new Multiscene-Lowlight-Blur-Noise (MLBN) dataset, which is generated according to the characteristics of the joint task based on the RealBlur dataset and YouTube videos to simulate realistic scenes as far as possible. We have conducted extensive experiments, compared with many previous state-of-the-art methods, to show the effectiveness of our approach clearly.
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Oct 30, 2023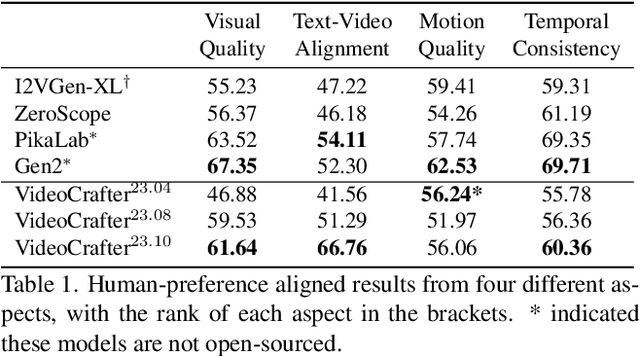

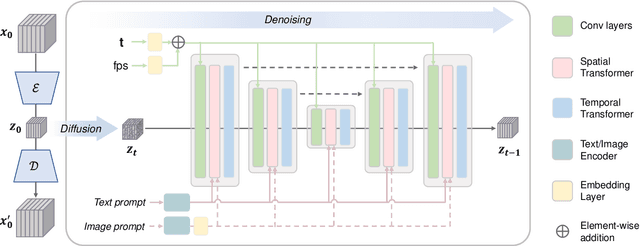
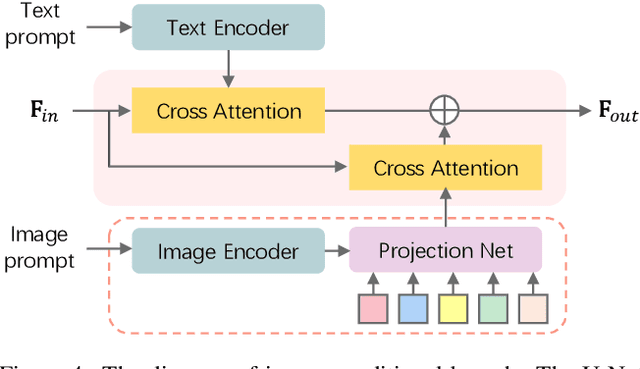
Video generation has increasingly gained interest in both academia and industry. Although commercial tools can generate plausible videos, there is a limited number of open-source models available for researchers and engineers. In this work, we introduce two diffusion models for high-quality video generation, namely text-to-video (T2V) and image-to-video (I2V) models. T2V models synthesize a video based on a given text input, while I2V models incorporate an additional image input. Our proposed T2V model can generate realistic and cinematic-quality videos with a resolution of $1024 \times 576$, outperforming other open-source T2V models in terms of quality. The I2V model is designed to produce videos that strictly adhere to the content of the provided reference image, preserving its content, structure, and style. This model is the first open-source I2V foundation model capable of transforming a given image into a video clip while maintaining content preservation constraints. We believe that these open-source video generation models will contribute significantly to the technological advancements within the community.
