 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Understanding between People and Systems via Neurosymbolic AI and Knowledge Graphs
Apr 15, 2025This chapter investigates the concept of mutual understanding between humans and systems, positing that Neuro-symbolic Artificial Intelligence (NeSy AI) methods can significantly enhance this mutual understanding by leveraging explicit symbolic knowledge representations with data-driven learning models. We start by introducing three critical dimensions to characterize mutual understanding: sharing knowledge, exchanging knowledge, and governing knowledge. Sharing knowledge involves aligning the conceptual models of different agents to enable a shared understanding of the domain of interest. Exchanging knowledge relates to ensuring the effective and accurate communication between agents. Governing knowledge concerns establishing rules and processes to regulate the interaction between agents. Then, we present several different use case scenarios that demonstrate the application of NeSy AI and Knowledge Graphs to aid meaningful exchanges between human, artificial, and robotic agents. These scenarios highlight both the potential and the challenges of combining top-down symbolic reasoning with bottom-up neural learning, guiding the discussion of the coverage provided by current solutions along the dimensions of sharing, exchanging, and governing knowledge. Concurrently, this analysis facilitates the identification of gaps and less developed aspects in mutual understanding to address in future research.
Procedural Knowledge Ontology (PKO)
Mar 26, 2025Processes, workflows and guidelines are core to ensure the correct functioning of industrial companies: for the successful operations of factory lines, machinery or services, often industry operators rely on their past experience and know-how. The effect is that this Procedural Knowledge (PK) remains tacit and, as such, difficult to exploit efficiently and effectively. This paper presents PKO, the Procedural Knowledge Ontology, which enables the explicit modeling of procedures and their executions, by reusing and extending existing ontologies. PKO is built on requirements collected from three heterogeneous industrial use cases and can be exploited by any AI and data-driven tools that rely on a shared and interoperable representation to support the governance of PK throughout its life cycle. We describe its structure and design methodology, and outline its relevance, quality, and impact by discussing applications leveraging PKO for PK elicitation and exploitation.
Semantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
Human Evaluation of Procedural Knowledge Graph Extraction from Text with Large Language Models
Nov 27, 2024



Procedural Knowledge is the know-how expressed in the form of sequences of steps needed to perform some tasks. Procedures are usually described by means of natural language texts, such as recipes or maintenance manuals, possibly spread across different documents and systems, and their interpretation and subsequent execution is often left to the reader. Representing such procedures in a Knowledge Graph (KG) can be the basis to build digital tools to support those users who need to apply or execute them. In this paper, we leverage Large Language Model (LLM) capabilities and propose a prompt engineering approach to extract steps, actions, objects, equipment and temporal information from a textual procedure, in order to populate a Procedural KG according to a pre-defined ontology. We evaluate the KG extraction results by means of a user study, in order to qualitatively and quantitatively assess the perceived quality and usefulness of the LLM-extracted procedural knowledge. We show that LLMs can produce outputs of acceptable quality and we assess the subjective perception of AI by human evaluators.
The Time Traveler's Guide to Semantic Web Research: Analyzing Fictitious Research Themes in the ESWC "Next 20 Years" Track
Sep 25, 2023



What will Semantic Web research focus on in 20 years from now? We asked this question to the community and collected their visions in the "Next 20 years" track of ESWC 2023. We challenged the participants to submit "future" research papers, as if they were submitting to the 2043 edition of the conference. The submissions - entirely fictitious - were expected to be full scientific papers, with research questions, state of the art references, experimental results and future work, with the goal to get an idea of the research agenda for the late 2040s and early 2050s. We received ten submissions, eight of which were accepted for presentation at the conference, that mixed serious ideas of potential future research themes and discussion topics with some fun and irony. In this paper, we intend to provide a survey of those "science fiction" papers, considering the emerging research themes and topics, analysing the research methods applied by the authors in these very special submissions, and investigating also the most fictitious parts (e.g., neologisms, fabricated references). Our goal is twofold: on the one hand, we investigate what this special track tells us about the Semantic Web community and, on the other hand, we aim at getting some insights on future research practices and directions.
