 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow the TRACE: Exploiting Post-Click Trajectories for Online Delayed Conversion Rate Prediction
Apr 25, 2026Delayed feedback poses a core challenge for online CVR prediction, forcing a trade-off between label accuracy and data freshness. Existing methods address this through delay modeling or sample reweighting, yet neglect how post-click behaviors evolve over the observation period. To overcome this limitation, we formalize this evolution as feedback trajectory and propose TRACE. Instead of forcing hard labels on unrevealed samples, our method evaluates how well the accumulated feedback status aligns with conversion versus non-conversion, dynamically refining posteriors without waiting for final outcomes. To counteract early-stage trajectory sparsity, we further design a reliability-gated retrospective completer that leverages full-lifecycle data to provide adaptive posterior guidance for unrevealed samples. Extensive experiments validate TRACE's superiority over state-of-the-art baselines and confirm the retrospective completion module as a model-agnostic enhancer for existing systems. Our code is available at https://github.com/LunaZhangxy/TRACE.
How Do LLMs and VLMs Understand Viewpoint Rotation Without Vision? An Interpretability Study
Apr 16, 2026Over the past year, spatial intelligence has drawn increasing attention. Many prior works study it from the perspective of visual-spatial intelligence, where models have access to visuospatial information from visual inputs. However, in the absence of visual information, whether linguistic intelligence alone is sufficient to endow models with spatial intelligence, and how models perform relevant tasks with text-only inputs still remain unexplored. Therefore, in this paper, we focus on a fundamental and critical capability in spatial intelligence from a linguistic perspective: viewpoint rotation understanding (VRU). Specifically, LLMs and VLMs are asked to infer their final viewpoint and predict the corresponding observation in an environment given textual description of viewpoint rotation and observation over multiple steps. We find that both LLMs and VLMs perform poorly on our proposed dataset while human can easily achieve 100% accuracy, indicating a substantial gap between current model capabilities and the requirements of spatial intelligence. To uncover the underlying mechanisms, we conduct a layer-wise probing analysis and head-wise causal intervention. Our findings reveal that although models encode viewpoint information in the hidden states, they appear to struggle to bind the viewpoint position with corresponding observation, resulting in a hallucination in final layers. Finally, we selectively fine-tune the key attention heads identified by causal intervention to improve VRU performance. Experimental results demonstrate that such selective fine-tuning achieves improved VRU performance while avoiding catastrophic forgetting of generic abilities. Our dataset and code will be released at https://github.com/Young-Zhen/VRU_Interpret .
Global Truncated Loss Minimization for Robust and Threshold-Resilient Geometric Estimation
Mar 16, 2026To achieve outlier-robust geometric estimation, robust objective functions are generally employed to mitigate the influence of outliers. The widely used consensus maximization(CM) is highly robust when paired with global branch-and-bound(BnB) search. However, CM relies solely on inlier counts and is sensitive to the inlier threshold. Besides, the discrete nature of CM leads to loose bounds, necessitating extensive BnB iterations and computation cost. Truncated losses(TL), another continuous alternative, leverage residual information more effectively and could potentially overcome these issues. But to our knowledge, no prior work has systematically explored globally minimizing TL with BnB and its potential for enhanced threshold resilience or search efficiency. In this work, we propose GTM, the first unified BnB-based framework for globally-optimal TL loss minimization across diverse geometric problems. GTM involves a hybrid solving design: given an n-dimensional problem, it performs BnB search over an (n-1)-dimensional subspace while the remaining 1D variable is solved by bounding the objective function. Our hybrid design not only reduces the search space, but also enables us to derive Lipschitz-continuous bounding functions that are general, tight, and can be efficiently solved by a classic global Lipschitz solver named DIRECT, which brings further acceleration. We conduct a systematic evaluation on various BnB-based methods for CM and TL on the robust linear regression problem, showing that GTM enjoys remarkable threshold resilience and the highest efficiency compared to baseline methods. Furthermore, we apply GTM on different geometric estimation problems with diverse residual forms. Extensive experiments demonstrate that GTM achieves state-of-the-art outlier-robustness and threshold-resilience while maintaining high efficiency across these estimation tasks.