EvalCrafter: Benchmarking and Evaluating Large Video Generation Models
Oct 18, 2023
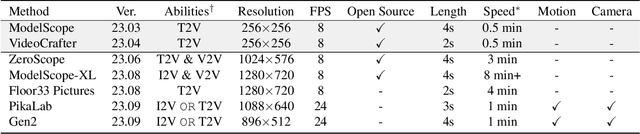

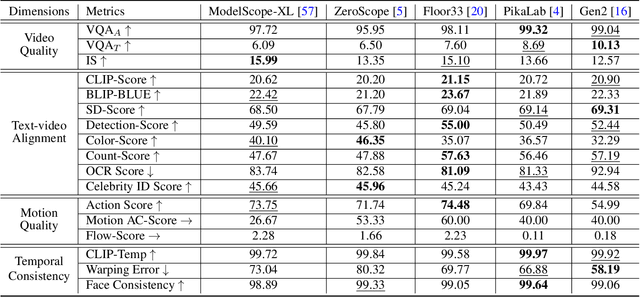
The vision and language generative models have been overgrown in recent years. For video generation, various open-sourced models and public-available services are released for generating high-visual quality videos. However, these methods often use a few academic metrics, for example, FVD or IS, to evaluate the performance. We argue that it is hard to judge the large conditional generative models from the simple metrics since these models are often trained on very large datasets with multi-aspect abilities. Thus, we propose a new framework and pipeline to exhaustively evaluate the performance of the generated videos. To achieve this, we first conduct a new prompt list for text-to-video generation by analyzing the real-world prompt list with the help of the large language model. Then, we evaluate the state-of-the-art video generative models on our carefully designed benchmarks, in terms of visual qualities, content qualities, motion qualities, and text-caption alignment with around 18 objective metrics. To obtain the final leaderboard of the models, we also fit a series of coefficients to align the objective metrics to the users' opinions. Based on the proposed opinion alignment method, our final score shows a higher correlation than simply averaging the metrics, showing the effectiveness of the proposed evaluation method.
Dual-View Selective Instance Segmentation Network for Unstained Live Adherent Cells in Differential Interference Contrast Images
Jan 27, 2023



Despite recent advances in data-independent and deep-learning algorithms, unstained live adherent cell instance segmentation remains a long-standing challenge in cell image processing. Adherent cells' inherent visual characteristics, such as low contrast structures, fading edges, and irregular morphology, have made it difficult to distinguish from one another, even by human experts, let alone computational methods. In this study, we developed a novel deep-learning algorithm called dual-view selective instance segmentation network (DVSISN) for segmenting unstained adherent cells in differential interference contrast (DIC) images. First, we used a dual-view segmentation (DVS) method with pairs of original and rotated images to predict the bounding box and its corresponding mask for each cell instance. Second, we used a mask selection (MS) method to filter the cell instances predicted by the DVS to keep masks closest to the ground truth only. The developed algorithm was trained and validated on our dataset containing 520 images and 12198 cells. Experimental results demonstrate that our algorithm achieves an AP_segm of 0.555, which remarkably overtakes a benchmark by a margin of 23.6%. This study's success opens up a new possibility of using rotated images as input for better prediction in cell images.
Two New Stenosis Detection Methods of Coronary Angiograms