Modelling Business Agreements in the Multimodal Transportation Domain through Ontological Smart Contracts
Sep 05, 2022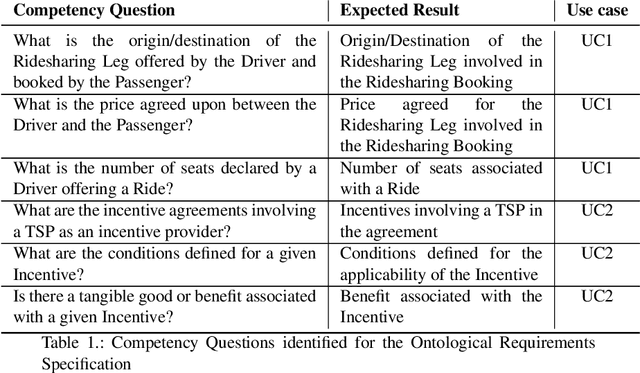

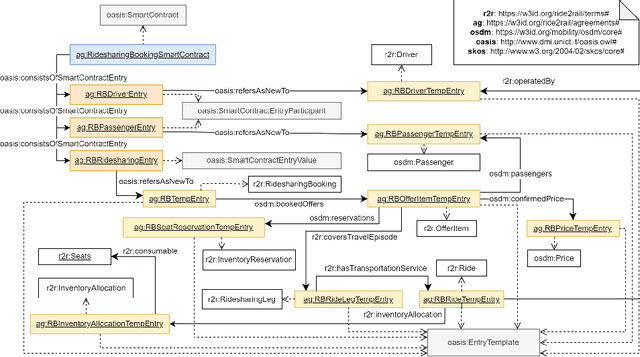
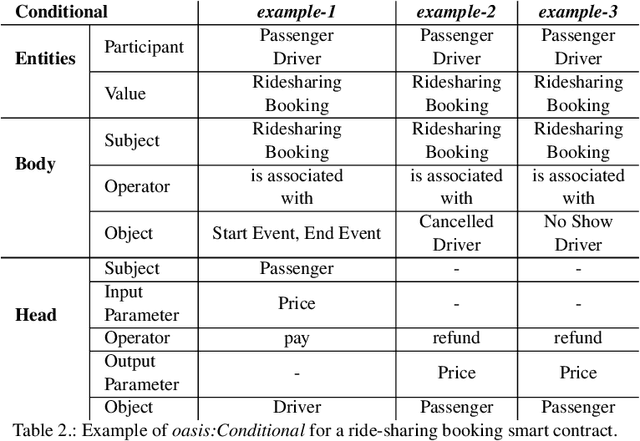
The blockchain technology provides integrity and reliability of the information, thus offering a suitable solution to guarantee trustability in a multi-stakeholder scenario that involves actors defining business agreements. The Ride2Rail project investigated the use of the blockchain to record as smart contracts the agreements between different stakeholders defined in a multimodal transportation domain. Modelling an ontology to represent the smart contracts enables the possibility of having a machine-readable and interoperable representation of the agreements. On one hand, the underlying blockchain ensures trust in the execution of the contracts, on the other hand, their ontological representation facilitates the retrieval of information within the ecosystem. The paper describes the development of the Ride2Rail Ontology for Agreements to showcase how the concept of an ontological smart contract, defined in the OASIS ontology, can be applied to a specific domain. The usage of the designed ontology is discussed by describing the modelling as ontological smart contracts of business agreements defined in a ride-sharing scenario.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020
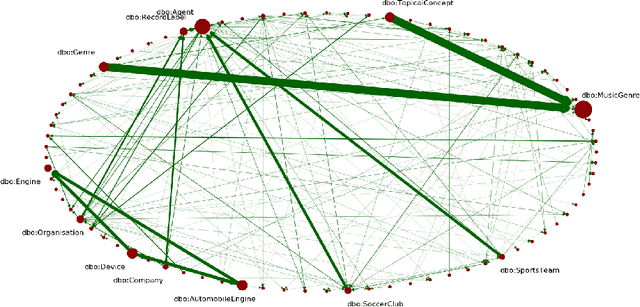

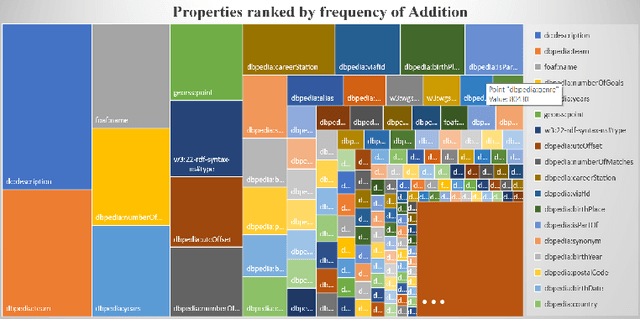
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
Turning Transport Data to Comply with EU Standards while Enabling a Multimodal Transport Knowledge Graph
Nov 12, 2020
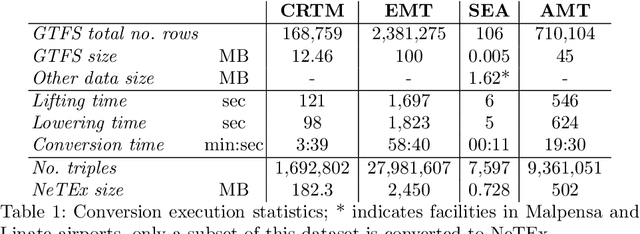
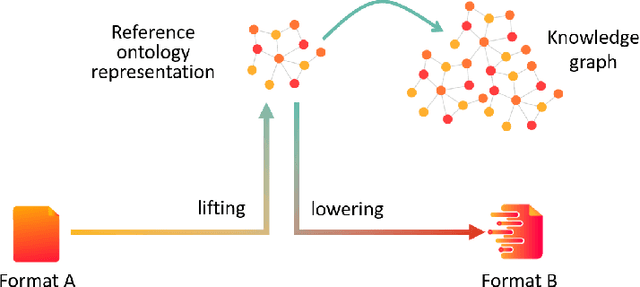
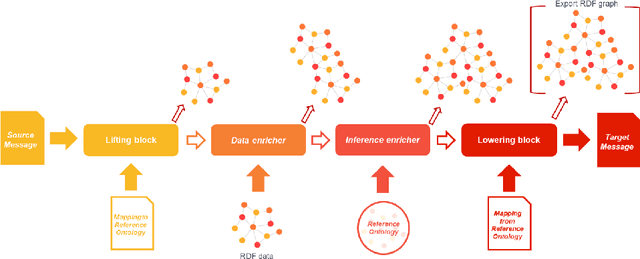