The Struggle Between Continuation and Refusal: A Mechanistic Analysis of the Continuation-Triggered Jailbreak in LLMs
Mar 09, 2026With the rapid advancement of large language models (LLMs), the safety of LLMs has become a critical concern. Despite significant efforts in safety alignment, current LLMs remain vulnerable to jailbreaking attacks. However, the root causes of such vulnerabilities are still poorly understood, necessitating a rigorous investigation into jailbreak mechanisms across both academic and industrial communities. In this work, we focus on a continuation-triggered jailbreak phenomenon, whereby simply relocating a continuation-triggered instruction suffix can substantially increase jailbreak success rates. To uncover the intrinsic mechanisms of this phenomenon, we conduct a comprehensive mechanistic interpretability analysis at the level of attention heads. Through causal interventions and activation scaling, we show that this jailbreak behavior primarily arises from an inherent competition between the model's intrinsic continuation drive and the safety defenses acquired through alignment training. Furthermore, we perform a detailed behavioral analysis of the identified safety-critical attention heads, revealing notable differences in the functions and behaviors of safety heads across different model architectures. These findings provide a novel mechanistic perspective for understanding and interpreting jailbreak behaviors in LLMs, offering both theoretical insights and practical implications for improving model safety.
From Spark to Fire: Modeling and Mitigating Error Cascades in LLM-Based Multi-Agent Collaboration
Mar 04, 2026Large Language Model-based Multi-Agent Systems (LLM-MAS) are increasingly applied to complex collaborative scenarios. However, their collaborative mechanisms may cause minor inaccuracies to gradually solidify into system-level false consensus through iteration. Such risks are difficult to trace since errors can propagate and amplify through message dependencies. Existing protections often rely on single-agent validation or require modifications to the collaboration architecture, which can weaken effective information flow and may not align with natural collaboration processes in real tasks. To address this, we propose a propagation dynamics model tailored for LLM-MAS that abstracts collaboration as a directed dependency graph and provides an early-stage risk criterion to characterize amplification risk. Through experiments on six mainstream frameworks, we identify three vulnerability classes: cascade amplification, topological sensitivity, and consensus inertia. We further instantiate an attack where injecting just a single atomic error seed leads to widespread failure. In response, we introduce a genealogy-graph-based governance layer, implemented as a message-layer plugin, that suppresses both endogenous and exogenous error amplification without altering the collaboration architecture. Experiments show that this approach raises the defense success rate from a baseline of 0.32 to over 0.89 and significantly mitigates the cascading spread of minor errors.
Can LLMs See Without Pixels? Benchmarking Spatial Intelligence from Textual Descriptions
Jan 07, 2026Recent advancements in Spatial Intelligence (SI) have predominantly relied on Vision-Language Models (VLMs), yet a critical question remains: does spatial understanding originate from visual encoders or the fundamental reasoning backbone? Inspired by this question, we introduce SiT-Bench, a novel benchmark designed to evaluate the SI performance of Large Language Models (LLMs) without pixel-level input, comprises over 3,800 expert-annotated items across five primary categories and 17 subtasks, ranging from egocentric navigation and perspective transformation to fine-grained robotic manipulation. By converting single/multi-view scenes into high-fidelity, coordinate-aware textual descriptions, we challenge LLMs to perform symbolic textual reasoning rather than visual pattern matching. Evaluation results of state-of-the-art (SOTA) LLMs reveals that while models achieve proficiency in localized semantic tasks, a significant "spatial gap" remains in global consistency. Notably, we find that explicit spatial reasoning significantly boosts performance, suggesting that LLMs possess latent world-modeling potential. Our proposed dataset SiT-Bench serves as a foundational resource to foster the development of spatially-grounded LLM backbones for future VLMs and embodied agents. Our code and benchmark will be released at https://github.com/binisalegend/SiT-Bench .