Dec 14, 2021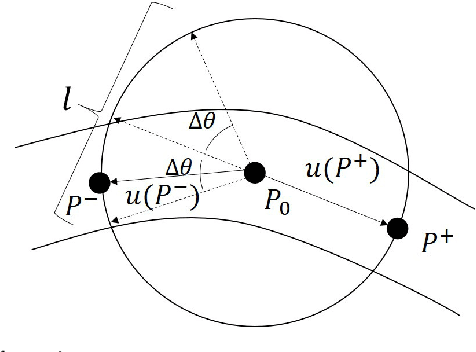
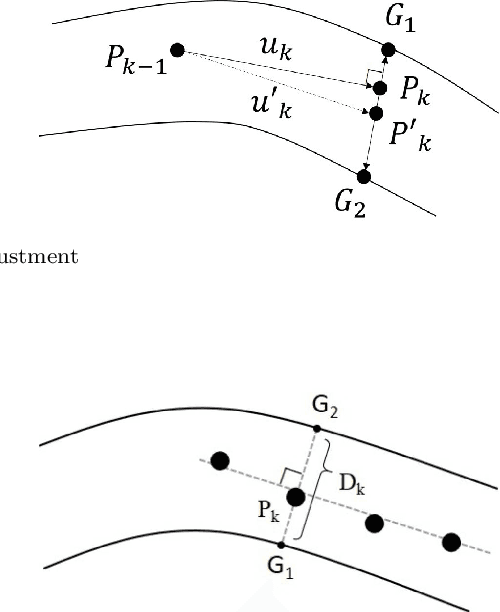
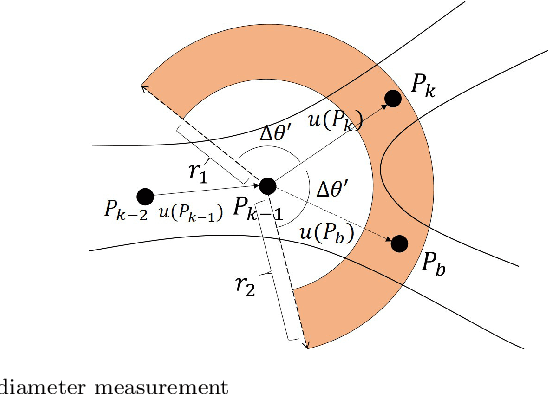
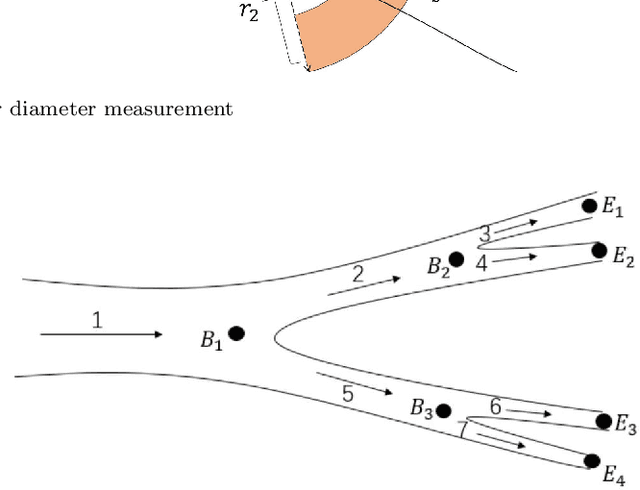
Coronary angiography is the "gold standard" for diagnosing coronary artery disease (CAD). At present, the methods for detecting and evaluating coronary artery stenosis cannot satisfy the clinical needs, e.g., there is no prior study of detecting stenoses in prespecified vessel segments, which is necessary in clinical practice. Two vascular stenosis detection methods are proposed to assist the diagnosis. The first one is an automatic method, which can automatically extract the entire coronary artery tree and mark all the possible stenoses. The second one is an interactive method. With this method, the user can choose any vessel segment to do further analysis of its stenoses. Experiments show that the proposed methods are robust for angiograms with various vessel structures. The precision, sensitivity, and $F_1$ score of the automatic stenosis detection method are 0.821, 0.757, and 0.788, respectively. Further investigation proves that the interactive method can provide a more precise outcome of stenosis detection, and our quantitative analysis is closer to reality. The proposed automatic method and interactive method are effective and can complement each other in clinical practice. The first method can be used for preliminary screening, and the second method can be used for further quantitative analysis. We believe the proposed solution is more suitable for the clinical diagnosis of CAD.
Two New Stenoses Detection Methods of Coronary Angiograms
Aug 03, 2021Coronary angiography is the "gold standard" for the diagnosis of coronary heart disease. At present, the methods for detecting coronary artery stenoses and evaluating the degree of it in coronary angiograms are either subjective or not efficient enough. Two vascular stenoses detection methods in coronary angiograms are proposed to assist the diagnosis. The first one is an automatic method, which can automatically segment the entire coronary vessels and mark the stenoses. The second one is an interactive method. With this method, the user only needs to give a start point and an end point to detect the stenoses of a certain vascular segment. We have shown that the proposed tracking methods are robust for angiograms with various vessel structure. The automatic detection method can effectively measure the diameter of the vessel and mark the stenoses in different angiograms. Further investigation proves that the results of interactive detection method can accurately reflect the true stenoses situation. The proposed automatic method and interactive method are effective in various angiograms and can complement each other in clinical practice. The first method can be used for preliminary screening and the second method can be used for further quantitative analysis. It has the potential to improve the level of clinical diagnosis of coronary heart disease.