Complying with the EU Regulation on multimodal transportation services requires sharing data on the National Access Points in one of the standards (e.g., NeTEx and SIRI) indicated by the European Commission. These standards are complex and of limited practical adoption. This means that datasets are natively expressed in other formats and require a data translation process for full compliance. This paper describes the solution to turn the authoritative data of three different transport stakeholders from Italy and Spain into a format compliant with EU standards by means of Semantic Web technologies. Our solution addresses the challenge and also contributes to build a multi-modal transport Knowledge Graph of interlinked and interoperable information that enables intelligent querying and exploration, as well as facilitates the design of added-value services.
Who is this Explanation for? Human Intelligence and Knowledge Graphs for eXplainable AI
May 27, 2020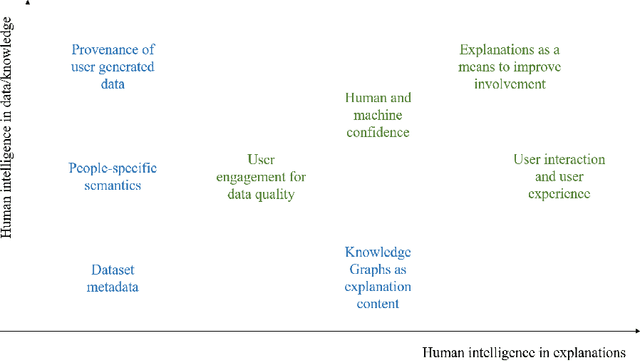
eXplainable AI focuses on generating explanations for the output of an AI algorithm to a user, usually a decision-maker. Such user needs to interpret the AI system in order to decide whether to trust the machine outcome. When addressing this challenge, therefore, proper attention should be given to produce explanations that are interpretable by the target community of users. In this chapter, we claim for the need to better investigate what constitutes a human explanation, i.e. a justification of the machine behaviour that is interpretable and actionable by the human decision makers. In particular, we focus on the contributions that Human Intelligence can bring to eXplainable AI, especially in conjunction with the exploitation of Knowledge Graphs. Indeed, we call for a better interplay between Knowledge Representation and Reasoning, Social Sciences, Human Computation and Human-Machine Cooperation research -- as already explored in other AI branches -- in order to support the goal of eXplainable AI with the adoption of a Human-in-the-Loop approach.
* 10 pages, 1 figure, book chapter