Beyond Flatlands: Unlocking Spatial Intelligence by Decoupling 3D Reasoning from Numerical Regression
Nov 18, 2025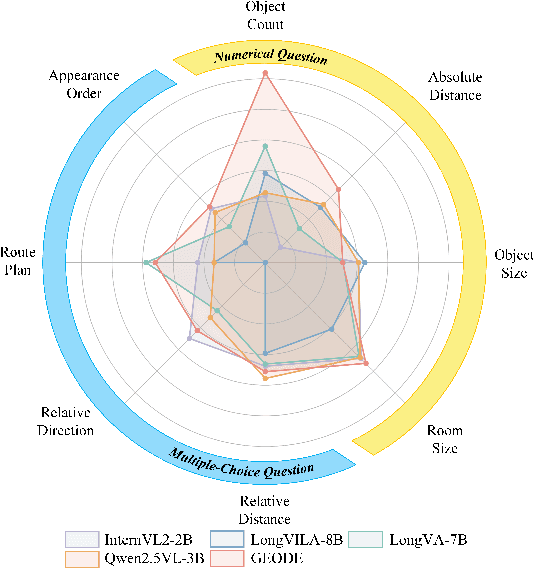
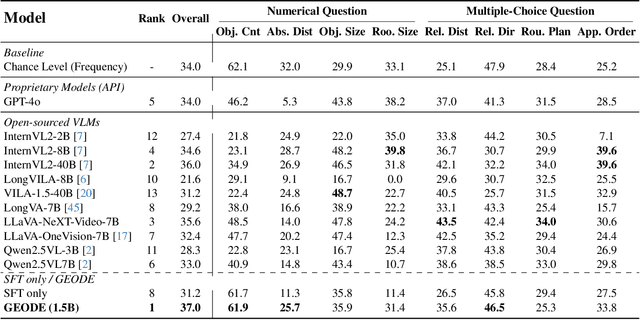
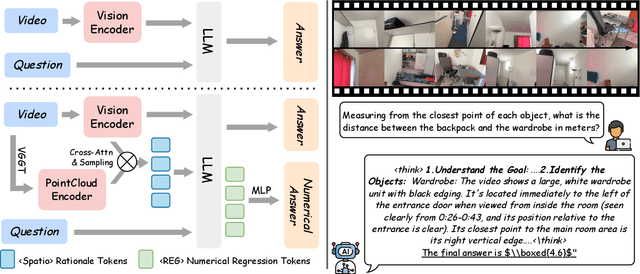
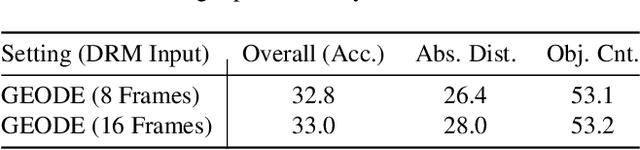
Existing Vision Language Models (VLMs) architecturally rooted in "flatland" perception, fundamentally struggle to comprehend real-world 3D spatial intelligence. This failure stems from a dual-bottleneck: input-stage conflict between computationally exorbitant geometric-aware encoders and superficial 2D-only features, and output-stage misalignment where discrete tokenizers are structurally incapable of producing precise, continuous numerical values. To break this impasse, we introduce GEODE (Geometric-Output and Decoupled-Input Engine), a novel architecture that resolves this dual-bottleneck by decoupling 3D reasoning from numerical generation. GEODE augments main VLM with two specialized, plug-and-play modules: Decoupled Rationale Module (DRM) that acts as spatial co-processor, aligning explicit 3D data with 2D visual features via cross-attention and distilling spatial Chain-of-Thought (CoT) logic into injectable Rationale Tokens; and Direct Regression Head (DRH), an "Embedding-as-Value" paradigm which routes specialized control tokens to a lightweight MLP for precise, continuous regression of scalars and 3D bounding boxes. The synergy of these modules allows our 1.5B parameter model to function as a high-level semantic dispatcher, achieving state-of-the-art spatial reasoning performance that rivals 7B+ models.
Stroke Modeling Enables Vectorized Character Generation with Large Vectorized Glyph Model
Nov 14, 2025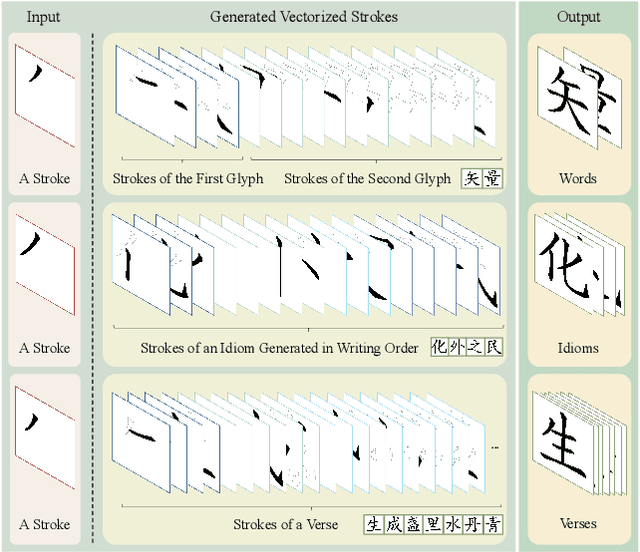
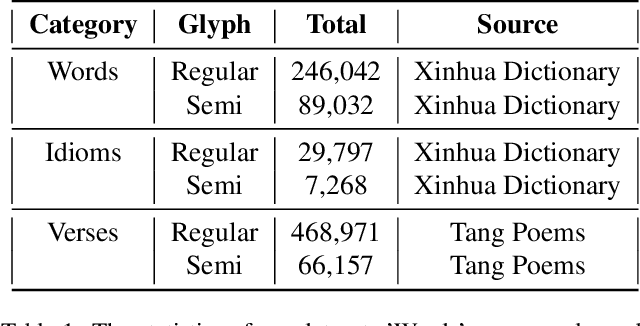
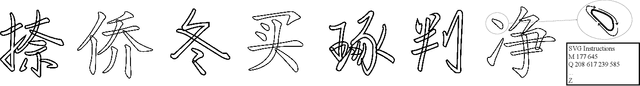
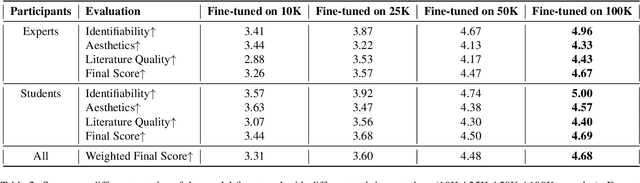
Vectorized glyphs are widely used in poster design, network animation, art display, and various other fields due to their scalability and flexibility. In typography, they are often seen as special sequences composed of ordered strokes. This concept extends to the token sequence prediction abilities of large language models (LLMs), enabling vectorized character generation through stroke modeling. In this paper, we propose a novel Large Vectorized Glyph Model (LVGM) designed to generate vectorized Chinese glyphs by predicting the next stroke. Initially, we encode strokes into discrete latent variables called stroke embeddings. Subsequently, we train our LVGM via fine-tuning DeepSeek LLM by predicting the next stroke embedding. With limited strokes given, it can generate complete characters, semantically elegant words, and even unseen verses in vectorized form. Moreover, we release a new large-scale Chinese SVG dataset containing 907,267 samples based on strokes for dynamically vectorized glyph generation. Experimental results show that our model has scaling behaviors on data scales. Our generated vectorized glyphs have been validated by experts and relevant individuals.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
Semantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.